
浅谈Redis Sentinel
Redis 2.8版本开始提供了新一代Sentinel,即所谓的「Sentinel 2」。其大大增强、保障了Redis的高可用

监控主从拓扑结构
众所周知在Sentinel的配置文件中,需要配置被监控的Master节点的地址信息(IP、Port)。这样当一个Sentinel实例在被创建、初始化时,即会建立其与Mater节点的网络连接。一个是命令连接,另一个则是订阅连接。前者用于发送命令并接收回复;后者则专门用于订阅Master节点的 「__sentinel__:hello」 频道
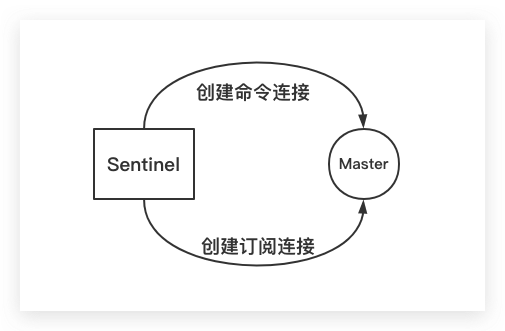
Sentinel默认每隔10s通过命令连接向其正在监控的Master节点发送「INFO」命令,然后其通过分析Master节点回复的结果。Sentinel一方面可以获得该Master节点的相关信息;另一方面还可以获得该Master节点的Slave节点信息。这也是为什么Sentinel的配置文件中只需配置Master节点的地址信息,而无需配置Slave节点的地址信息,即所谓的自动发现
类似地,当Sentinel发现了Master节点下的Slave节点后,同样会分别创建两个网络连接(命令连接、订阅连接)到各Slave节点,如下图所示。其中,订阅连接专门用于订阅各Slave节点的 「__sentinel__:hello」 频道。同理,Sentinel也会通过命令连接以每隔10s的频率向各Slave节点发送「INFO」命令,以获取Salve节点等相关信息
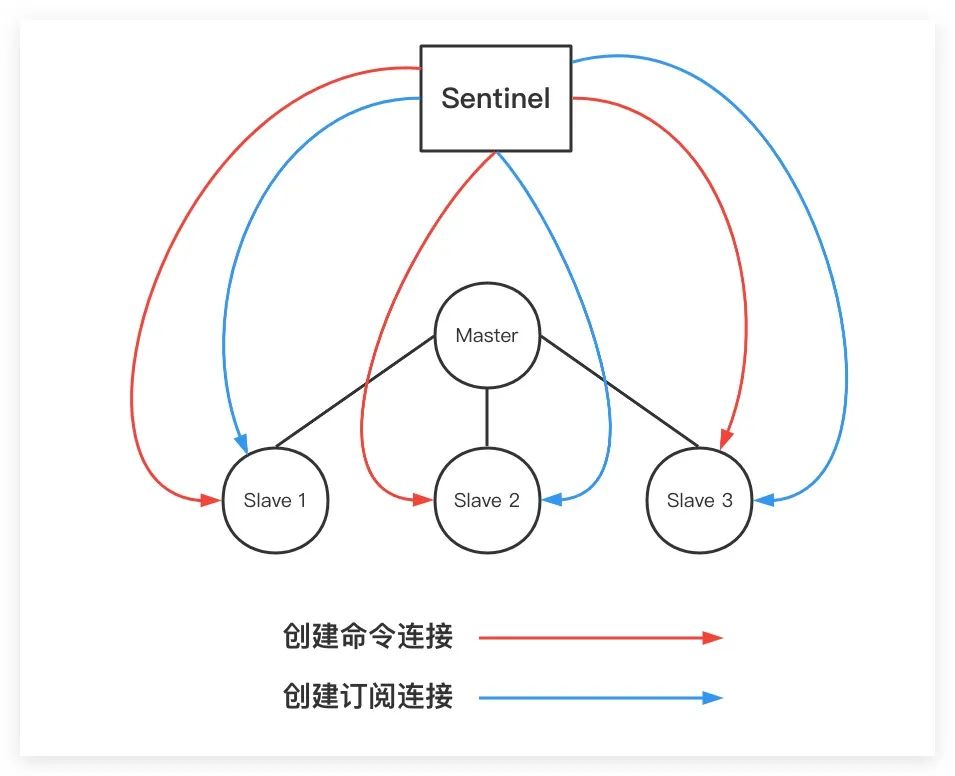
综上所述,Sentinel通过命令连接向Master、Slave节点发送「INFO」命令实现了对主从拓扑结构的监控、维护
建立Sentinel间网络
与此同时各Sentinel默认以每隔2s的频率通过命令连接向所有其正在监视的Master/Slave节点发送「PUBLISH命令」,该命令会向Master/Slave节点的 「__sentinel__:hello」 频道发送一条信息。其包含两部分内容,一部分为该Sentinel自身的IP、Port等信息;另一部分则为Master节点信息,具体地,如果该Sentinel监视的为Master节点,则即为该Master节点信息;如果该Sentinel监视的为Slave节点,则即为该Slave节点所对应的Master信息
前面提到Sentinel会与Master/Slave节点建立订阅连接,然后Sentinel就会通过该订阅连接向Master/Slave节点发送SUBSCRIBE命令,以实现对 「__sentinel__:hello」 频道的订阅。这样一个Sentinel实例就可以基于上述机制,实现对其他Sentinel实例的自动发现。如下图所示
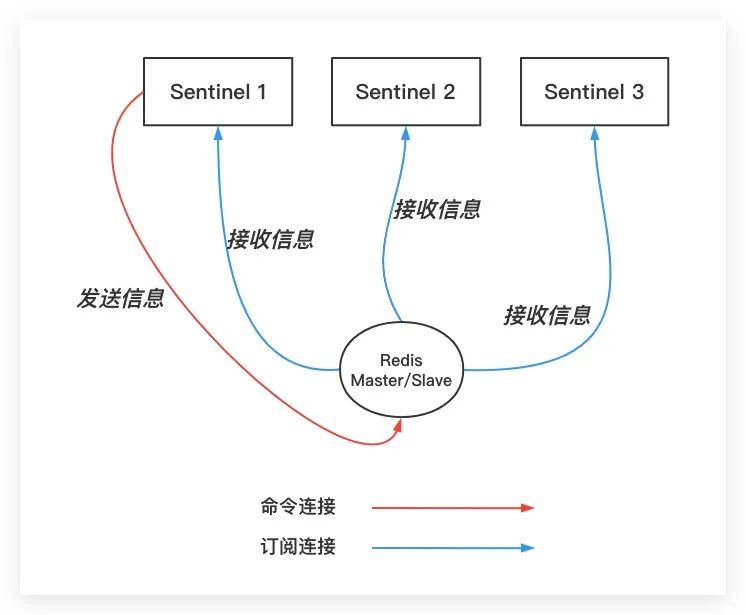
至此,各Sentinel实例之间会相互建立网络连接。但值得一提的是,Sentinel实例之间只会建立命令连接,而不会建立订阅连接
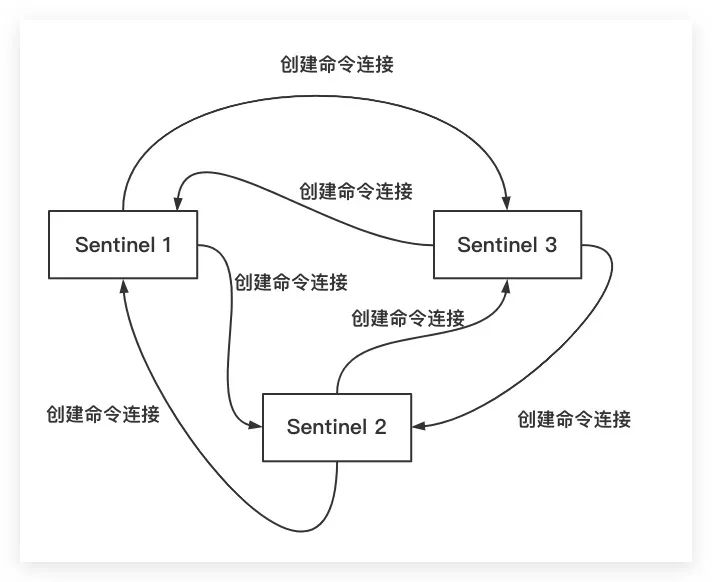
综上所述,Sentinel通过 「__sentinel__:hello」 频道利用发布/订阅机制实现了对Sentinel实例间的网络维护、信息交换
心跳检测机制
