
用于场景文字擦除的文字区域条件生成对抗网络
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达

一、研究背景
图 1 场景文字擦除的例子:(a)包含文字内容的图片,(b)经过文字隐藏后的图片
当我们拍摄照片的时候,我们偶然会拍摄到一些敏感的文字信息,如车牌号码,地理位置,门牌号码等,这些图片如果上传到网上可能会导致隐私泄露的问题。因此文字信息隐藏对于保护个人隐私是一个重要的任务。
二、方法介绍
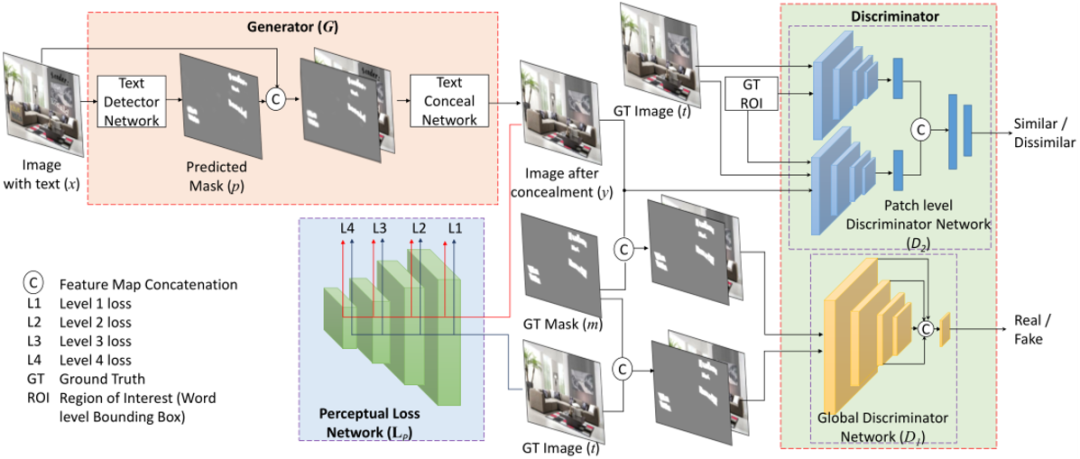
图 2 整体框架
网络的整体框架如图2所示,它由两部分构成:生成器和判别器。生成器负责两个任务,分别是文字检测和文字擦除。其中文字检测网络用于文字区域的分割,文字区域的分割可以帮助擦除网络去区分文字的区域和非文字的区域。判别器由全局判别器(D1)和Patch Level的判别器(D2)构成,全局的判别器用于判断生成图片的真或假,Patch Level的判别器用于确保局部区域的正确性。
2.1 文字检测网络
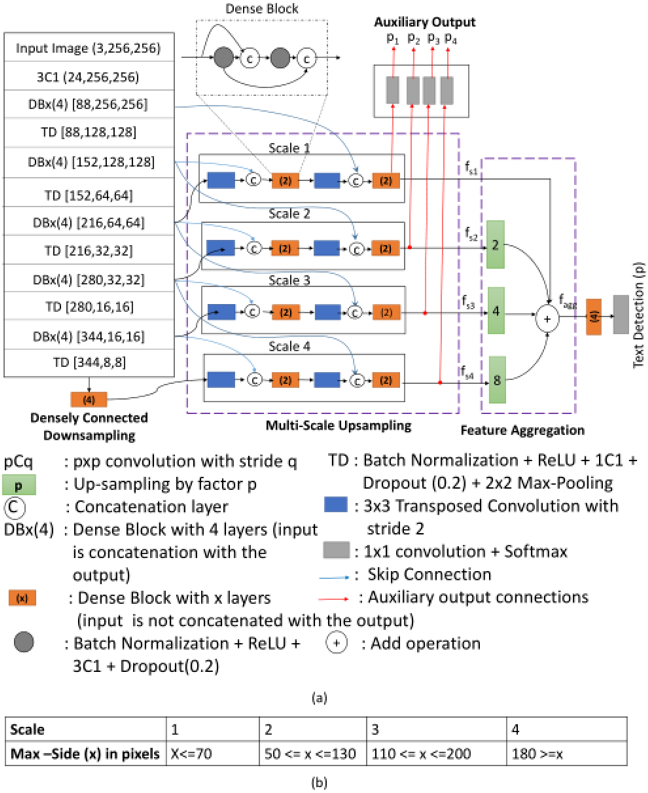
图 3(a)文字检测网络的结构,(b)表格所示为,根据字符最大边的长度,分别分配给不同尺度的输出分支
受启发于Tiramisu结构[1],作者采用了基于分割的方法去预测文字的区域。如图3(a)所示,网络由三部分构成:密集连接的下采样、多尺度的上采样、特征的聚集。下面将分别介绍这些模块。
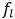 是第
是第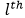 层的输出,密集连接使用了前面所有层的特征去计算第层的输出,表示如下:
