
Kafka 为什么能那么快的 6 个原因
Hollis
共 6135字,需浏览 13分钟
·
2020-08-09 00:36

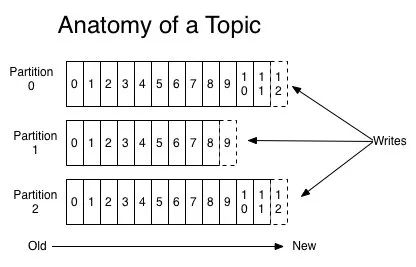
1. 利用 Partition 实现并行处理



2. 顺序写磁盘
3. 充分利用 Page Cache
I/O Scheduler 会将连续的小块写组装成大块的物理写从而提高性能 I/O Scheduler 会尝试将一些写操作重新按顺序排好,从而减少磁盘头的移动时间 充分利用所有空闲内存(非 JVM 内存)。如果使用应用层 Cache(即 JVM 堆内存),会增加 GC 负担 读操作可直接在 Page Cache 内进行。如果消费和生产速度相当,甚至不需要通过物理磁盘(直接通过 Page Cache)交换数据 如果进程重启,JVM 内的 Cache 会失效,但 Page Cache 仍然可用
flush.messages 和 flush.ms 两个参数将 Page Cache 中的数据强制 Flush 到磁盘,但是 Kafka 并不建议使用。4. 零拷贝技术
网络数据持久化到磁盘 (Producer 到 Broker) 磁盘文件通过网络发送(Broker 到 Consumer)
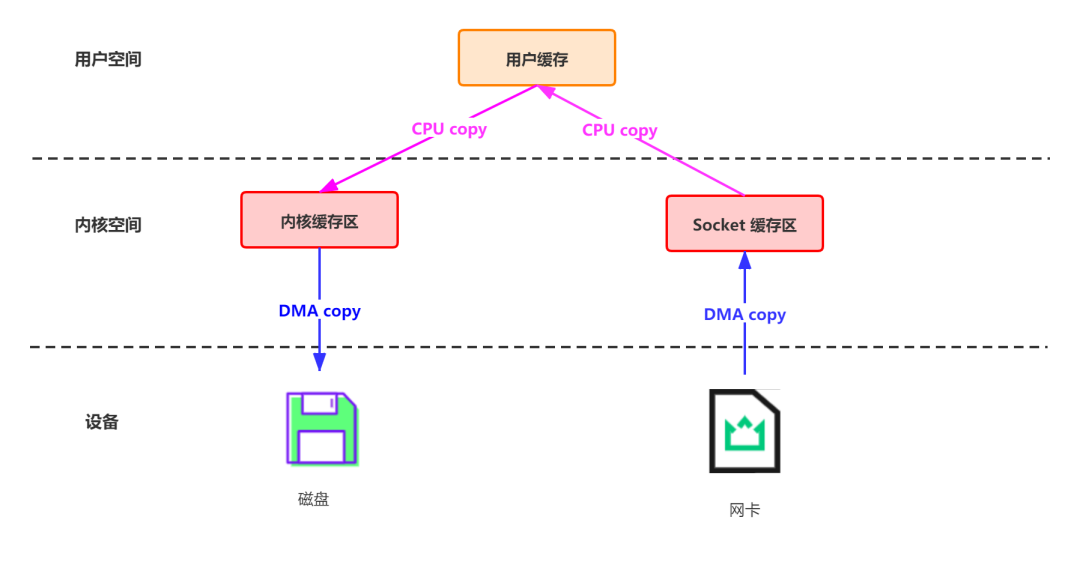
4.1 网络数据持久化到磁盘 (Producer 到 Broker)
data = socket.read()// 读取网络数据File file = new File()file.write(data)// 持久化到磁盘file.flush()
首先通过 DMA copy 将网络数据拷贝到内核态 Socket Buffer 然后应用程序将内核态 Buffer 数据读入用户态(CPU copy) 接着用户程序将用户态 Buffer 再拷贝到内核态(CPU copy) 最后通过 DMA copy 将数据拷贝到磁盘文件
特殊场景下:接收来自 socket buffer 的网络数据,应用进程不需要中间处理、直接进行持久化时。可以使用 mmap 内存文件映射。producer.type 来控制是不是主动flush;如果 Kafka 写入到 mmap 之后就立即 flush 然后再返回 Producer 叫同步(sync);写入 mmap 之后立即返回 Producer 不调用 flush 就叫异步(async),默认是 sync。
