
致敬CondConv!Intel提出即插即用的“万金油”动态卷积ODConv
共 3628字,需浏览 8分钟
·
2022-02-22 14:40
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
导读
本文介绍了一篇动态卷积的工作:ODConv,其通过并行策略采用多维注意力机制沿核空间的四个维度学习互补性注意力。作为一种“即插即用”的操作,它可以轻易的嵌入到现有CNN网络中。并且实验结果表明它可提升大模型的性能,又可提升轻量型模型的性能,实乃万金油是也!

论文链接:https://openreview.net/forum?id=DmpCfq6Mg39
ICLR2022前段时间已经放榜,涌现了大量优秀的工作。笔者在浏览时偶然发现一篇关于动态卷积的文章ODConv(Omni-dimensional Dynamic Convolution, ODConv),Intel实验室姚安邦:https://yaoanbang.github.io/团队的工作。作为一种“即插即用”的操作,还是非常值得一读的,故做记录以飨各位。
动态卷积这几年研究的非常多了,比较知名的有谷歌的CondConv,旷视科技的WeightNet、MSRA的DynamicConv、华为的DyNet、商汤的CARAFE等。笔者曾经也对相关paper进行过解读,各个动态卷积之间的差异性也曾进行深入分析。
高性能涨点的动态卷积 DyNet 与 CondConv、DynamicConv 有什么区别联系?
一定程度上讲,ODConv可以视作CondConv的延续,将CondConv中一个维度上的动态特性进行了扩展,同时了考虑了空域、输入通道、输出通道等维度上的动态性,故称之为全维度动态卷积。ODConv通过并行策略采用多维注意力机制沿核空间的四个维度学习互补性注意力。作为一种“即插即用”的操作,它可以轻易的嵌入到现有CNN网络中。ImageNet分类与COCO检测任务上的实验验证了所提ODConv的优异性:即可提升大模型的性能,又可提升轻量型模型的性能,实乃万金油是也!值得一提的是,受益于其改进的特征提取能力,ODConv搭配一个卷积核时仍可取得与现有多核动态卷积相当甚至更优的性能。
Backgroud
在正式介绍ODConv之前,我们首先对现有动态卷积进行回顾,然后再对ODConv进行描述,说明其特性与实现细节。
常规卷积只有一个静态卷积核且与输入样本无关。对于动态卷积来说,它对多个卷积核进行线性加权,而加权值则与输入有关,这就使得动态卷积具有输入依赖性。它可以描述如下:
尽管动态卷积的定义很简单,但CondConv与DyConv的实现是不相同的,主要体现在计算的结构、训练策略以及实施动态卷积的层,这些实现上的差异导致了不同的模型精度、模型大小以及推理效率。
两者均为采用了类SE架构,但CondConv采用的是Sigmoid,而DyConv采用的是Softmax; DyConv采用的退化策略进行训练以抑制Softmax的one-hot输出; 对于他们嵌入的CNN架构,CondConv替换了最后几个模块的卷积与全连接层,而DyConv则对除第一个卷积外的其他卷积均进行了替换。
根据动态卷积的公式来看,动态卷积有两个基本元素:
卷积核; 用于计算注意力的注意力函数
给定n个卷积核,其对应的核空间有以下四个维度:
空间核尺寸; 输入通道数 输出通道数 卷积核数量n
然而,对于CondConv与DyConv来说,均采用单个注意力标量,这就意味着它的的输出滤波器对于输入具有相同的注意力值。换句话说,卷积核 的空间维度、输入通道维度以及输出通道维度均被CondConv与DyConv所忽视了。这就导致了关于核空间的粗糙探索。这可能就是为什么CondConv与DyConv对于大网络的性能增益较低的原因。
此外,相比常规卷积,动态卷积的卷积核参数往往是其n倍。比如CondConv中的n=8,DyConv中的n=4。当动态卷积使用过多时无疑会极大程度提升模型大小。我们发现:当 移除掉CondConv/DyConv中的注意力机制(即)后,其性能提升接近于零。比如,对于ResNet18,其性能增益从1.78%/2.51%下降到了0.08%/0.14。
上述发现意味着:动态卷积中的注意力机制起关键性作用,更有效的设计也许可以在模型精度与大小之间得到更好的平衡。
ODConv

基于前述讨论,ODConv通过并行策略引入一种多维注意力机制以对卷积核空间的四个维度学习更灵活的注意力。上图给出CondConv、DyConv以及ODConv的差异图。
延续动态卷积的定义,ODConv可以描述成如下形式:
其中,表示卷积核的注意力标量,表示新引入的三个注意力,分别沿空域维度、输入通道维度以及输出通道维度。这四个注意力采用多头注意力模块计算得到。

