
「后隐私」时代,个性化广告如何保护隐私?
总览
在广告领域,「个性化」和「隐私」似乎是天平的两端:个性化做的很好的广告,通常都要收集很多用户数据,对用户画像有清晰的认识;而如果将用户数据都屏蔽掉,个性化的广告很难取得效果。
随着 Apple 公司发布 iOS 14,隐私问题也越来越受到大家关注,隐私保护越来越受到重视。在这种背景下,我们要做的是「乘势而为」,本文就「后隐私」时代,个性化广告该何去何从进行讨论。从技术角度分析,内容包括:
分析个性化广告和隐私的关系(原理); 隐私问题的本质 如何保护隐私 Web 间 App 间 在隐私保护的情况下,个性化广告有哪些出路。 目前各大厂商的思路 Apple: SKAN/PCM Google: Privacy Sandbox (FLoC) Facebook: AEM 第一方落地页
广告和隐私的关系
广告并不是一开始就和隐私有关系的,而是随着时代的发展,广告平台对于变现效率不断提出了更高的要求,云计算、大数据、机器学习等前沿技术的应用也越来越多,对于数据的收集、运算和应用的规模也在逐步地扩大。我们把广告精准性的深入程度由浅入深的划分了几个阶段:
(图片来源:人人都是产品经理[1])
通过媒介定向
这是传统媒体阶段,通过 媒体属性的差异 来定向的投放广告,比如体育频道的受众更多是体育爱好者、北京西二旗地铁站的广告受众更多的是互联网公司的从业者、海淀黄庄地铁站的受众则是课外辅导班的家长们。
通过内容定向
2000 年左右的第一波互联网浪潮,最早的门户网站比如新浪、搜狐上线,计费模式比较多的是 CPT 或者 GD 广告。以 内容为意图的 定向精准度相比于线下媒体更高了一些,比如小说频道和综艺频道的浏览者是不同的。
通过意图定向
随着 Google 和百度搜索上线,以 搜索意图 为广告定向相比于以内容定向要精准得多了,计费模式更多的是 CPC 或者 CPM。当然这些就更多的依赖了用户信息的收集(搜索内容、历史、相关性)等。
通过用户画像定向
当依赖于推荐引擎的信息流产品如今日头条、抖音上线,用户的偏好很大程度上决定了内容,这些产品通过各个渠道收集到的数据形成的 用户画像,再基于用户画像进行内容和广告的推送。计费模式多为 oCPX 或者 CPA。
随着对定向精准程度的逐步提升,广告对于用户数据的收集、计算和应用的程度也越来越高。用户隐私问题也越来越多地进入到用户视线中。
根本问题是什么?
从技术角度看,最根本的问题是用户标识,即 User ID。
为什么呢?因为一切数据、偏好的基础背后都是用户,我们需要根据一个 User ID 来「唯一」定义一名用户。
听起来「唯一」定义一名用户,比较简单,但是在没有登录的情况下,如何唯一的定义一名用户呢?
PC 时代
在 PC 的时代,前端意义上「唯一定义一名用户」是一个非常有意思的话题,即问题为:如何生成一个唯一的 User ID?
如果了解前端库如 fingerprintjs[2],你就会知道为了在前端生成碰撞率极低的指纹(User ID),用了多少用户维度的信息,比如 UserAgent、IP 地址、安装的字体、Canvas、安装的插件等等。
https://juejin.cn/post/6844903617510506504
移动时代
到了移动时代,除了 Web 之外,我们还多了 App 形态。在 Web 时代,前端能获取到的信息十分有限,而 App 则直接可以和系统甚至硬件进行交互,获取到的信息就多得多了。移动时代的 Android 和 iOS 系统甚至分别提供了唯一的设备标识符,都不用自己生成。
Android 可以使用 Android ID,iOS 则从 MAC 升级到 UDID 再到 IDFA,当然随着 iOS 14 的逐步覆盖提升,IDFA 获取到的难度大大增加(后文会解释)。
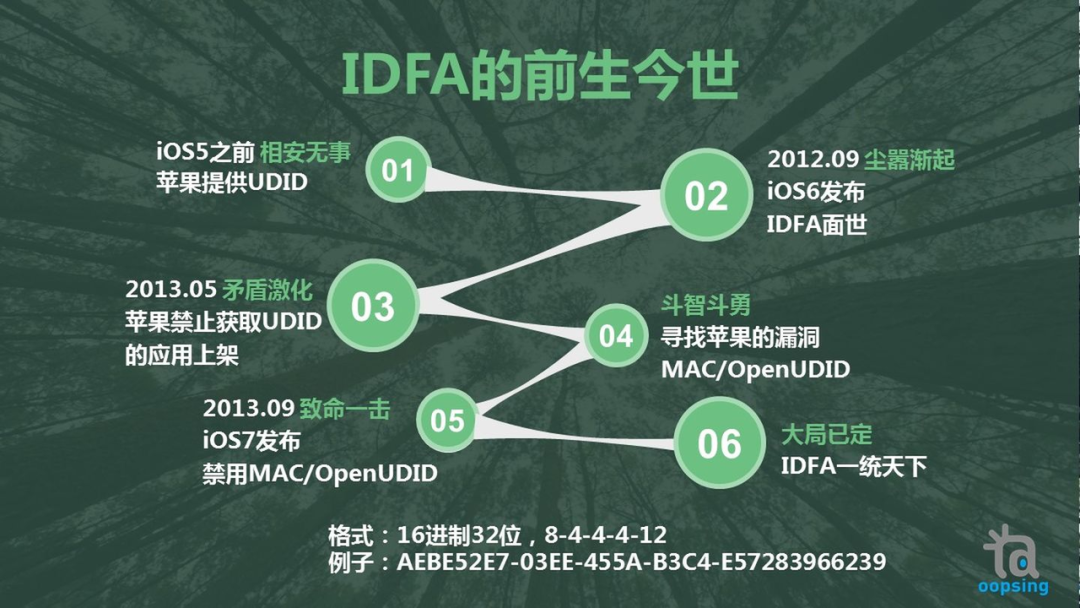
(图片来源:知乎[3])
有了 User ID 之后呢?
有了唯一的 User ID 之后,能做的事情就太多了:
单主体
Web 上:在同一家主体的网站中,用户即使不登录,也能很容易被持续跟踪。从技术角度看,只要生成了 User ID 后,将其保存至 cookie 中,随后所有和后端的交互,浏览器都会自动带上这个 cookie,后端根据 cookie 解出 User ID 后,那么这个用户访问过哪些页面、点击过哪些元素都可以被记录下来了。即使用户清除了 cookie,再次进入该网站时,由于生成的算法不变,那么 User ID 也是唯一的。
App 上:这个就更简单了,用户在打开 App 的那一刻开始,所有的行为,只要该 App 想记录,那么都可以被记录下来。
多主体
当然,如果到此为止,隐私问题倒还好,毕竟属于同一家主体,你去使用别人的服务,做了些什么事情、偏好什么的,别人自然最清楚不过了。
但是,在 Web 上,如果存在一个第三方主体,将其脚本置入到其他的主体的域下,使用同一个 User ID,保存在 cookie 中,那么这个第三方主体就可以获取到用户在其他主体下的所有的活动数据,这就给用户隐私保护带来很大的挑战。
在 App 上,由于可以很方便的获取到统一的 User ID,那么就可以跨 App 进行追踪了,甚至比 Web 还要方便。
显然,风险最高的就是跨主体的进行 User ID 共享,特别是在未获得用户授权甚至用户无感知的情况下。
如何保护用户隐私?
既然风险最高的是跨主体的 User ID 共享,那么防范的主要途径有两个:
User ID:变得难以获取; 共享:禁止跨主体的数据共享或匹配;
按照这两条指导原则,我们在 Web 和 App 分别来看看如何实现?
