
OpenAI 研究员最新博客:如何在多GPU上训练真正的大模型?
共 11188字,需浏览 23分钟
·
2021-10-13 12:31

极市导读
本文回顾了几种流行的并行训练范例,以及各种模型结构和内存节省设计,使跨大量GPU训练大型神经网络成为可能。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
近年来,在大规模预训练语言模型的帮助下,许多NLP模型在基准测试任务中取得了更好的结果。如何训练大而深的神经网络是一个挑战,需要大量的GPU内存和很长的训练时间。
然而,单个GPU卡的内存有限,许多大模型的大小已经超过了单个GPU,目前,为解决此类问题,训练深且大的神经网络的主要方法有训练并行加速、各种模型架构以及内存节省设计等。常见的并行加速方法有以下几种:数据并行性、模型并行性、流水线并行以及张量平行。模型架构方面主要有专家混合(MoE)方法。此外,还有其他节省内存的设计方法,如:CPU卸载、激活重新计算、混合精度训练、压缩以及内存高效优化器等等。
本文编译自OpenAI科学家Lilian Weng(翁荔)最新博客文章(lilianweng.github.io/lil-log/2021/09/24/train-large-neural-networks.html),智源社区已经获得翻译授权
01 训练并行性
训练大模型的主要瓶颈是对大量GPU内存的强烈需求,远远高于单个GPU上的内存。大模型在训练过程中,GPU内存主要用在模型权重参数存储(例如数百亿个浮点数),中间计算输出存储(例如梯度和优化器状态,例如Adam中的动量和变化),这使得GPU成本十分昂贵。除此之外,训练一个大模型通常时通常需要与一个大型训练语料库配对,因此单个过程可能需要很长时间。
因此,并行性是必要的,同时,并行可以使用在不同的维度上,包括数据、模型架构和张量操作等。
数据并行性
数据并行性(Data parallelism (DP))最简单的方法是将相同的模型权重复制到多个worker中,并将一部分数据分配给每个worker以同时进行处理。
如果模型规模大于单个GPU的内存,Naive DP无法正常工作时。GeePS(Cui 等人,2016 年)之类的方法将暂时未使用的参数卸载回 CPU,以使用有限的 GPU 内存。数据交换传输在后端进行,且不干扰训练计算。