直接I/O:数据直接跨过内核,在用户地址空间与I/O设备之间传递,内核只是进行必要的虚拟存储配置等辅助工作; 避免内核和用户空间之间的数据拷贝:当应用程序不需要对数据进行访问时,则可以避免将数据从内核空间拷贝到用户空间 mmap sendfile splice && tee sockmap copy on write:写时拷贝技术,数据不需要提前拷贝,而是当需要修改的时候再进行部分拷贝。
4.2 磁盘文件通过网络发送(Broker 到 Consumer)
buffer = File.readSocket.send(buffer)
首先通过系统调用将文件数据读入到内核态 Buffer(DMA 拷贝) 然后应用程序将内存态 Buffer 数据读入到用户态 Buffer(CPU 拷贝) 接着用户程序通过 Socket 发送数据时将用户态 Buffer 数据拷贝到内核态 Buffer(CPU 拷贝) 最后通过 DMA 拷贝将数据拷贝到 NIC Buffer
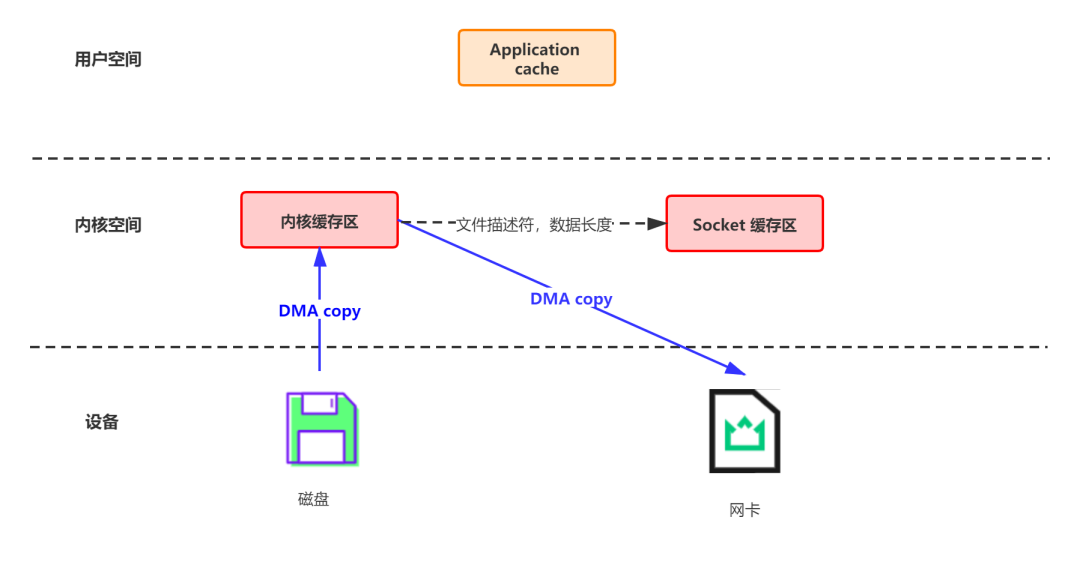
transferTo/transferFrom 调用操作系统的 sendfile 实现零拷贝。总共发生 2 次内核数据拷贝、2 次上下文切换和一次系统调用,消除了 CPU 数据拷贝5. 批处理
6. 数据压缩
小总结 | 下次面试官问我 kafka 为什么快,我就这么说
partition 并行处理 顺序写磁盘,充分利用磁盘特性 利用了现代操作系统分页存储 Page Cache 来利用内存提高 I/O 效率 采用了零拷贝技术 Producer 生产的数据持久化到 broker,采用 mmap 文件映射,实现顺序的快速写入 Customer 从 broker 读取数据,采用 sendfile,将磁盘文件读到 OS 内核缓冲区后,转到 NIO buffer进行网络发送,减少 CPU 消耗
参考资料
美团——磁盘I/O那些事: https://tech.meituan.com/2017/05/19/about-desk-io.html
[2]Kafka零拷贝: https://zhuanlan.zhihu.com/p/78335525
[3]Linux - Zero-copy(零拷贝): https://cllc.fun/2020/03/18/linux-zero-copy/
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️
评论