Web 间
让 user ID 难以获取
如上文所说,User ID (即浏览器指纹)的生成依赖浏览器或者其他可采集到的设备信息,利用的就是这些信息的不可变性,而随着隐私保护的理念逐步深入人心,主流的浏览器厂商都将「指纹保护」纳入到了浏览器隐私保护范围内。
比如:使用 Canvas 绘制图像,并转为 base64 的做法来做,由于每台机器的硬件性能、屏幕显示的不同,导致了这种方法很容易成为生成指纹的重要信息来源。比较常见的反制策略,在绘制 Canvas 图形的时候,加上一些随机的噪声数据,就让生成的信息就变得不唯一了。
这一技术在 Safari 和 Firefox 已经率先实现,如访问 Fingerprint 的 DEMO[4] 地址,我们对比一下 Safari 的普通模式和隐私模式的指纹。
Safari

(左:普通模式,右:隐私模式,Safari 版本 14.0.3)
可以看到,左右两个是不同的。另外,在测试过程中,刷新页面,生成的指纹还会发生变化(可能是 Safari 内部的机制),详见 Apple Safari 2019 隐私安全白皮书[5]。
Firefox

(左:普通模式,右:隐私模式,Firefox 87.0 (64 位))
可以看出,左右两个是相同的,受限于 Firefox 的指纹检测模式(是通过该网页是否有和主流的 提供 Fingerprint 服务的域名有通信,从而进行拦截,该项服务由 Disconnect[6] 提供),详见 Firefox 72 的发布说明[7]
Chrome

(左:普通模式,右:隐私模式,Chrome 版本 89.0.4389.90(正式版本))
可以看出,左右两个是相同的,目前还没有找到 Chrome 太多的关于指纹保护的公开资料,更多的是一些 Chrome 插件提供的能力。
禁止跨主体的数据共享或匹配
对于 Web 来说,「禁止跨主体的数据共享或者匹配」所依赖的载体就是 Cookie 了,准确来说,应该是第三方 Cookie。基本原理如下图: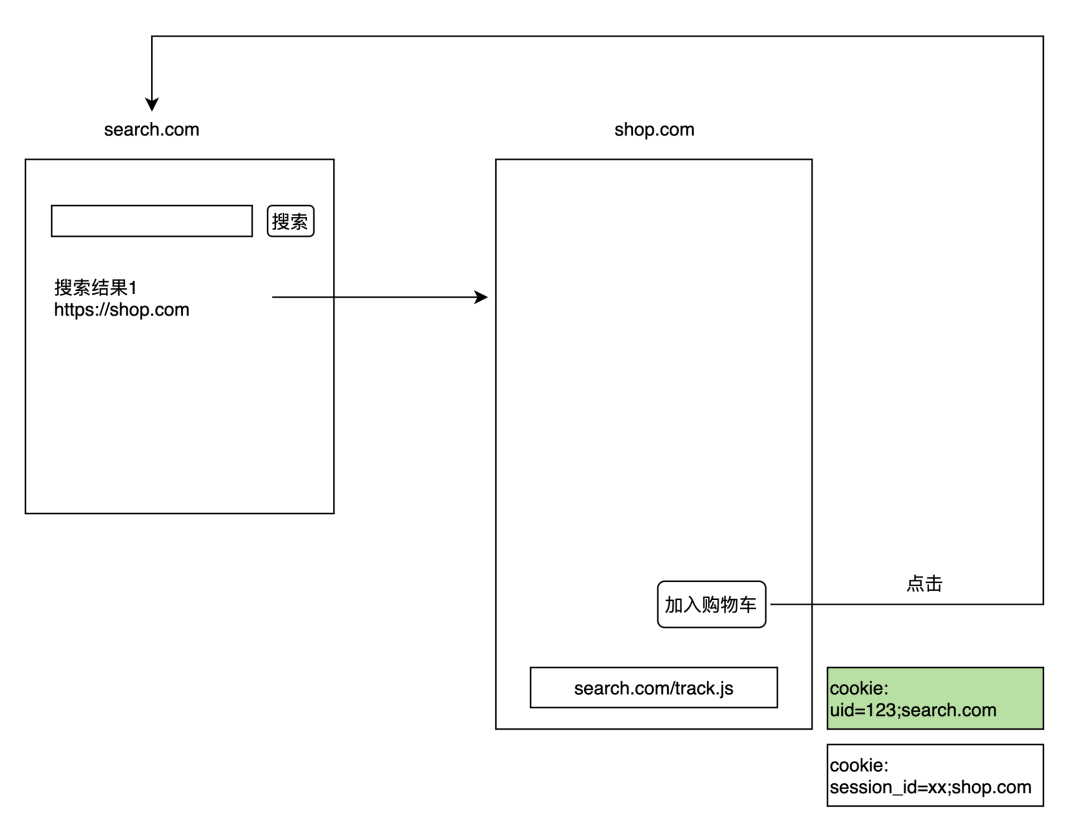
图中绿色背景的 Cookie 为第三方 Cookie,即 第三方脚本在主体网站上设置的 Cookie,这些 Cookie 可以由第三方控制,并且在发往第三方的简单请求时,会自动携带。在实际的情况下,处于各种各样目的用于跟踪用户的第三方脚本,在某些网站上甚至多达一百多条。
很显然,我们的保护手段是:禁止第三方 Cookie 的传输。
第三方 Cookie 对于隐私保护方面的风险大家的认同基本是一致的,这一做法在主流浏览器上在不同程度上已经逐步得以实现,小众的浏览器如 Tor 浏览器[8]、Brave 浏览器[9] 早已实现了这一举措,主流浏览器的情况如下:
Safari
2020.3.24 发布:在 iOS/iPadOS 13.4 和 Safari 13.1 版本之后,默认阻止第三方 Cookie 的传输[10]。
Firefox
2019.9.3 发布:在 Firefox 69.0 版本之后,默认阻止第三方 Cookie 的传输[11]。
Chrome
Chrome 在阻止第三方 Cookie 传输方面的动作就要谨慎的多,为了逐步实现阻止第三方 Cookie 的目标:
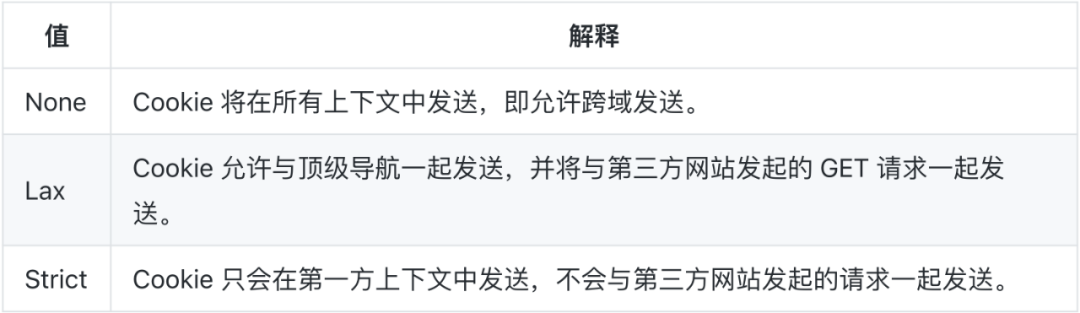
2016.5.25 发布:Chrome 51 开始,Cookie 增加一个新的属性: samesite,该属性有三个从低到高的值:None、Lax、Strict,默认值为None,详见 MDN[12]。
针对第三方 URL 的影响举例如下:
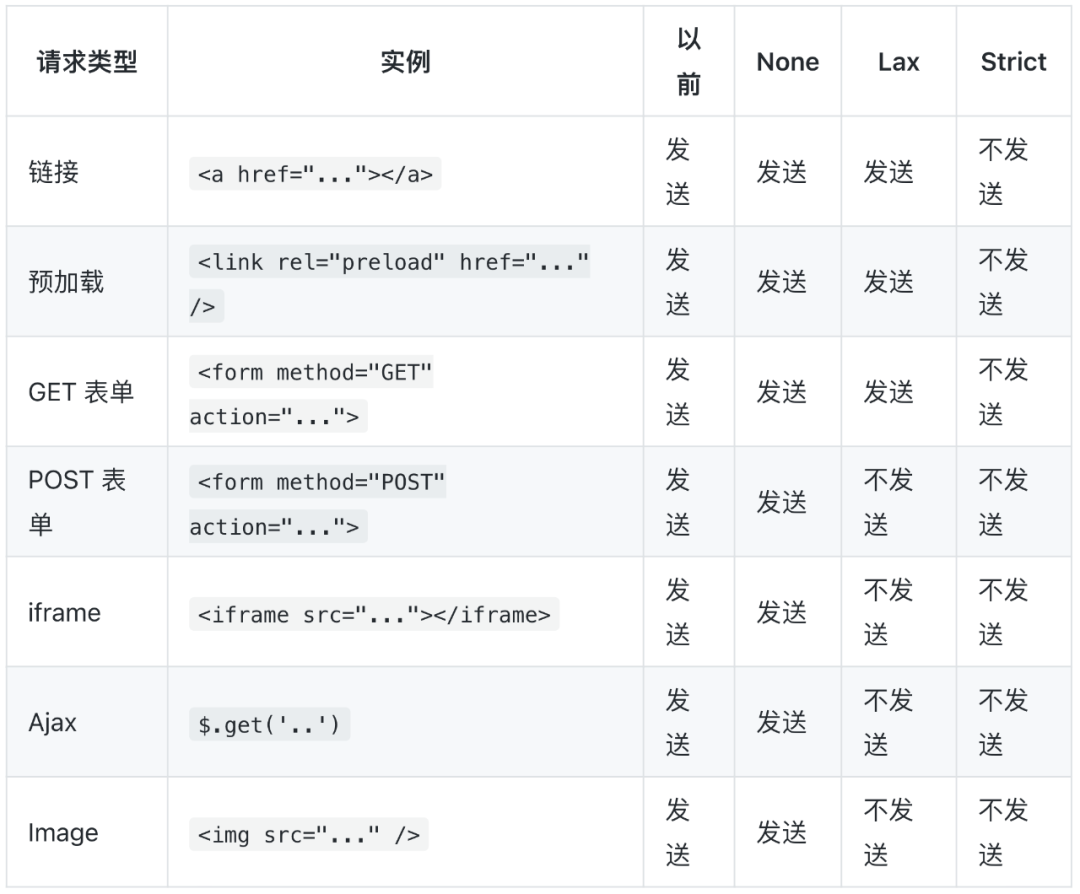
2020.1.14 发布:将在 2022 年 彻底阻止第三方 Cookie 的传输[13]。 2020.2 发布:Chrome 80 开始, samesite的默认值由None升级为Lax,并且要求如果强行设置 Cookie 的samesite=None,那么必须同时设置一个Secure属性(即该 Cookie 必须由 HTTPS 协议传输);2020.4.3 发布:受 COVID-19 的影响,上一条的 变更被回滚[14]; 2020.7.14 发布:Chrome 84 开始,重新上线回滚的变更; ... 未完待续:关于 samesite 的进展和更详细的时间线,可以查看官方网站的说明[15]。
从这个时间线和预期来看,未来 samesite 的默认值会再次升级为 Strict,这也是最终目标(和 Safari、Firefox 一样),时间点预期是 2022 年,前后可以看出阻止第三方 Cookie 的传输,持续 6 年左右。