在每个小批量结束时,workers需要同步梯度或权重,以替换旧参数。常见有两种主要的同步方法,它们都有明确的优缺点:
1)大容量同步并行( Bulk synchronous parallels (BSP)): workers在每个小批量结束时同步数据。这种方法可以防止模型权重过时,同时获得良好的学习效率,但每台机器都必须停止并等待其他机器发送梯度。
2)异步并行(Asynchronous parallel (ASP)): 每个GPU工作进程异步处理数据,无需等待或暂停。然而,这种方法很容易导致网络使用陈旧的权重参数,从而降低统计学习效率。即使它增加了计算时间,也可能不会加快收敛的训练时间。
中间的某个地方是在每次x迭代时,全局同步梯度(x>1)。自Pytorch v1.5版(Li等人,2021年)以来,该特征在平行分布数据(DDP)中被称为“梯度累积”。Bucket 梯度计算方法避免了梯度的立即AllReduce,而是将多个梯度变化值存储到一个AllReduce中以提高吞吐量,可以基于计算图进行计算和通信调度优化。

模型并行性
模型并行性(Model parallelism: MP)目的是解决模型权重不能适应单个节点的情况,通过将计算和模型参数分布在多台机器上进行训练。在数据并行中,每个worker承载整个模型的完整副本,而在MP中,每个worker上只分配模型参数的一小部分,从而减少了内存使用和计算。
由于深度神经网络通常包含一堆垂直层,因此将一个大型模型逐层拆分感觉很简单,其中一组连续的小层被分组到一个工作层上的一个分区中。然而,通过多个具有顺序依赖性的工作线程来运行每个数据批,会导致大量的等待时间和计算资源利用率低下的问题。
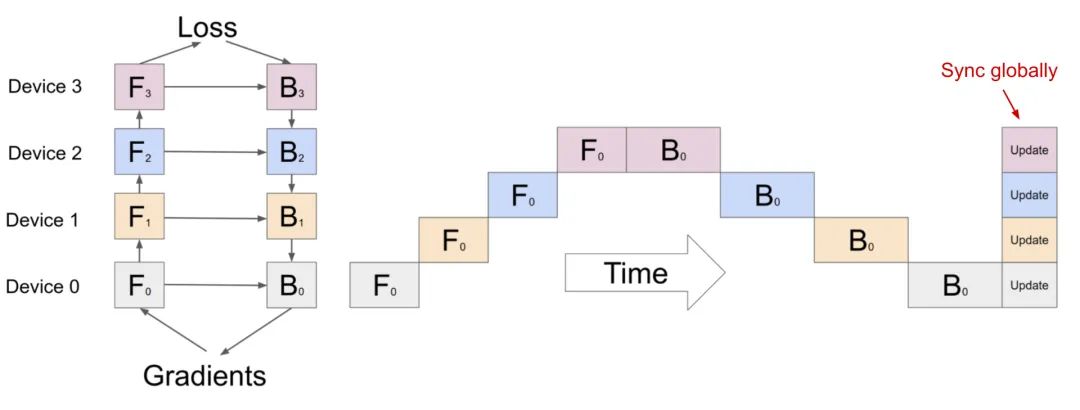
流水线并行
通道并行(Pipeline parallelism: PP)将模型并行与数据并行相结合,以减少部分训练过程中出现的空闲时间。其主要思想是将一个小批量拆分为多个微批次,并使worker在每个阶段中能够同时处理一个微批次。需要注意的是,每个微批次需要两次传递,一次向前,一次向后。worker之间的通信仅传输激活(向前)和梯度(向后)。这些通道的调度方式以及梯度的聚合方式在不同的方法中有所不同。分区(workers)的数量也称为通道深度。