各Sentinel实例默认会以每隔1s的频率向所有与其创建了命令连接的实例(包括Mater节点、Slave节点、其他Sentinel实例)发送「PING命令」,根据实例返回的对PING命令的回复来判断实例是否在线。而实例对PING命令的回复可分为两种,具体地:
- 「有效回复」:实例返回+PONG、-LOADING、-MASTERDOWN三种回复的其中一种
- 「无效回复」:实例返回除+PONG、-LOADING、-MASTERDOWN三种回复之外的其他回复,或者在指定时限内没有返回任何回复
Subjectively Down 主观下线
前面提到Sentinel会向其他实例发送PING命令进行心跳检测,而如果在指定时间内该Sentinel未收到相应实例的有效回复。则该Sentinel即会主观认为该实例已经下线,即所谓的「Subjectively Down」主观下线(简称「SDOWN」)。具体地,该指定时间可通过Sentinel配置文件的down-after-milliseconds选项进行设置
Objectively Down 客观下线
当一个Sentinel判断Master节点发生主观下线后,为了进一步确认该Master是否真的下线了。其会向同样监视该Master节点的其他Sentinel实例进行询问。具体地,通过向其他Sentinel实例发送 SENTINEL is-master-down-by-addr 命令并收集相应的回复。当认为该Master节点已经下线的Sentinel实例总数(自然也包括当前Sentinel实例)达到Sentinel配置文件的「quorum」选项时,当前Sentinel即会认为该Master节点客观上已经下线,即所谓的「Objectively Down」客观下线(简称「ODOWN」)
例如,对于某Sentinel实例而言,其监视的Master节点时使用的配置文件如下所示。当该Sentinel判定该Master节点主观下线后,会询问其他正在监视该Master节点的Sentinel实例。当发现有3个其他Sentinel实例也认为该Master节点已经下线了,则此时该Sentinel实例即会认为该Master节点进入客观下线。因为加上其自身共计存在4个Sentinel实例认为该Master节点下线了,已经达到其配置文件的quorum配置值4的要求了
# 该Sentinel实例监视一个名为myMaster的Master节点
# 其中,该Master节点的IP、Port分别为127.0.0.1、6379
# 其中,quorum配置为4
sentinel monitor myMaster 127.0.0.1 6379 4
这里需要补充说明的是,Sentinel仅会对Master节点进行主观、客观下线的判断。而对于Slave节点、其他Sentinel实例而言,只会进行主观下线的判断
选举 Sentinel Leader
一旦发生了客观下线,那么各Sentinel实例之间就需要通过投票的方式选举出一个Leader来开展、完成后续的故障转移工作。具体则是通过Raft算法来实现选举。这里需要强调的是在进行投票的过程中,一个Sentinel实例的票数需要大于等于 Max( quorum, floor(SentinelNum/2)+1 ) ,其才会成为本次选举的Leader
例如在一个含有11个Sentinel实例的Sentinel集群中,如果某Sentinel实例A的quorum配置值为2,则其需要拿到6票就可以成为Leader,详细计算过程如下所示
Max(2, floor(11/2)+1) = Math(2, 5+1) = Max(2,6) = 6