App 间
让 User ID 难以获取
iOS
当前,「最有名」的让 User ID 难以获取的政策莫过于 Apple 公司的 iOS 14 新政了,让我们来看下整体的时间线:
iOS 5 及之前,可以获取到 UDID 2012.9:iOS 6 发布,新增了 Identifier for Advertising (IDFA) 2013.5:禁止获取 UDID 的 App 上架(合规要求); 2013.9:iOS7 发布,禁止获取 MAC/UDID,IDFA 可以被重置(设置 -> 隐私 -> 广告 -> 还原广告标示符),重置后重新生成新的 IDFA,限制广告跟踪的开关默认是关闭状态;
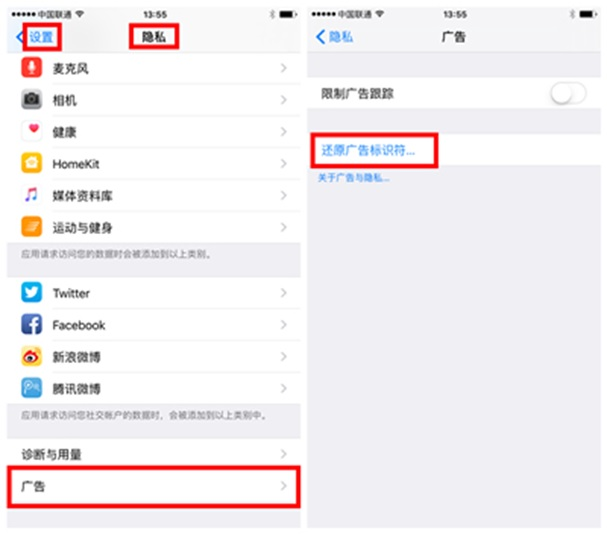
(图片来源:知乎[16])
2016.9:iOS 10 发布,「还原广告标示符」会将 IDFA 重置为一串无意义的 0,限制广告跟踪的开关默认仍然是关闭状态; 2020.6:Apple 公司宣布将在 iOS 14 中引入新的 隐私保护政策框架[17] --- App Tracking Transparency[18] (ATT),在新规之下,限制广告跟踪的开关默认是开启的,如果 App 需要跨应用跟踪用户,需要弹出申请弹窗,并且在用户点击允许之后,才能拿到 IDFA(可以猜想,看到弹窗的用户大概率是不会允许的)。
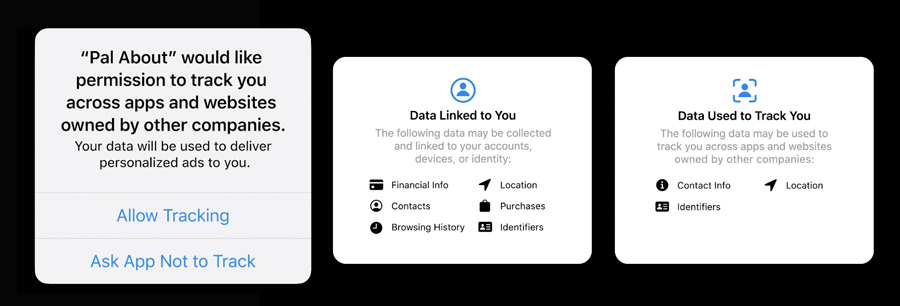
(图片来源:Apple 开发者官网)
因为此举会给整个移动互联网广告行业带来巨大的影响(下文会讲到),加上全球新冠肺炎疫情蔓延的影响,ATT 并没有在 2020.9 伴随 iOS 14 一起发布,而是一直在推迟,终于在 2021.4.26,Apple 公司发布上 iOS 14.5 集成了这一功能。
纵观整个时间线,从 2012 年至今,Apple 公司对于隐私保护政策的倾向是越来越严格的,让唯一的 User ID 越来越难以获取到,甚至获取不到。
Android
相比于 iOS,Android 对于 User ID 标识的获取的限制就温和得多。据 彭博社报道[19]:
Google 正在研究和跟进 ATT,并且探索替代方案。其解决方案大概率没有那么严格,也不会需要弹出弹窗来获取用户许可,这些探索都处于早期,并没有决定是否跟进或者何时跟进。
围绕 Android 类似解决方案的讨论显示,这一替代方案很可能会像 Chrome 限制第三方 Cookie 那样,逐步地进行限制。
综上,Android 上的 User ID 及相关隐私保护政策,短期内没有明确的时间表。
禁止跨主体的数据共享或匹配
iOS
在第一点其实已经讲过了,ATT 政策除了限制 IDFA 的获取之外,还禁止了跨 App 的数据共享和匹配。
Android
同上,相关政策目前没有明确的时间表。
政府机构
除了各大厂商提供了一些隐私保护措施,政府或机构也先后制定并出台了一些是隐私保护的法律法规。
General Data Protection Regulation (GDPR[20])
GDPR 的主要目标是个人对于个人数据的控制,以及为了国际商务而简化在欧盟内的统一规范。用户可以直接感知到的解释是:以上提到的无论是 User ID 的生成、储存甚至跨主体共享,用户都是不知情或者即使知情也无法拒绝的。GDPR 就是希望将这个控制权「拿」回来。

一个很明显的变化是,在 GDPR 生效后,很多网站会在页面中披露隐私政策以及 Cookie 技术的使用情况(如上图所示),告诉用户:
个人数据的用途、保留时间以及是否和第三方共享 如何停止跟踪 如何访问、管理、更新和删除个人数据
GDPR 法规已于 2018 年 5 月 25 日开始实施,详细可以参见 维基百科[21] 的词条解释。
California Consumer Privacy Act (CCPA[22])
CCPA 的条款基本内容和设立目的和 GDPR 基本相同,他们区别点在于关于个人数据的定义、每种信息的内容范围和地域范围、个人信息销售的选择权等。
CCPA 于 2020 年 1 月 1 日开始实施,详细可以参见 维基百科[23] 的词条解释。
附:在调研过程中,发现了能提高合规改造效率的工具:__CookieBot[24]
个性化广告会面临哪些困难?
隐私保护政策整体收紧的情况下,会对广告行业的转化归因、用户画像、程序化交易等产生普遍影响,这里我们讨论最重要的即 转化归因。
转化归因是什么?