在GPipe(Huang et al.2019)中,来自多个微批次的梯度在最后聚合并同步应用。同步梯度下降的操作,与workers数量无关,可以保证学习的一致性和效率。如图3所示,“间隔时间”的情况仍然存在,但比图2中的少得多。设定m为平均分割微批次和d为分区,假设每个微批次的向前和向后都需要一个单位的时间,“间隔时间”的分数为:
GPipe论文观察到,如果微组的数量超过分区数量的4倍(m>4d)(当应用激活重新计算时),则“间隔时间”几乎可以忽略不计。
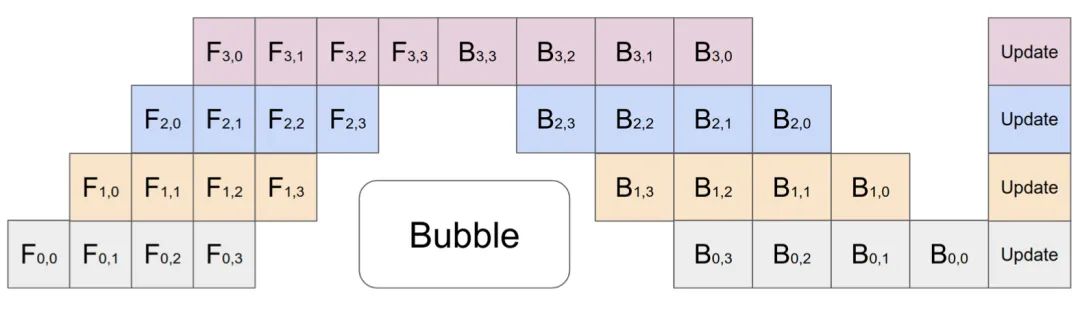
GPipe在吞吐量方面实现了几乎与设备数量成线性关系的加速,但是,当模型参数不能均匀地分布在workers中时,GPipe的方法可能会失效。
PipeDream(Narayanan等人,2019)用每个worker交替处理向前和向后传递(1F1B)。
PipeDream将每个模型分区命名为“阶段”,在这个过程中,PipeDream使用确定性循环负载平衡策略在多个阶段副本之间分配工作,以确保同一个小批量的前向和后向传递发生在同一个副本上。
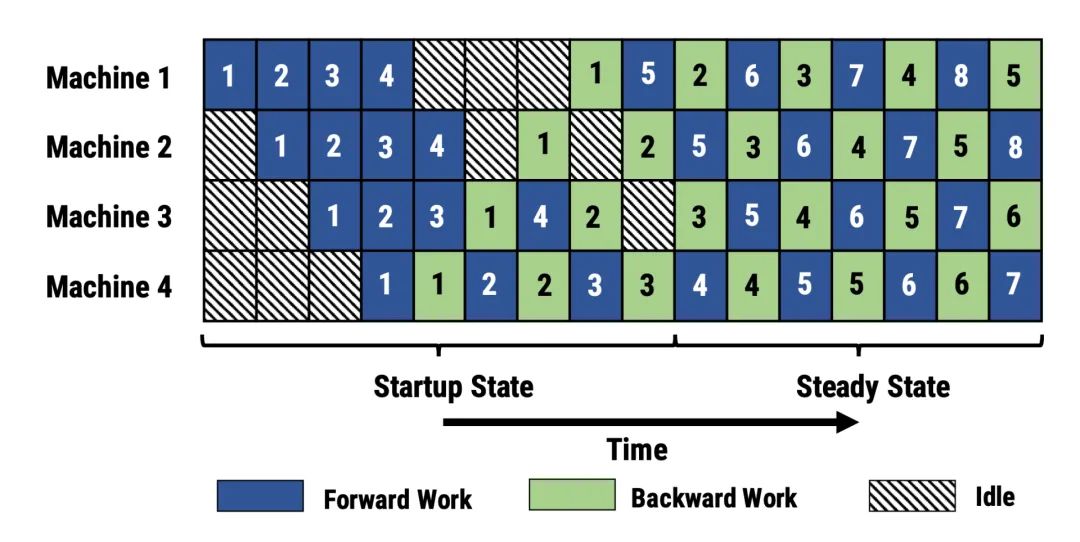
由于PipeDream没有在所有workers之间进行批处理结束后执行全局梯度同步操作1F1B 的原生实现很容易导致一个 microbatch 使用不同版本的模型权重进行前向和后向传递,从而降低学习效率。
PipeDream提出了一些解决此问题的设计:
1)权重存储:每个worker跟踪多个模型版本,并确保在给定一个数据批次的前向和后向传递中使用相同版本的权重。
2)垂直同步(可选):模型权重的版本与激活和梯度一起在不同阶段的workers之间流动。然后计算采用从前一个worker传播的相应隐藏版本。此过程可保持workers之间的版本一致性。需要注意的是,这种方法是异步的,与 GPipe 不同。
在训练运行开始时,PipeDream首先分析模型中每个层的计算内存成本和时间,然后,优化将层划分为阶段的解决方案,这是一个动态规划问题。
Narayanan等人提出了PipeDream的两种变体,通过隐藏模型版本来减少内存占用(Narayanan等人,2021年)。
PipeDream-flush添加一个全局同步的通道更新操作,就像GPipe一样。这种方法虽然会造成吞吐量的能力部分下降,但是大大减少了内存占用(即只维护一个版本的模型权重)。