在ODConv中,对于卷积核,对空域位置上的卷积参数赋予不用的注意力值,见上图a;对不同输入通道的卷积滤波器赋予不同的注意力值,见上图b;对不同输出通道的卷积滤波器赋予不同的注意力值,见上图c;而则对n个整体卷积核赋予不同的值,见上图d。
原则上来讲,这四种类型的注意力是互补的,通过渐进式对卷积沿位置、通道、滤波器以及核等维度乘以不同的注意力将使得卷积操作对于输入存在各个维度的差异性,提供更好的性能以捕获丰富上下文信息。因此,ODCOnv可以大幅提升卷积的特征提取能力;更重要的是,采用更少卷积核的ODConv可以取得与CondConv、DyConv相当甚至更优的性能。
对比前面两种动态卷积的公式可以发现:ODConv是一种更广义的动态卷积。此外,当设置时,ODConv则退化为仅具有滤波器层面的注意力,基于输入对卷积滤波器进行调制后再进行卷积,类似于SE。故SE是ODConv的一个特例。

那么如何实现ODConv的四种类型的注意力值呢?延续CondConv与DyConv,我们同样采用SE风格的注意力模块,但使其具有多个头以计算多种类型注意力,整体结构见上图。具体来说,对于输入先通过GAP收缩为长度为的特征向量,然后采用FC与四个头生成不同类型的注意力值。对于四个头,其维度分别为。
在训练方面,我们采用了DyConv中的退化策略以加速训练。在具体架构嵌入方面,我们参考DyConv对除第一个卷积外的其他所有卷积进行替换。
Experiments
在对标骨干方面,我们选用了MobileNetV2与ResNet系列;在对标动态卷积方面,我们选择了CondConv、DyConv以及DCD。此外,我们还对标了不同的注意力,比如SE、CBAM、ECA、WE、CGC以及WeightNet。
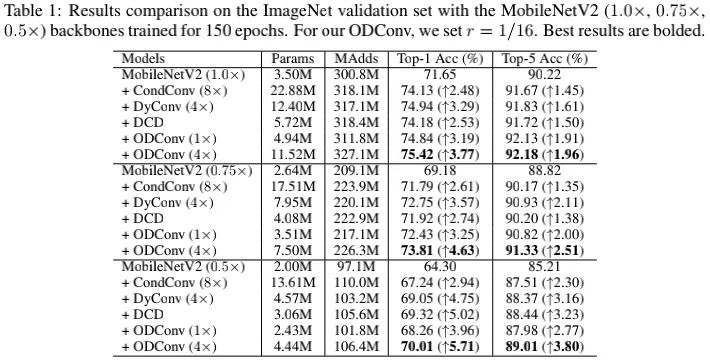
上表给出了以MobileNetV2为基础架构不同方案的性能对比,从中可以看到:
采用的单个卷积核的ODConv取得比8个卷积核的CondCOnv更佳的性能,同时具有与4个卷积核的DyConv相当的性能,而ODConv的参数量远小于DyConv。这说明:ODConv可以提供更好的精度与模型大小均衡; 相比DCD,采用单个卷积核的ODConv同样取得了更佳的性能; 采用4个卷积核的ODConv则进一步取得了性能提升。

上表给出了以ResNet为基础架构不同方案的性能对比,从中可以看到:
当采用ResNet18作为基础骨干时,动态卷积具有比注意力更佳的性能,而ODConv的性能比其他动态卷积还要优秀,最高性能提升达3.72%; 当采用ResNet50作为基础骨干时,CondConv、DyConv以及DCD反而比注意力机制的性能更低,而ODConv仍可以取得比注意力机制更佳的性能; 当以ResNet101作为基础骨干时,ODConv仍具有非常好的性能,且比注意力机制更优。
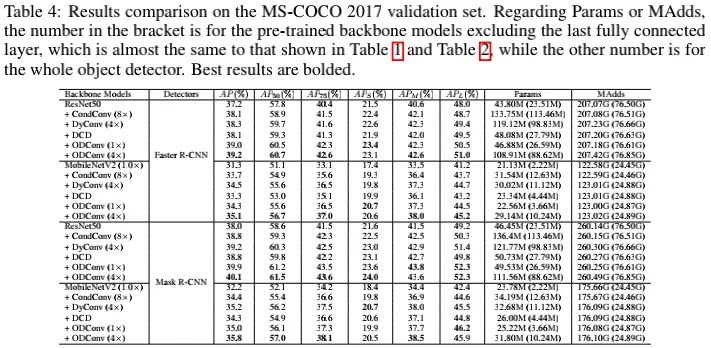
上表给出了COCO检测任务上的性能对比,从中可以看到:ODConv再次取得了比其他动态卷积更优的性能。
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、NeRF、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