用通俗的话来说,就是「本次转化是由于哪个媒体的哪个位置哪次的 show/click 引起的」。转化归因对于广告系统是非常重要的,因为它和广告计费、广告定向是息息相关的。
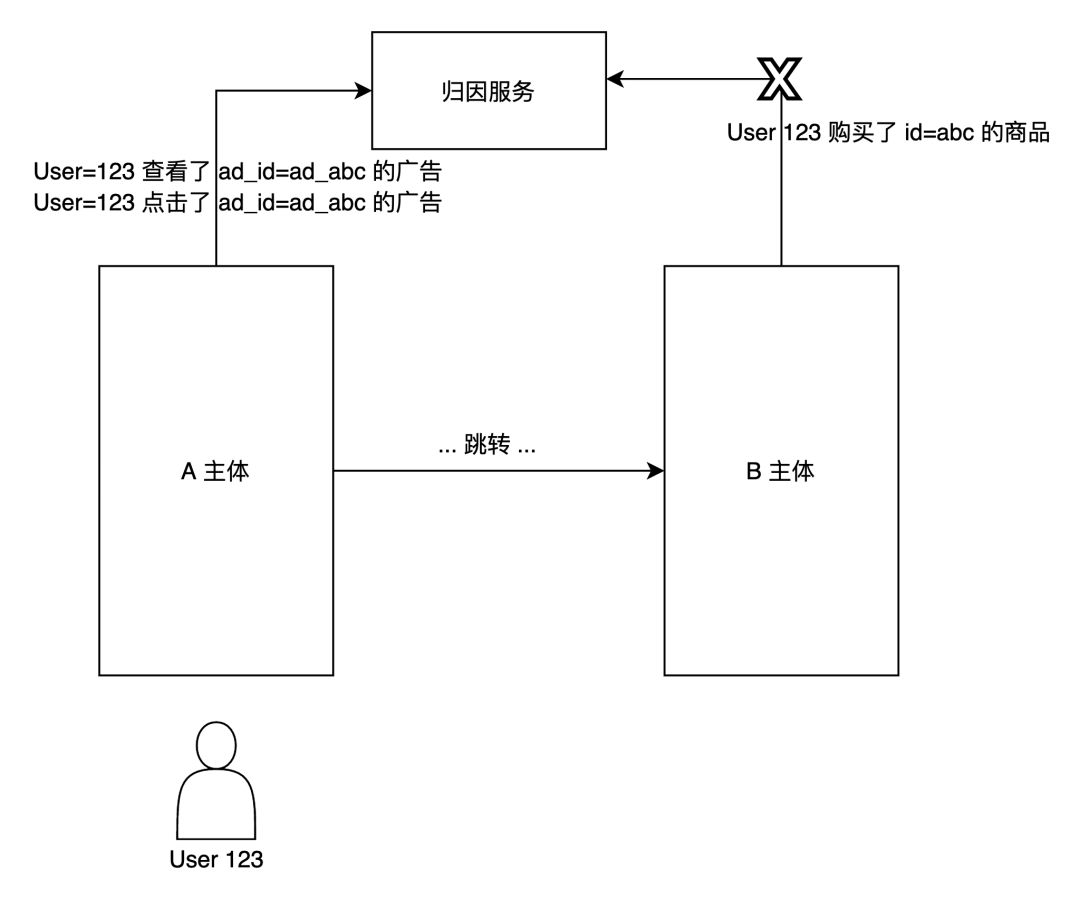
上图抽象了用户 123 从 A 主体到 B 主体之后,发生转化的过程(当然实际过程要比图中复杂得多)。图中的归因服务可以由 A 主体提供,也可以由第三方提供。B 主体上报信息可以通过埋入来自 A 主体的 SDK 实现,也可以由 B 主体自己上报。
从图中可以看到,关键点在于归因服务,需要拿到来自 A 主体和 B 主体,根据 User ID 进行匹配。但是如果按照用户隐私保护政策:让 User ID 难以获取并且禁止跨主体的数据共享或匹配 进行处理的话,来自 B 主体的上报链路就必须断开,这对于广告的转化归因来说,简直是灾难。
此外,一般在归因服务完成后,我们可以依据 User ID 对于该广告的兴趣特征进入到广告竞价模型中,实时地做反馈,优化模型预估 eCPM 的准确性,进而做广告重定向、给相似用户推送相似的广告等。这些工作,在用户隐私保护政策下,都做不了了。
当前有哪些解决方案?
隐私保护和个性化是天平的两端,整个行业都在两者间寻求平衡,看能否做到保护用户隐私的情况下,给用户提供个性化广告。如果完全按照上文的做法实施,隐私保护政策对于个性化广告的打击是「毁灭性」的。好在各大厂商在推出隐私保护政策的同时,大多也会提供合规的解决方案,而其中又存在着厂商之间的角力和博弈,下面就介绍一些常见的转化归因和模型定向的解决方案,转化归因从场景分为 Web-to-Web、App-to-Web、App-to-App:
Web-to-Web:从网页跳转至网页的场景(多见于 PC 端广告);
App-to-Web:从 App 跳转至网页的场景(这是比较常见的第三方落地页广告,如从抖音 feed 流打开广告主的落地页);
App-to-App:从 App 跳转至 App 的场景(这是比较常见的应用下载广告,如从抖音 feed 流点击调起 App Store,下载后,进入目的 App)
Private Click Measurement (PCM[25])
PCM 是 Apple 在 2021 年 2 月 1 日发布的,将会集成在 iOS/iPadOS 14.5 中。主要解决的是 MacOS、iOS、iPadOS 系统中 Web-to-Web 和 App-to-Web 场景下的广告归因问题。原理如下:
Web-to-Web
之前: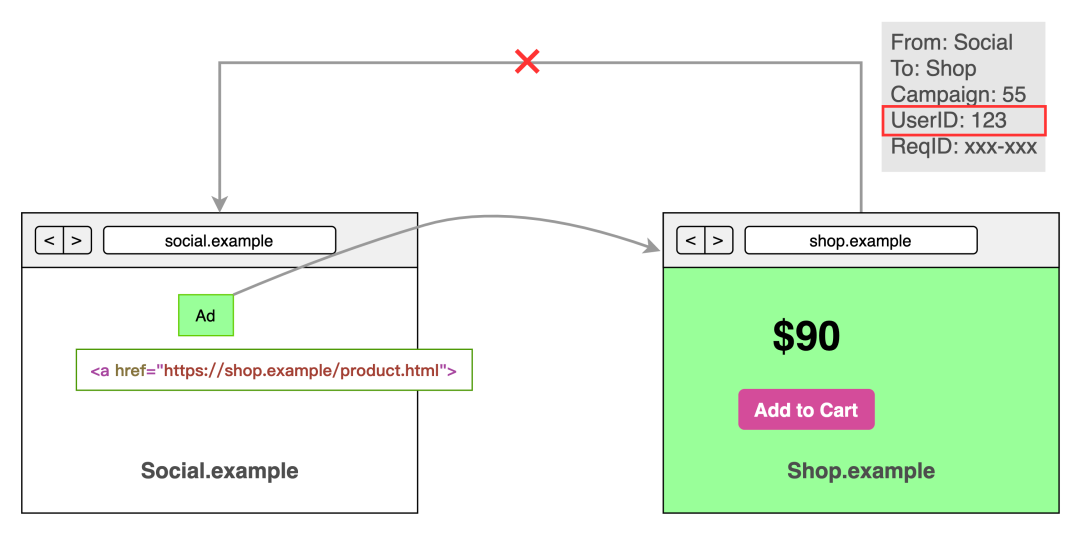
(图片重绘自 Webkit 博客[26])
如之前的分析,在隐私保护的情况下,首先 User ID 难以获取,再就是跨站的数据共享也是不可实现的。我们看 PCM 是如何解决问题: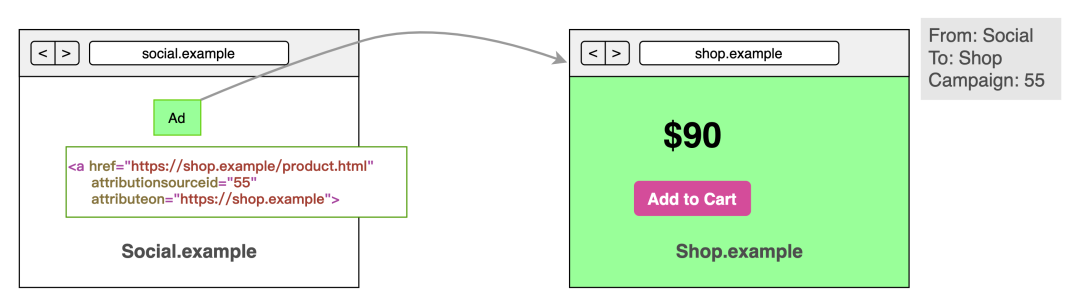
(图片重绘自 Webkit 博客[27])
在 <a>标签增加两个属性:attributionsourceid和attributeonattributionsourceid:8-bit 的源 ID,即 0 - 255 共 256 个,在广告中,通常都是指 campaign_id,表明是从属于哪个广告计划;
解读:
既然是用于归因的,为什么名字不起成 campaign_id?
答:因为 PCM 从技术上并不是和广告紧密相关,所以起了一个比较中性的名字 source_id。
限制 8-bit = 256 个总数是为了什么?
