
概述 | 全景图像拼接技术全解析
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
前言
图像/视频拼接的主要目的是为了解决相机视野(FOV-Field Of View)限制,生成更宽的FOV图像/视频场景。视频拼接在体育直播、全景显示、数字娱乐、视频处理中都被广泛应用,同时视频/图像拼接涉及到矫正图像、对其与匹配图像、融合、统一光照、无缝连接、多尺度重建等各个图像算法模型与细节处理,可以说是图像处理技术的综合运用。特别是最近几年收到深度学习的影响,各种基于深度学习的图像对齐与拼接技术也取得了长足发展。
01
图像拼接流程
图像拼接流程主要是针对输入系列视频帧或者图像,基于像素像素或者特征点相似然后对齐图像、融合对齐之后的图像,更新全景图像拼接结果,图示如下:
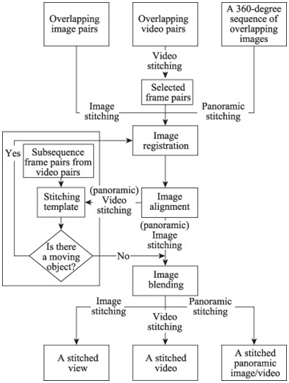
最常见就是基于SIFT/SURF/OBR/AKAZE等方法实现特征提取,基于RANSAC等方法实现对齐,基于图像融合或者无缝克隆算法实现对齐图像的拼接。
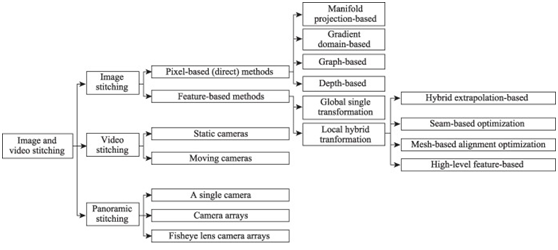
针对不同的拼接方式可以分为图像拼接、视频拼接、全景拼接。针对图像拼接可以分为像素相似与特征相似;视频拼接又分为固定相机、移动相机;全景拼接分为单相机、相机列阵、鱼眼相机列阵。图示如下:

02
深度学习方法
通过卷积神经网络CNN可以更好的学习与提取图像特征、通过语义分割获取初始匹配、然后对齐,图示如下:
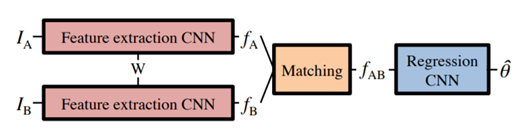
其中IA与IB是输入图像,CNN是预训练的特征提取网络模型,匹配网络与回归网络。其中匹配网络主要是计算相似程度,其网络计算方式如下:
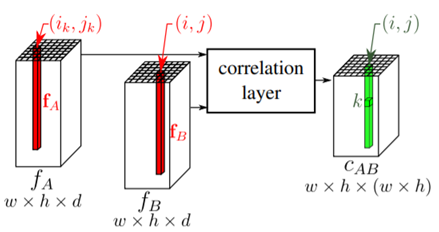
回归网络的结构如下:

评论