而如果另外一个Sentinel实例B的的quorum配置值为8,则其需要拿到8票才可以成为Leader,详细计算过程如下所示
Max(8, floor(11/2)+1) = Math(8, 5+1) = Max(8,6) = 8
至此,对于Sentinel配置文件的quorum配置项来说。其具有两个作用,一方面用于该Sentinel实例判断Master节点发生主观下线的条件;另一方面,其决定了该Sentinel实例在投票选举期间成为Leader时所需票数的上限。因为即使quorum配置再低,比如上文的Sentinel实例A。其最终所需票数也需要达到半数以上才可以成为Leader
这里做一点补充说明,以解释为什么Reids官方推荐Sentinel集群中至少应该含三个Sentinel实例。为了行文简洁,这里我先将Sentinel集群中允许Sentinel宕机的数量称为容错性
- 如果Sentinel集群中只有1个实例,则显然容错性为0
- 如果Sentinel集群中只有2个实例,即使将quorum配置为1,但半数以上的投票数也是2。故其容错性同样为0。因为当其中一个实例发生意外宕机后,剩余的另外一个实例由于无法获取半数以上的投票,故无法在选举过程成为Leader。这样一旦Master节点发生意外,同样无法进行故障转移
- 如果Sentinel集群中有3个实例,即使将quorum配置为1,但半数以上的投票数同样是2。故其容错性为1。即使一个实例宕机,剩余实例依然可以顺利进行Leader选举
- 如果Sentinel集群中有4个实例,即使将quorum配置为1,但半数以上的投票数是3。同理,其容错性仍然是1
- 如果Sentinel集群中有5个实例,半数以上的投票数是3。其容错性为2
- 如果Sentinel集群中有6个实例,半数以上的投票数是4。其容错性仍然是2
事实上,通过上面的分析。相信大家已经理解为什么在HA高可用架构下Sentinel集群中至少应该存在3个Sentinel实例。进一步,从容错性的角度来看,奇数台Sentinel实例与偶数台Sentinel实例的容错能力完全一样。比如3台与4台的容错性均为2。故从节约硬件成本的角度考虑,一般会使用奇数台实例
Failover 故障转移
在选举出Sentinel Leader后,Sentinel Leader就需要进行真正的Failover故障转移了。其基本流程如下
- 从已经下线的Master节点所属的所有Slave节点中,挑选一个Slave节点作为新的主节点
- 让已经下线的Master节点所属的所有Slave节点,指向新的主节点。即从新的主节点进行复制
- 将已经下线的Master节点设置为新主节点的从节点。这样当这个已经下线的Master节点后续重新上线时,其就会成为新主节点的从节点。以避免同时出现两个主节点的情形
这里对Sentinel Leader从Slave节点中选择新主节点的方法,作进一步说明。其在选择过程中考虑了以下因素:
- Slave节点不能处于下线、断线的状态
- Slave节点与Master节点断开连接的时长
- Slave节点处理复制的偏移量replication offset
- Slave节点的优先级。优先级小的Slave节点会比优先级大的Slave节点优先选中。特别地,对于优先级为0的Slave节点,则其永远不会选中。具体地,可通过Slave节点的redis.conf配置文件中replica-priority配置项进行设置
- Redis设计与实现 黄健宏著