答:为了限制同一个 A 主体下,进行跨站追踪的最大广告计划个数,即 256 个。
attributionon:接下来要进行归因的目标网站域名,只支持可注册的域名或者 eTLD + 1(通俗来讲就是合法的可注册域名)。
解读:
attributionon是什么?
答:要跳转目的网站的域名,这里有个名词叫 eTLD + 1,eTLD= effective Top Level Domain,不同于 TLD 即 .com, .cn 等,eTLD 是有效的 TLD,如 .com.cn, .edu.cn, Mozilla 维护了一个 Public Suffix List[28] (PSL) 。
这里的 eTLD + 1,是更准确的说法。比如我的 Github 项目 color-picker 的主页地址:https://zhangbobell.github.io/color-picker/,由于 github.io 是一个 eTLD,所以如果跳转的目的网页是上面的地址的话,
attributionon="https://zhangbobell.github.io"。
还有一些非常有意思的 eTLD,如 s3.eu-west-2.amazonaws.com, pvt.k12.ma.us,他们都是可以被 eTLD + 1 的,如果有兴趣翻看 PSL 官网的话,可以发现「浏览器地址栏如何判定你是在搜索,还是在进入一个网站?」这个判断就是基于这个维护的列表,其他应用可以参见 官网[29]。
为什么要限制为 eTLD + 1 ,而不是通常意义 URL 的 host 部分?
答:一般情况下,eTLD + 1 都是有明确域名注册主体的,而 host 部分可能为 泛解析[30],如果将 *.shop.example 都指向 shop.example,然后
attributionon="``https://``janeDoeTracking.shop.example",很显然,这个 janeDoeTracking 就可以映射为 user ID,存在漏洞,不能达到保护隐私的目的。
如果用户通过点击 a 标签,最后到了 shop.example。那么这次 attributionsourceid将会被储存为一次从 social.example 到 shop.example 的点击,浏览器本地储存 7 天,任何网站都不能读取这些数据,是在浏览器上储存的。在 shop.example 上,点击了 “Add to Cart” 按钮,作为转化事件,会触发事件上报至 social.example。到这里,和传统的 Pixel 没有什么不同。不过和 Pixel 不同的地方在于:
上报是 GET 请求到 https://social.example/.well-known/private-click-measurement/trigger-attribution/[4-bit trigger data]/[optional 6-bit priority],如下图: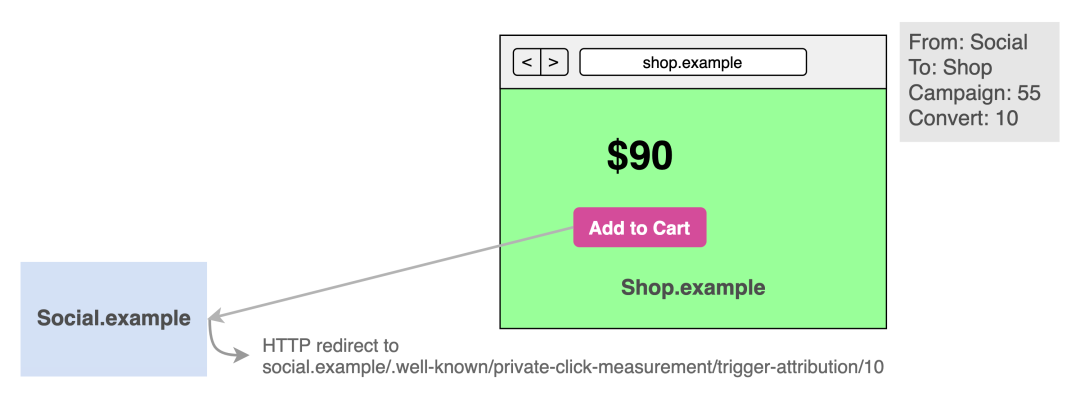
(图片重绘自 Webkit 博客[31])
URL 中的有两个参数 trigger data和 optional priority:
trigger data:4-bit (00 到 15,必须为两位数字),用于表示事件类型如:加入收藏、加入购物车、下单、付款完成等;optional priority:6-bit(00 到 63,必须为两位数字),用于表示事件优先级。trigger data的事件在业务中,可能有不同的优先级,比如付款完成 > 下单 > 加入购物车,我们给这些转化事件赋予不同的优先级,用于控制最后的发送内容,并不会包含在最后的归因报告中(下文会讲到)。
一旦浏览器检测到某个转化事件和之前的 click 匹配,浏览器会在接下来的 24 - 48 小时随机时刻发送出归因结果,在这一区间中,如果有更高优先级的转化事件进入,则会上报这个更高优先级的事件。
解读:
这一步和传统的 Pixel 有哪些不同?
答:首先,回传的信息只有 4-bit,所以就限定了不太可能回传 User ID / Request ID 之类的信息,即最多支持 16 种转化事件。而 Pixel 上报则完全没有这个限制,可以带 User ID、转化事件一切归因相关的信息。
其次,由于「优先级」的存在,一份归因结果中,只会出现一种转化事件,而 Pixel 可以将发生过的所有转化事件上报,即 PCM 归因具有聚合性。
最后,浏览器会将转化事件储存起来,在 24 - 48 小时中的随机时刻发送出去,而 Pixel 是实时的,即 PCM 归因具有延迟性。
最后就是归因结果的内容了 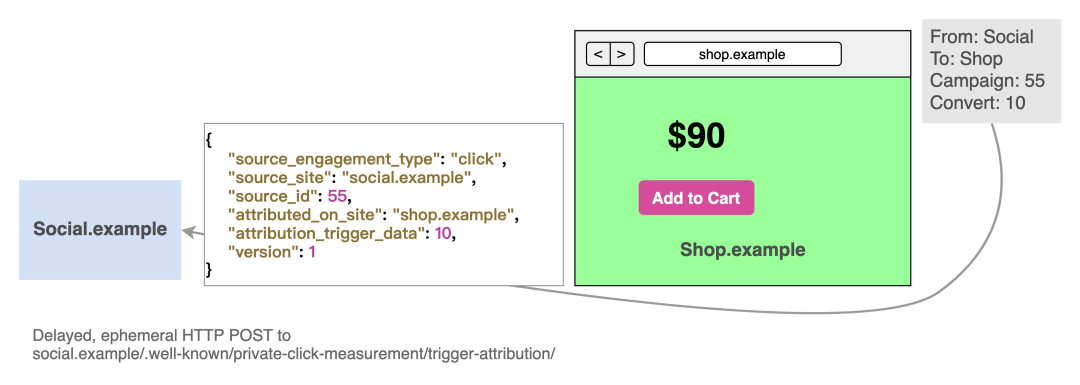
(图片重绘自 Webkit 博客[32])
PCM 的归因结果会通过 HTTP POST 请求到 /.well-known/private-click-measurement/report-attribution/,本例中就是 https://social.example/.well-known/private-click-measurement/report-attribution/,请求体内容如下:
{
"source_engagement_type": "click",
"source_site": "social.example",
"source_id": [8-bit source ID],
"attributed_on_site": "shop.example",
"attribution_trigger_data": [4-bit trigger data],
"version": 1
}
注意到,如上文提到的,priority 信息不会包含最终的结果中。需要解释的是:
source_engagement_type:对于 PCM 来说,值始终为 "click"。version:当前值为 1,未来可能会有升级的空间。
App-to-Web
在理解了 Web-to-Web 之后,App-to-Web 理解起来就非常简单了,只不过点击源从 Site 换成了一个 App,流程一致,只不过具体 App 实现上,之前通过 a 标签实现的部分,变成了 iOS App 的函数调用打开 Safari 浏览器(注意,目前 PCM 还不支持端内 inline 的 WKWebview 或者 SFSafariViewController(简称 SVC),即必须外跳调起 Safari,体验相对较差,不过 Apple 表示对支持 SVC 感兴趣)。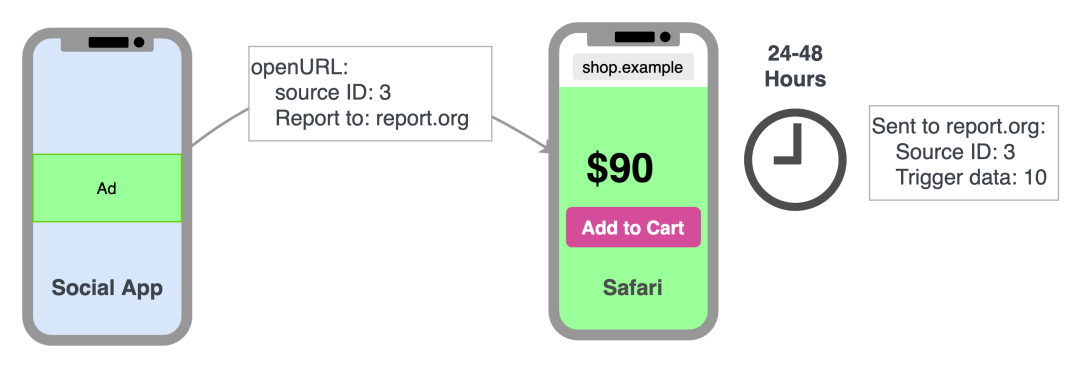