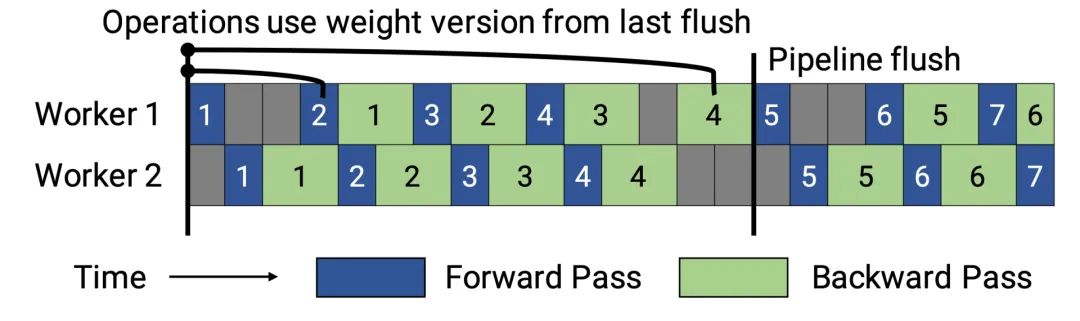
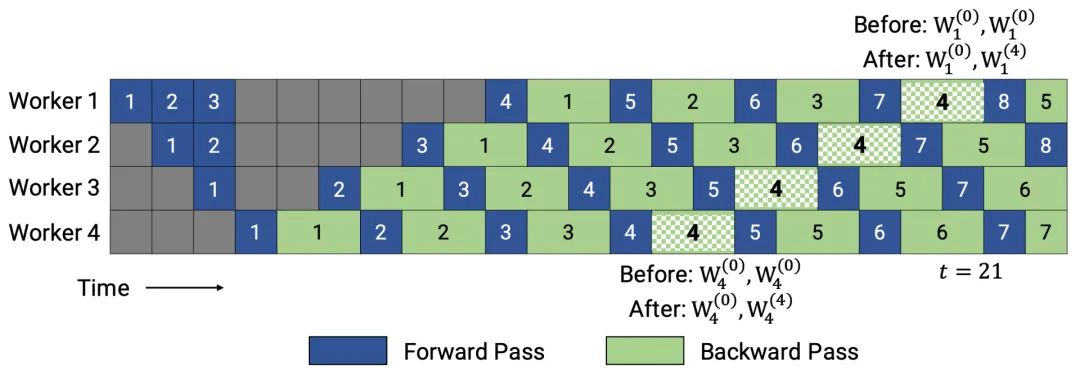
PipeDream-2BW仅维护两个版本的模型权重,其中“2BW”是“双缓冲权重”的缩写。它每k个微批次生成一个新的模型版本,并且k应大于通道深度(d,k>d)。由于一些剩余的向后传递仍然依赖于旧版本,新更新的模型版本无法立即完全替换旧版本,所以整个过程中总共只需要保存两个版本,因此内存成本大大降低。
张量平行
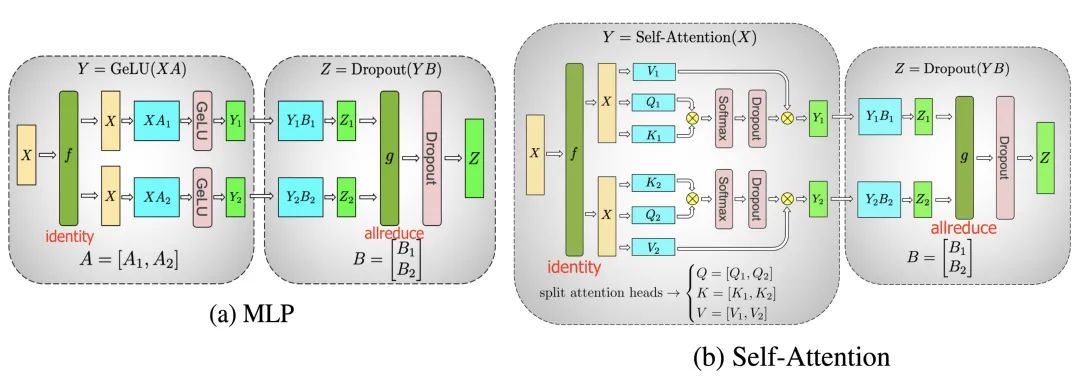
模型并行和流水线并行都将一个模型垂直分割,可以将一个张量操作的计算水平分割到多个设备上,称为张量并行(tensor parallelism,TP)。
以当下比较流行的transformer为例,transformer模型主要由多层MLP和自我注意块组成。Megatron-LM(Shoeybi et al.2020)等人采用了一种简单的方法来并行多层计算MLP和自我注意。变压器中的MLP层包含GEMM(通用矩阵乘法)和非线性GeLU传输,按列拆分权重矩阵A:
Split
注意块根据上述分区并行运行带有查询(Q)、键(K)和值权重(V)的GEMM,然后将它们与另一个GEMM组合以生成注意头结果。
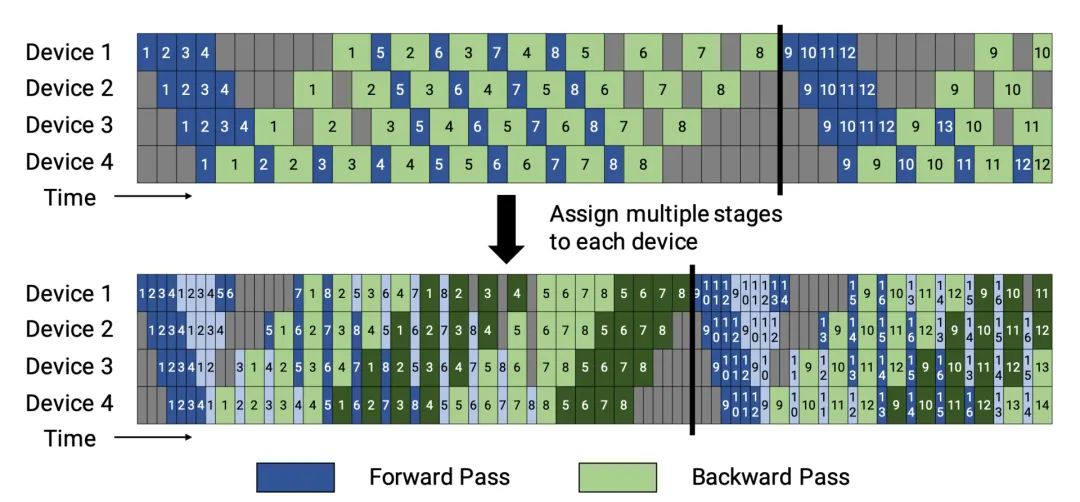
Narayanan等人(2021年)将通道、张量和数据并行性与一种新的通道调度策略相结合,并将其方法命名为PTD-P。不仅可以在设备上定位一组连续的层(“模型块”),还可以为每个worker分配多个较小的连续层子集块(例如,设备1有第1、2、9、10层;设备2有第3、4、11、12层;每个层有两个模型块)。一个批次中的微批次数量应精确除以worker数量(m),如果每个worker有v个模型块,与GPipe调度相比,通道间隔时间可以减少v倍。
02 专家混合(MoE)
专家混合(MoE)方法最近吸引了很多关注,因为研究人员(主要来自谷歌)试图突破模型大小的限制。该想法的核心是整合学习:多个弱学习模型组合以后会形成能力出众的学习模型。
Shazeer 等人于2017年发表了名为“稀疏门控专家混合”(MoE)层的文章,提出了在一个深度神经网络中可以通过连接多个专家的门控机制来实现输出控制的方法。门控机制可以控制网络中需要激活的子集(例如哪些专家)以产生输出。一个MoE层中包含:
1)n作为专家的前馈网络
2)A是一个可训练的门控网络G,用于学习n个专家的概率分布,以便将流量路由到几个选定的专家。
根据门控输出,不是每一个专家都必须被评估,当专家的数量太大,可以考虑使用两个层次的MoE。
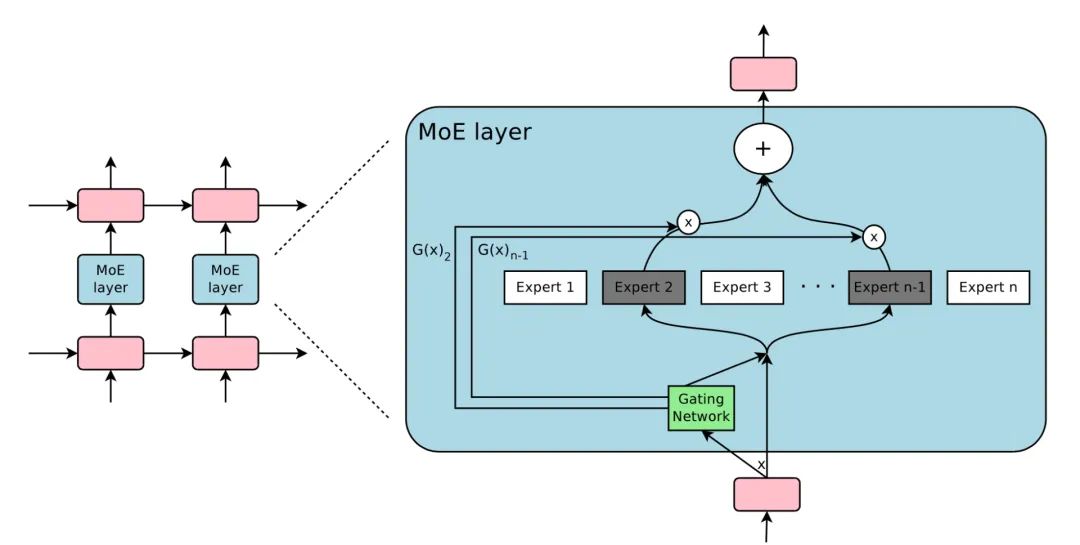
G的一种计算方法可以是将输入与可训练权重矩阵 相乘, 然后进行 操作。然而,这会产生一个用于门控的密集控制向量并且会浪费部分计算资源, 因为网络不需要仅在 时评估专家。因此,MoE层仅保留topk值, 它还将可调高斯噪声添加到G中以改善负 载平衡, 这种机制称为嘈杂top-k门控机制。
其中, 表示向量 的第i维。函数 通过将其他维设置为来选择 具有最高值的顶层k维。
为了避免门控网络可能始终有利于少数强势专家的自增强效应,Shazeer等人(2017)提出了一种通过额外重要性损失的软约束,以鼓励所有专家具有相同的权重。它相当于每个专家的分批平均值变异系数的平方:
其中CV 是变异系数,而损失权重是要调整的超参数。
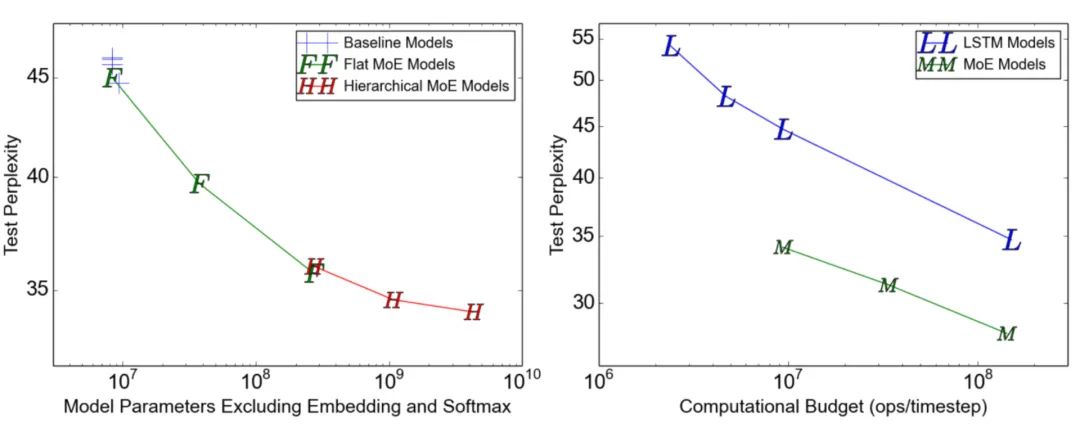
由于每个专家网络只获得一小部分训练样本(“收缩批量问题”),在MoE中应尽量使用大批量数据。但是,它受到GPU内存的限制,可以应用数据并行和模型并行来提高吞吐量。
GShard(Lepikhin等人,2020年)通过分片将MoE transformer模型的参数扩展至6000亿。MoE transformer用MoE层替换其他每一个前馈层。分片MoE transformer仅将MoE层分片到多台机器上,而其他层只是复制。
GShard中的门控功能G有几种改进设计:
1)专家能力: 通过一位专家的代币数量不应超过称为“专家能力(expert capacity)”的阈值。如果令牌被路由到已达到其容量的专家,令牌将被标记为“溢出”并且门控输出更改为零向量。
2)本地组调度: 令牌被均匀地划分到多个本地组中,并在组级别上强制执行专家能力。
3)Auxiliary loss: 动机类似于原来的 MoE aux loss,添加了一个辅助损失来最小化路由到每个专家的数据部分的均方。