(图片重绘自 Webkit 博客[33])
PS:WKWebview 和 SVC 的 UI 上的差别如下:
(左:Facebook App 的 WKWebview,右:Youtube App 的 SVC)
WKWebview 提供了比较多的 API,具有较强的定制性,比如九分屏、信息流卡片、预加载等。而 SVC 提供了非常有限的 API,基本无法定制,基本上可以认为是一个 Safari 浏览器的内嵌版。
值得注意的是,Apple 在 2019 年 5 月就提出了「基于保护隐私的广告点击度量[34]」的提案(也叫 Ad Click Attribution),已经在现在的 Mac 或者 iOS 端已经集成了,这一提案就是 PCM 的前身,基本原理和 PCM 差不多,只是一些参数名略有变化。

左:MacOS:Safari 浏览器-> 开发 -> 试验性功能 -> Ad Click Attribution
右:iOS/iPadOS:设置 -> Safari 浏览器 -> 高级 -> Experimental Features -> Ad Click Attribution
想要体验的话,可以下载 Safari 浏览器开发版或者 iOS/iPadOS 14.5 beta 版本,或者直接体验之前的 Ad Click Attribution 版本,提供了一个 debug 功能,其会在 10s 之后发出归因结果,而不是 24 - 48 小时。
PCM 目前处于在 W3C 隐私社区组的 Draft 阶段,详细内容见 W3C spec[35],需要两个浏览器(目前只有 Safari 浏览器)独立实现 该标准后,才可能成为 Web 标准,关于 PCM 的更多详细信息,可以参见 Webkit 的 博客文章[36]。
SKAdNetwork (SKAN[37])
Ad network API 是 Apple 提出的 App 广告归因方案。主要为了解决在保护隐私的情况下, App 下载/安装广告的归因问题(App-to-App)。主要包含三个参与方:广告平台、源 App、推广的 App。
广告平台(如 TT4B):向 Apple 注册广告平台的 ID,下发广告至源 App,接收并校验安装事件的回调; 源 APP(如抖音,图中 A App):显示平台下发的广告; 被推广的 App(如某款新游戏,图中 B App):在 App 打开的时候,调用安装事件的发送方法(实际延迟 0 - 24 小时发送)。
详情如下图所示:
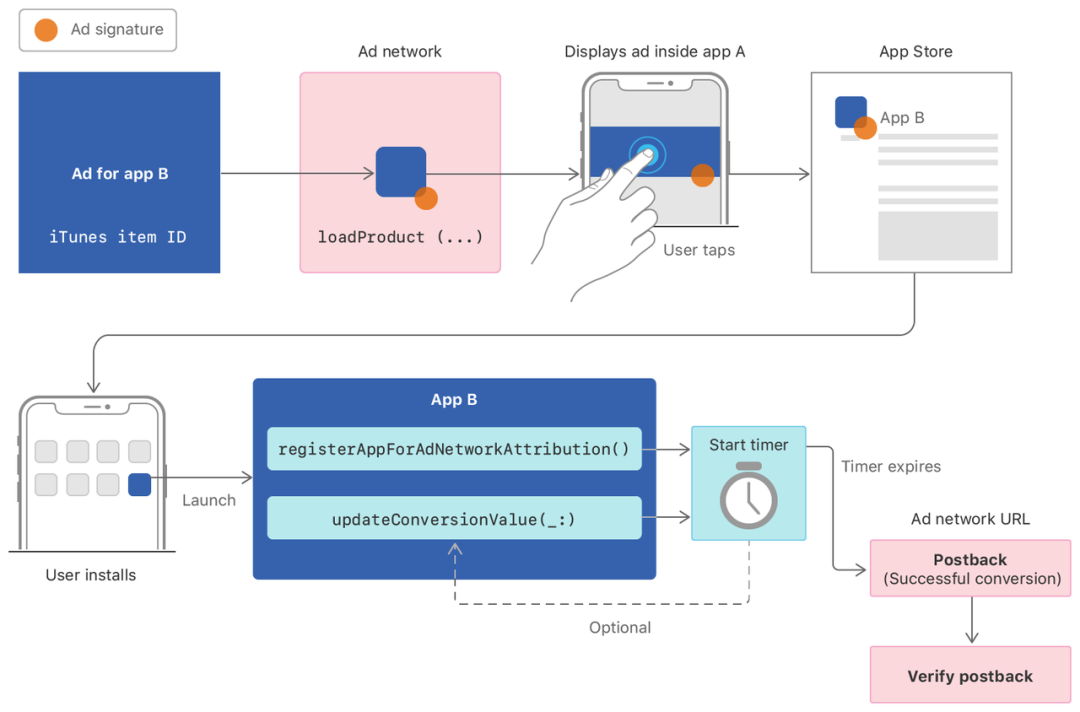
(图来自 Apple 开发者官网)
在理解了 PCM 之后,SKAN 就很好理解了,所有的特性都差不多(约束范围,事件聚合、延迟发送),我们看一下最后延迟上报的数据
{
"version": "2.2",
"ad-network-id": "com.example",
"campaign-id": [integer between 1-100],
"transaction-id": "6aafb7a5-0170-41b5-bbe4-fe71dedf1e28",
"app-id" : 525463029,
"attribution-signature": "MEYCIQDTuQ1Z4Tpy9D3aEKbxLl5J5iKiTumcqZikuY/AOD2U7QIhAJAaiAv89AoquHXJffcieEQXdWHpcV8ZgbKN0EwV9/sY",
"redownload": true,
"source-app-id": 1234567891,
"fidelity-type": 1,
"conversion-value": [6-bit conversion value]
}
我们来讨论一下细节:
campaign-id:因为 SKAN 是专为 App Ad 打造的,所以名字就不用像 PCM 那样比较通用了,这里的限制是 1 - 100 之间的整数;conversion-value:转化事件的值,6-bit 的整数 0 - 63,实际用途是转化事件类型,如用户注册、登录等,类似于 PCM 中的trigger data属性。App 可以在第一次打开之后,0-24 小时窗口期之前,可以通过调用函数,更新这个值,更新之后,窗口期重新开始计时。
其余的字段,通过字面意思应该就可以知道了,如 app-id 指的是被推广的 App B,source-app-id 指的是源 App A,ad-network-id 则是广告平台的 ID,attribution-signature 则是为了校验本次归因结果的,具体这里就不做进一步讨论了,有兴趣可以查看 Apple 开发者官网 关于 SKAdNetwork 的文档[38]。
SKAN 也是引起「iOS 14 问题」被热议的源头,第一版在 2018 年发布,但是那时 IDFA 还能直接获取到,所以没有引起太大的关注。而 2020 年随着 IDFA 被纳入 ATT,作为 Apple 官方提供的唯一合规的 App 广告的归因方案,SKAN 也发布了第二版,集成在 iOS 14.5。
纵观 Apple 提供的方案,无论是 PCM 还是 SKAN,都体现出了「保护隐私的情况下,如何完成广告归因」的总体原则:
约束范围(Restricted):无论是 campaign_id 还是 trigger-data,所有用于归因的数据,都进行了相应的 bit 位数的限制,很大程度上避免了精准的信息泄露; 事件聚合(Aggregated):一次点击产生的后续所有转化事件,都按照一定的规则(PCM 是通过 Priority,SKAN 则是时序)会进行聚合,最后上报的只会有一次转化事件。 延迟发送(Delayed):转化事件发生后,不会立即发送,会延迟 24 - 48 小时之内的随机时间发送出去。
Aggregated Event Measurement (AEM[39])
由于 PCM 方案的 App-to-Web 目前只支持外跳调起 Safari 浏览器,用户体验较差,于是 Facebook 基于 PCM 设计的总体原则,提出了 AEM 方案。由于原理一致,就不再对流程进行细致分析了,只分析一下细节上的不同:
trigger-data:转化事件类型,PCM 为 4-bit(16 种),AEM 为 3-bit(8 种);延迟上报:PCM 为 24 - 48 小时,AEM 最长为 72 小时(3 天);
当然,如何储存在本地、优先级匹配和延迟上报,都依赖于 Facebook App 自己的实现,通过这种「自我约束」行为,AEM 让 App-to-Web 在全链路都发生在 App 内部,用户体验较好。详细可以查看 Facebook 关于 AEM 的介绍[40]。