4)随机路由: 以与其权重成正比的概率选择第二好的专家;否则,GShard 遵循随机路由,以增加一些随机性。

Switch Transformer(Fedus et al.2021)通过将密集前馈层替换为稀疏交换FFN层(其中每个输入仅路由到一个专家网络),将模型规模扩展到数万亿个参数。负载平衡的辅助损失是给定的n专家,其中是路由到第i个专家的令牌的分数,是门控网络预测的专家i的路由概率。
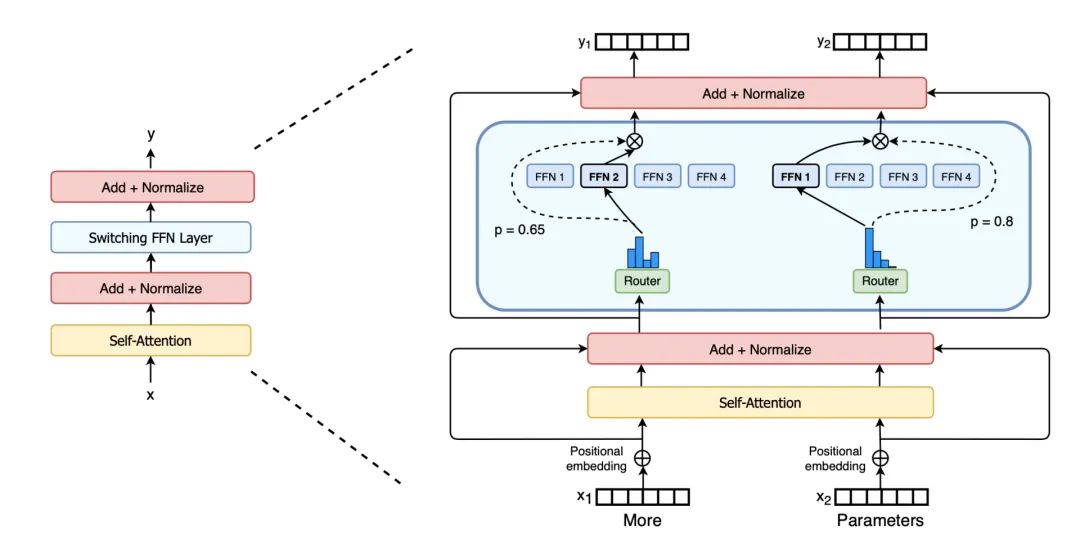
为提高训练稳定性,Switch Transformer采用以下设计:
1)可选择的精度。 选择性地仅将模型的局部部分投射到 FP32 精度可以提高稳定性,同时避免 FP32 张量昂贵的通信成本。FP32 精度仅在路由器函数的主体内使用,结果将重组为 FP16。
2)较小的初始化。 权重矩阵的初始化是从均值 和标准偏差 的截断正态分布中采样。同时,将Transformer初始化比例参数 s=1 减少到 s=0.1。
3)使用更高的专家剔除机制。 微调通常适用于小数据集, 为避免过度拟合,每个专家的剔除率都会显着增加。作者发现所有层的 dropout 增加会导致性能不佳,在论文中,作者在非专家层使用了 0.1 的剔除率,但在专家 FF 层中使用了 0.4。
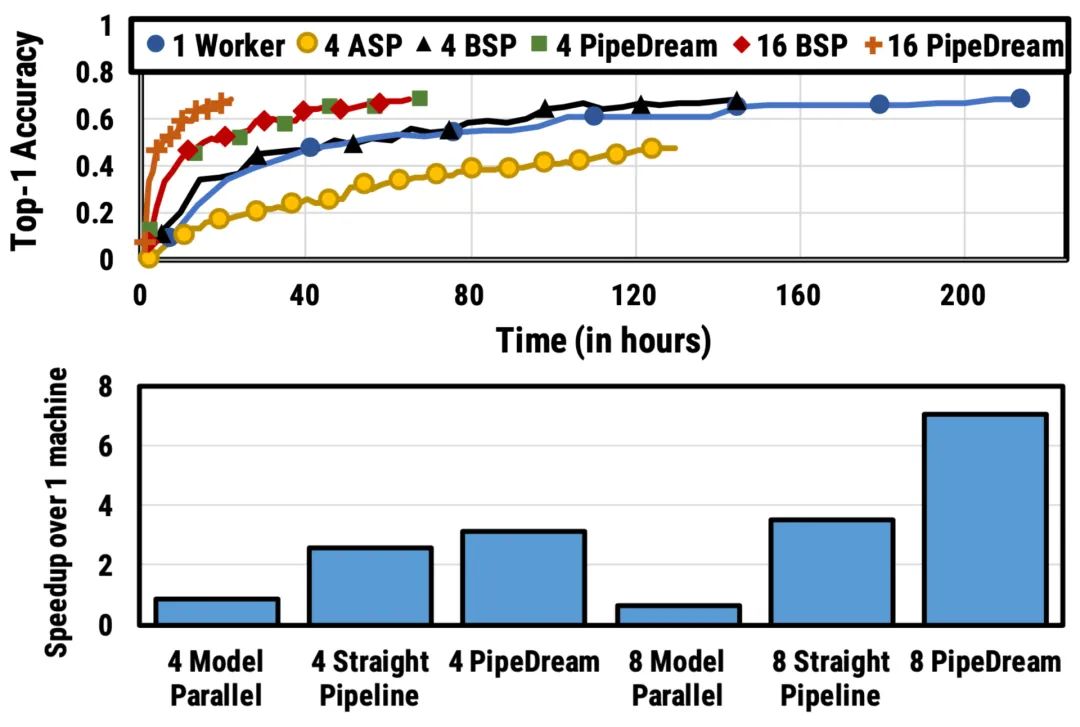
switch transformer论文总结了用于训练大型模型的不同数据和模型并行策略,并给出了一个很好的示例:
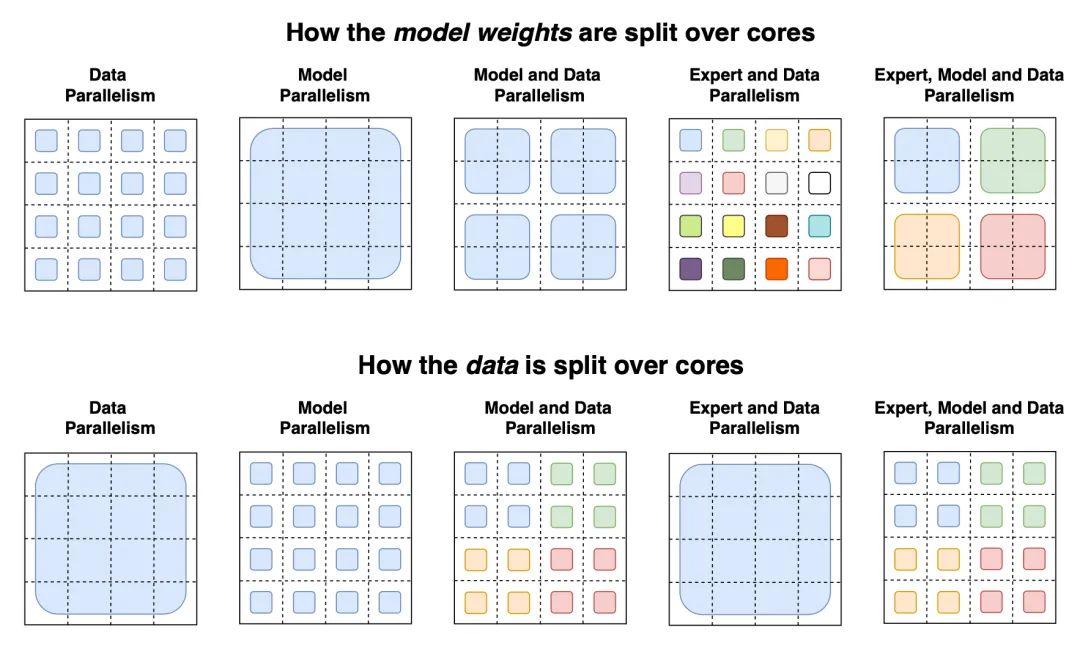
03 其他节省内存的设计
CPU卸载
当GPU内存已满时,一种选择是将暂时未使用的数据卸载到CPU,并在以后需要时将其读回(Rhu等人,2016)。数据卸载到CPU 的想法很简单,但由于它会延长训练时间,所以近年来不太流行。
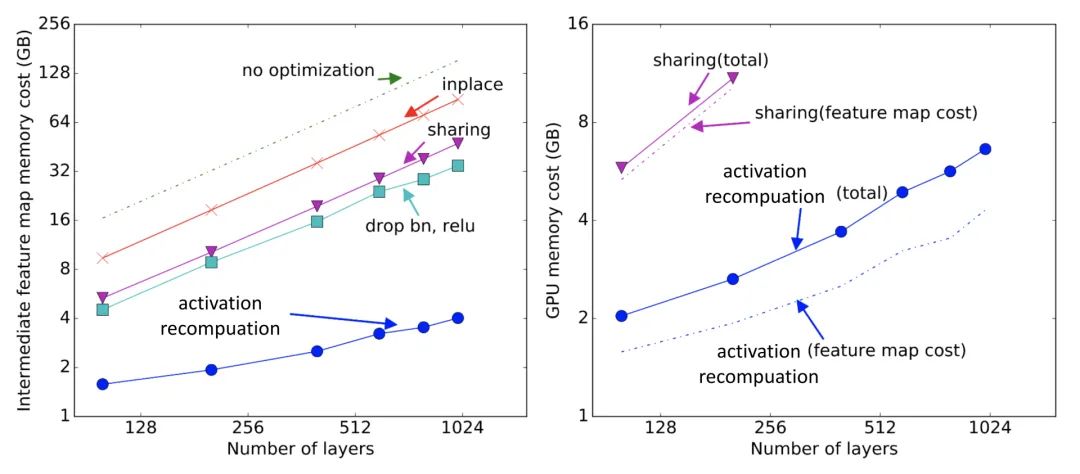
激活重新计算
激 活 重 新 计 算 ( Activation recomputation (also known as "activation checkpointing" or "gradient checkpointing", Chen 等 人,2016 年 (https://arvix.org/abs/1604.06174)) 是一个以计算时间为代价减少内存占用的聪明而 简单的想法。它将训练层深度神经网络的内存成本降低到 ,每批仅额外消耗额外的前向传递计算。例如,将一个层网络平均分为d分区。只保存分区边界处的激活, 并在 workers之间进行通信, 计算梯度仍然需要分区内层的中间激活, 因此在向后传递过程中重新计算梯度,使用激活重新计算。训练 的内存成本为:
最低成本为 处的 。激活重编译技巧可以给出与模型大小有关的次线性内存成本。
混合精度训练
Narang&Micikevicius等人(2018年)介绍了一种使用半精度浮点(FP16)数字训练模型而不损失模型精度的方法。
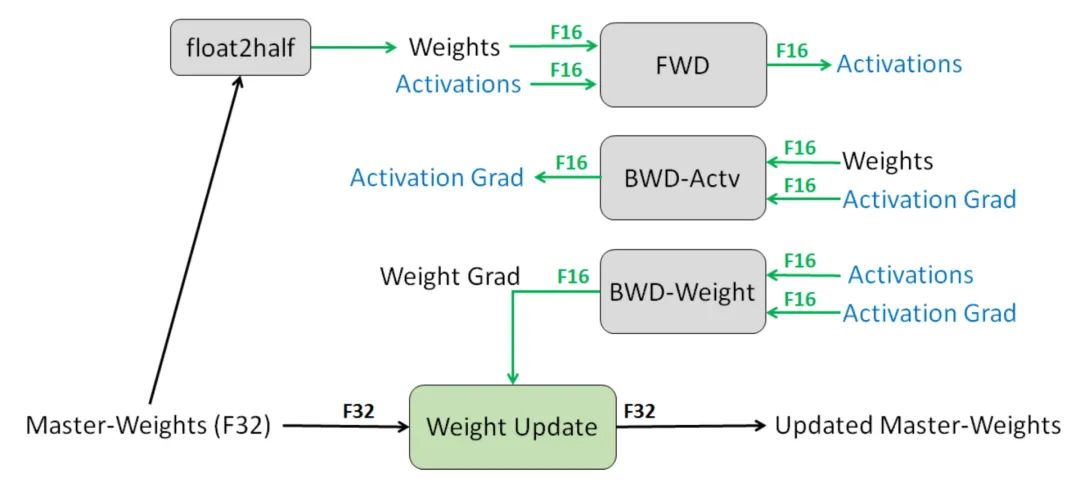
三种避免以半精度丢失关键信息的技术:
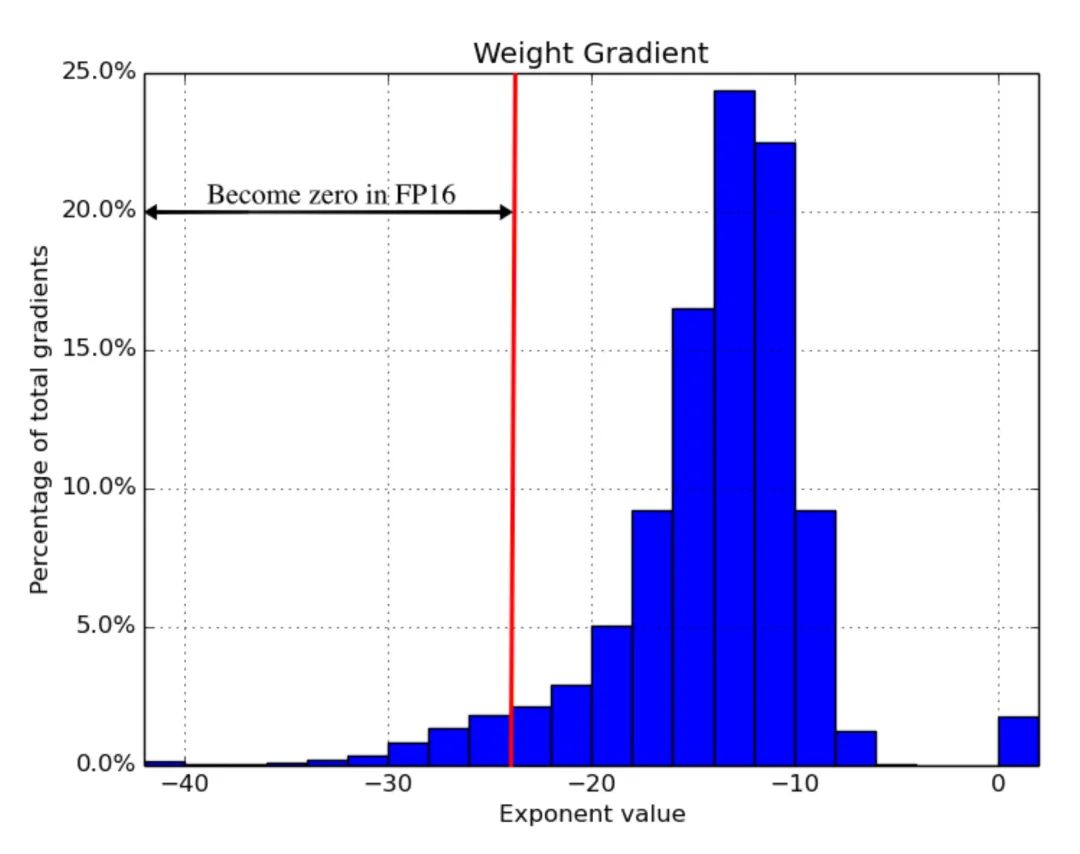
1)全精度原始权重。维护累积梯度的模型权重的全精度 (FP32) 副本, 对于向前和向后传递,数字四舍五入到半精度。主要是为了防止每个梯度更新(即梯度乘以学习率)可能太小而无法完全包含在 FP16 范围内(即 2-24 在 FP16 中变为零)的情况。
2)损失缩放。扩大损失以更好地处理小幅度的梯度(见图 16), 放大梯度有助于将权重移动到可表示范围的右侧部分(包含较大值)占据更大的部分,从而保留否则会丢失的值。
3)算术精度。对于常见的网络算法(例如向量点积,向量元素相加减少),可以将部分结果累加到 FP32 中,然后将最终输出保存为 FP16,然后再保存到内存中。可以在 FP16 或 FP32 中执行逐点操作。
在上述文章的实验中,某些网络(例如图像分类、Faster R-CNN)不需要损失缩放,但其他网络(例如 Multibox SSD、大型 LSTM 语言模型)则需要。
压缩
中间结果通常会消耗大量内存,尽管它们只在一次向前传递和一次向后传递中需要。这两种使用之间存在明显的时间差距。因此Jain等人(2018年)提出了一种数据编码策略,将第一次使用后的中间结果在第一次传递中进行压缩,然后将其解码回来进行反向传播。
Jain等人的系统Gist中,包含两种编码方案:特定于层的无损编码;专注于ReLU池(“二进制化”)和ReLU Conv(“稀疏存储和密集计算”)模式。激进的有损编码;使用延迟精度降低(DPR)。作者观察到,第一次立即使用特征图应该保持高精度,但第二次使用可以使用较低的精度。