Facebook 广告平台已经发布了 AEM 方案,并且面向广告主使用。另一方面,AEM 方案是否获得 Apple 的认可的问题,还在进行中,目前一切尚不明朗,后续有任何进展,会随时同步。
Federated Learning of Cohorts (FLoC[41])
联邦学习提供了一个在保护隐私的情况下基于兴趣的广告选择机制,在 2016 年由谷歌最先提出,原本用于解决安卓手机终端用户在本地更新模型的问题,近两三年在国内应用的比较火热,2020 年 10 月,InfoQ 上还发表了一篇《字节跳动破局联邦学习:开源 Fedlearner 框架,广告投放增效 209%》[42]文章,介绍字节跳动在联邦学习上的一些成果。
严格来说,FLoC 是为了做广告定向的。FLoC 的原理,简单来说就是:**浏览器将具有相似浏览记录的用户分到一个群组(Cohort),广告平台通过联邦运算,可以为这些群组提供合适的广告。**尽管在联邦学习过程中,会存在信息交换,但是联邦学习框架的存在,保证了信息交换时,彼此匿名并且脱敏,无法反向破解或者穷举,保证个人隐私和法务合规性。根据谷歌自己的评估,FLoC 的有效率达到了使用第三方 Cookie 的 95%。
Cohort 的计算和形成都是在浏览器本地完成,数据来源是用户的浏览历史记录、本地计算的页面分类等,为了保护隐私,可能还会在结果输出时加一些噪声混淆。下图展示了一个例子:
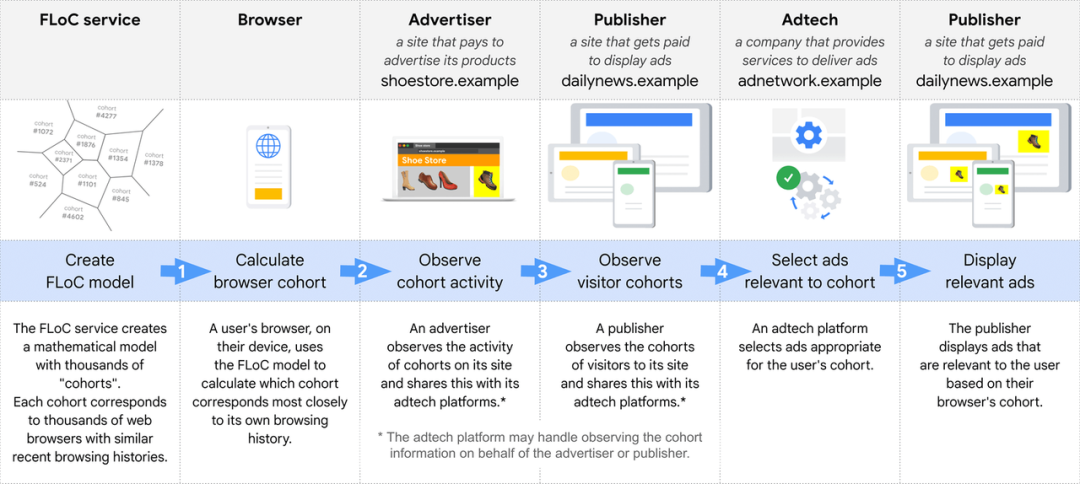
(图片来自 FLoC 的 官网文章[43])
举例如下(来自官网):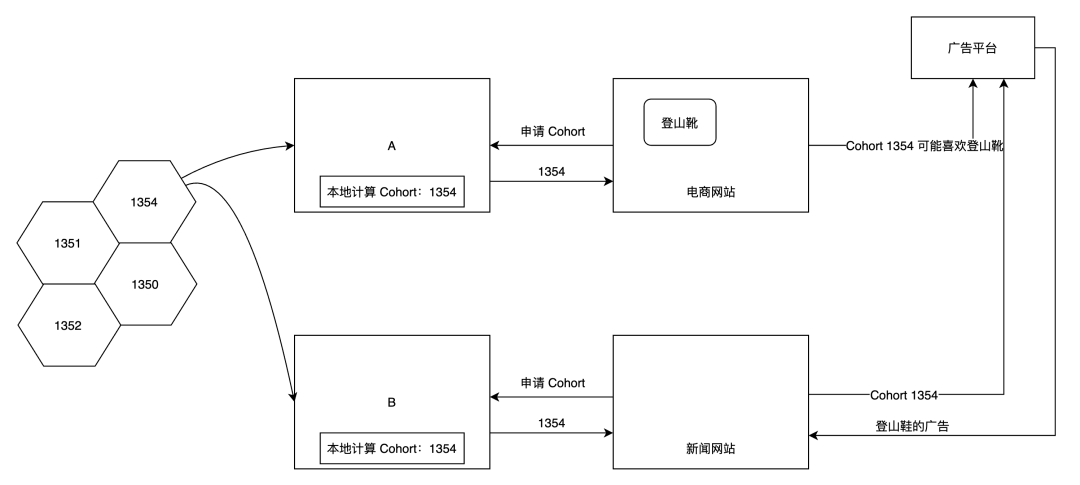
FLoC Service 提供了一个包含了成千上万个 Cohorts 的模型,每个 Cohort 可以看作是近期浏览记录相似的浏览器; 通过 FLoC Service,A 的浏览器可以获取到 FLoC 模型的数据,依据 A 的浏览历史,浏览器本地计算出,A 属于 Cohort 1354,同样的方式,尽管 B 的浏览历史和 A 不太相同,但是可能仍然属于 Cohort 1354; 接着,B 访问了某个卖鞋的电商网站: 该网站向 B 的浏览器请求了他的 Cohort:1354,接着 B 看了看登山靴,B 网站记录下「一个来自 Cohort 1354 的浏览器可能对登山靴感兴趣」; 该网站定期聚合数据,并向广告平台如 TT4B 共享关于 Cohort 和产品兴趣的信息。 接着,A 访问了某个新闻网站: 该网站向 A 的浏览器请求了他的 Cohort:1354; 该网站向广告平台 TT4B 请求广告,包含了 A 的 Cohort 1354 广告平台 TT4B 为 A 提供相关的广告,主要来自两方面的数据: 新闻网站提供的 A 的 Cohort 信息; 电商网站提供的「来自 Cohort 1354 的浏览器可能对登山靴感兴趣」 新闻网站展示广告:🥾
以上的 A 和 B 是为了表述,实际过程中,个人信息并不会向任何相关方泄露。可以认为 Cohort 不是一群人,而是一些浏览历史的集合。
FLoC 提案[44] 提出了一个新的 JavaScript API:
cohort = await document.interestCohort();
url = new URL("https://ads.example/getCreative");
url.searchParams.append("cohort", cohort);
creative = await fetch(url);
默认所有的网站的历史记录都会被当作 Cohort 的计算来源,如果想要 Opt-out,可以通过 HTTP 的 reponse header 来进行:
Permissions-Policy: interest-cohort=()
FLoC API 在 Chrome 89 及以上版本的浏览器可用,不过试用的话,需要通过命令行的方式打开 Chrome,最后的 DEMO 见 FLoC.glitch.me[45],更多细节在 这里[46]。Google 将在 2021 年第二季度在 Google Ads 上测试 FLoC[47](FLoC 也存在一些安全隐患[48],尽管这些测试已经开始,但是遭到了抵制)。
安全隐患包括:
1. 指纹识别风险犹在:指纹 + FLoC 加剧了风险。
2. 弱势群组容易被歧视对待:例如基于性别、年龄、种族、宗教等维度推荐带有歧视性的求职、买房、信贷等广告都是在利用弱势群体标签谋私利。
3. 跨语境下的隐私曝光:FLoC 会更新,网站会清楚用户的兴趣「迁移」
另外,FLoC 未经用户知情并同意,在浏览器内部进行了用户行为数据的「处理」,不符合 GDPR 的原则,所以 Google 主要选择 SEA, JP, NA 等地区的 0.5% 的用户进行测试。
值得注意的是,FLoC 只是 Google 提出的 Privacy Sandbox[49] 的一部分,由于这个点比较有意思,所以单独拿出来分享。Google 于 2019 年 8 月发起了 Privacy Sandbox 项目,使命是:打造一个繁荣的 Web 生态系统,默认尊重每位用户和隐私。讨论并实现「如何在保证隐私的情况下,实现商业化变现」,和本文的主题紧密相关,该项目包含了一系列的提案:
替换现有依赖于跨站追踪的功能:比如反垃圾、广告转化度量(和 PCM 的特性差不多,只是细节上有些差别)、广告定向(FLoC)等; 逐步下线第三方 Cookie:Cookie 的属性变更(上文分享过)、第一方集合等; 常见的替代方法:浏览器指纹、缓存查看、浏览追踪等
这些对于研究隐私和广告的平衡,有非常重要的启示,也反映出 Google 对于二者关系的解决方案更为系统和长远,强烈推荐大家阅读(Privacy Sandbox 官网[50])。
第一方落地页
由于隐私保护的大方向是:禁止跨主体的用户信息匹配,除了以上的方案,我们还可以将所有的用户信息都限制在同一个主体内,这个方案就是使用第一方落地页:尽可能将用户的行为在一方内部完成(全闭环),不在第三方有转化行为。
为此,我们推出了面向线索收集场景的产品,Lead Generation。用户会在第一方页面上提交线索,完成转化。
(线索收集 DEMO)
结语
隐私和个性化广告的关系犹如天平的两端,这给我们从事广告行业的同学不断提出了新的挑战。如何在保护隐私的情况下,为用户提供个性化广告服务,也体现了技术对于隐私的尊重和敬畏。本文主要分享了个性化广告历史、本质问题、如何保护隐私以及现有的一些解决方案。当然,随着时间推移,也会不断有新的方案出现,相信在未来的某天,我们一定可以在两者之间寻找到更合适的解决方案。
最后,由于才疏学浅,本文的内容难免出现谬误,还请大家多多批评指正!