实验表明,Gist可以在5个SOTA图像分类DNN上减少2倍的内存成本,平均减少1.8倍,而性能成本仅为4%。
内存高效优化器
优化器内存消耗。以流行的 Adam 优化器为例,它内部需要保持动量和方差,两者都与梯度和模型参数处于同一规模,但是需要节省 4 倍的模型权重内存。
已经提出了几种优化器来减少内存占用。例如,Adafactor(Shazeer 等人,2018 年)不是像 Adam 那样存储完整的动量和变化,而是仅跟踪移动平均线的每行和每列总和,然后根据这些总和估计二阶矩。SM3 (Anil et al. 2019) 描述了一种不同的自适应优化方法,也导致内存大幅减少。
ZeRO(Zero Redundancy Optimizer;Rajbhandari et al.2019)根据对大型模型训练的两个主要内存消耗的观察,优化用于训练大型模型的内存:
1)大多数由模型状态占据,包括优化器状态(例如,Adam动量和方差)、梯度和参数。混合精度训练需要大量内存,因为优化器需要保留FP32参数和其他优化器状态的副本,FP16版本除外。
2)剩余的被激活、临时缓冲区和不可用的碎片内存(论文中称为剩余状态)消耗。
ZeRO 结合了两种方法,ZeRO-DP 和 ZeRO-R。ZeRO-DP 是一种增强的数据并行性,可避免模型状态上的简单冗余。它通过动态通信调度跨多个数据并行进程划分优化器状态、梯度和参数,以最小化通信量。ZeRO-R 使用分区激活重新计算、恒定缓冲区大小和即时内存碎片整理来优化剩余状态的内存消耗。
引用为:
@article{weng2021large,
title = "How to Train Really Large Models on Many GPUs?",
author = "Weng, Lilian",
journal = "lilianweng.github.io/lil-log",
year = "2021",
url = "https://lilianweng.github.io/lil-log/2021/09/24/train-large-neural-networks.html"}
参考文献:
本文亮点总结
1)全精度原始权重。2)损失缩放。3)算术精度。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