相关知识和文档
认识一下 iOS 系统的各种设备识别码
1、UDID ,全称是 (Unique Device Identifier),顾名思义,它就是苹果 IOS 设备的唯一识别码,它由 40 个字符的字母和数字组成,为了保护用户隐私苹果已经禁止读取这个标识了。
2、UUID,全称是(Universally Unique IDentifier),是基于 iOS 设备上面某个单个的应用程序,只要用户没有完全删除应用程序,则这个 UUID 在用户使用该应用程序的时候一直保持不变。如果用户删除了这个应用程序,然后再重新安装,那么这个 UUID 已经发生了改变。UUID 不好的地方就是用户删除了你开发的程序以后,基本上你就不可能获取之前的数据了。
3、MAC 地址,用来定义网络设备的位置。一个主机会有一个 MAC 地址,MAC 地址是网卡决定的,是固定的,为了保护用户隐私苹果已经禁止读取这个标识了。
4、OpenUDID,不是苹果官方的,是一个替代 UDID 的第三发解决方案, 缺点是如果你完全删除全部带有 OpenUDID SDK 包的 App(比如恢复系统等),那么 OpenUDID 会重新生成,而且和之前的值会不同,相当于新设备;
5、IDFA 广告标示符,适用于对外:例如广告推广,换量等跨应用的用户追踪等。
6、IDFV,Vendor 标示符 (IDFV - Identifier For Vendor),来自同一个开发商(例如 com.zhihu.app1 和 com.zhihu.app2)的应用运行在同一个设备上,此属性的值是相同的;不同的运营商应用运行在同一个设备上值不同。
Webkit 阻止跟踪(ITP)的介绍
https://webkit.org/tracking-prevention/
掘金上设备 ID 生成的文章
https://juejin.cn/post/6844903952148856839
Apple 在 2019 年发布的 Safari 白皮书
https://www.apple.com/safari/docs/Safari_White_Paper_Nov_2019.pdf
浏览器指纹生成的调研论文
https://arxiv.org/pdf/1905.01051.pdf
阿里关于 Cookie samesite 默认值变更为 Lax 的改造总结:
https://github.com/mqyqingfeng/Blog/issues/157
Chromium 团队提出的 Privacy Sandbox 介绍
https://www.chromium.org/Home/chromium-privacy/privacy-sandbox
CSDN 上关于联邦学习的简介
https://blog.csdn.net/cao812755156/article/details/89598410
FLoC 测试遭到抵制
https://mp.weixin.qq.com/s/XNgyjrBnFpFvFWKenxZ0jg
参考资料
人人都是产品经理: http://www.woshipm.com/it/4033863.html
[2]fingerprintjs: https://github.com/fingerprintjs/fingerprintjs
[3]知乎: https://www.zhihu.com/question/38856446/answer/131089134
[4]DEMO: https://fingerprintjs.github.io/fingerprintjs/
[5]Apple Safari 2019 隐私安全白皮书: https://www.apple.com/safari/docs/Safari_White_Paper_Nov_2019.pdf
[6]Disconnect: https://disconnect.me/trackerprotection
[7]Firefox 72 的发布说明: https://blog.mozilla.org/security/2020/01/07/firefox-72-fingerprinting/
[8]Tor 浏览器: https://2019.www.torproject.org/projects/torbrowser/design/#identifier-linkability
[9]Brave 浏览器: https://brave.com/ok-google/
[10]默认阻止第三方 Cookie 的传输: https://webkit.org/blog/10218/full-third-party-cookie-blocking-and-more/
[11]默认阻止第三方 Cookie 的传输: https://blog.mozilla.org/blog/2019/09/03/todays-firefox-blocks-third-party-tracking-cookies-and-cryptomining-by-default/
[12]MDN: https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Set-Cookie/SameSite
[13]彻底阻止第三方 Cookie 的传输: https://blog.chromium.org/2020/01/building-more-private-web-path-towards.html
[14]变更被回滚: https://blog.chromium.org/2020/04/temporarily-rolling-back-samesite.html
[15]说明: https://www.chromium.org/updates/same-site
[16]知乎: https://www.zhihu.com/question/38856446/answer/131089134
[17]隐私保护政策框架: https://developer.apple.com/app-store/user-privacy-and-data-use/
[18]App Tracking Transparency: https://developer.apple.com/documentation/apptrackingtransparency
[19]彭博社报道: https://www.bloomberg.com/news/articles/2021-02-04/google-explores-alternative-to-apple-s-new-anti-tracking-feature
[20]GDPR: https://gdpr-info.eu/
[21]维基百科: https://zh.wikipedia.org/wiki/%E6%AD%90%E7%9B%9F%E4%B8%80%E8%88%AC%E8%B3%87%E6%96%99%E4%BF%9D%E8%AD%B7%E8%A6%8F%E7%AF%84
[22]CCPA: https://oag.ca.gov/privacy/ccpa
[23]维基百科: https://en.wikipedia.org/wiki/California_Consumer_Privacy_Act
[24]CookieBot: https://www.cookiebot.com/en/
[25]PCM: https://webkit.org/blog/11529/introducing-private-click-measurement-pcm/
[26]Webkit 博客: https://webkit.org/blog/11529/introducing-private-click-measurement-pcm/
[27]Webkit 博客: https://webkit.org/blog/11529/introducing-private-click-measurement-pcm/
[28]Public Suffix List: https://publicsuffix.org/list/public_suffix_list.dat
[29]官网: https://publicsuffix.org/
[30]泛解析: https://support.google.com/domains/answer/4633759?hl=zh-Hans
[31]Webkit 博客: https://webkit.org/blog/11529/introducing-private-click-measurement-pcm/
[32]Webkit 博客: https://webkit.org/blog/11529/introducing-private-click-measurement-pcm/
[33]Webkit 博客: https://webkit.org/blog/11529/introducing-private-click-measurement-pcm/
[34]基于保护隐私的广告点击度量: https://webkit.org/blog/8943/privacy-preserving-ad-click-attribution-for-the-web/
[35]W3C spec: https://privacycg.github.io/private-click-measurement/
[36]博客文章: https://webkit.org/blog/11529/introducing-private-click-measurement-pcm/
[37]SKAN: https://developer.apple.com/documentation/storekit/skadnetwork
[38]关于 SKAdNetwork 的文档: https://developer.apple.com/documentation/storekit/skadnetwork
[39]AEM: https://www.facebook.com/business/help/721422165168355
[40]Facebook 关于 AEM 的介绍: https://www.facebook.com/business/help/721422165168355
[41]FLoC: https://web.dev/floc/
[42]《字节跳动破局联邦学习:开源 Fedlearner 框架,广告投放增效 209%》: https://www.infoq.cn/article/fi6bz7nnw2c3y8g9gpzr
[43]官网文章: https://web.dev/floc/
[44]FLoC 提案: https://github.com/WICG/floc
[45]FLoC.glitch.me: https://floc.glitch.me/
[46]这里: https://web.dev/floc/#as-a-web-developer-how-can-i-try-out-floc
[47]第二季度在 Google Ads 上测试 FLoC: https://blog.google/products/ads-commerce/2021-01-privacy-sandbox/
[48]一些安全隐患: https://finance.sina.com.cn/tech/2021-04-21/doc-ikmyaawc0951711.shtml
[49]Privacy Sandbox: https://www.chromium.org/Home/chromium-privacy/privacy-sandbox
[50]Privacy Sandbox 官网: https://www.chromium.org/Home/chromium-privacy/privacy-sandbox