层的输出,密集连接使用了前面所有层的特征去计算第层的输出,表示如下: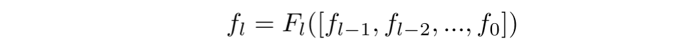
其中 表示BN层、激活函数、卷积层和Dropout层的结合。
表示BN层、激活函数、卷积层和Dropout层的结合。
多尺度的上采样:多尺度的上采样模块包含了四个分支,每个分支使用了下采样过程中的不同层的特征,并通过结合密集连接块和上采样单元进行上采样。另外,不同尺度的字符会单独输入到相应的分支进行预测,其中字符的大小范围和对应的分支如图3(b)所示。分支的输出被称为辅助输出,每个辅助输出都预测三个类别,分别是文字、背景和字符的边界。
特征的聚集:对上采样过程中不同尺度分支的输出进行融合。
对称线字符表示:如图4所示,字符的对称线表示,是通过连接字符的中心点,到边界的中心点而构成的。并且为了避免相邻字符的对称线重合,作者还缩小了这些对称线。因此,对称线以内的区域被认为是文字的区域,而对称线以外的区域被认为是不关注的区域。在仅使用字符框标注的训练数据情况下,这种表示方法能够帮助网络,获得更细致的像素级文字分割结果。
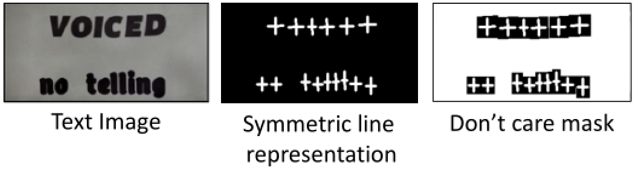
图 4 文字的对称线表示和不关注的Mask
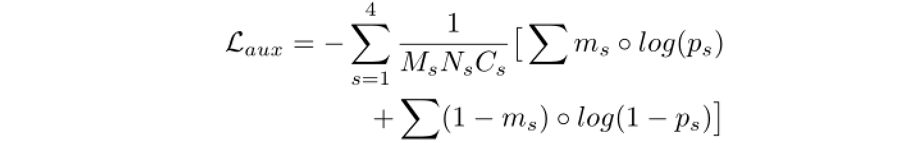
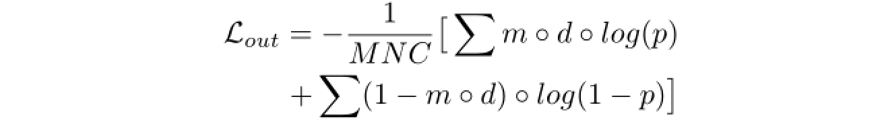
其中d表示的是不关注的Mask。
2.2 文字擦除网络
文字擦除网络用于擦除场景中的文字,文章中采用的是U-Net[2]结构的网络。网络的整体结构如图5所示,网络的输入是原图和文字分割Mask的拼接,文字的分割Mask可以帮助网络擦除文字,并且忽略非文字的区域。文字擦除网络所使用的损失函数是L1损失和感知损失。
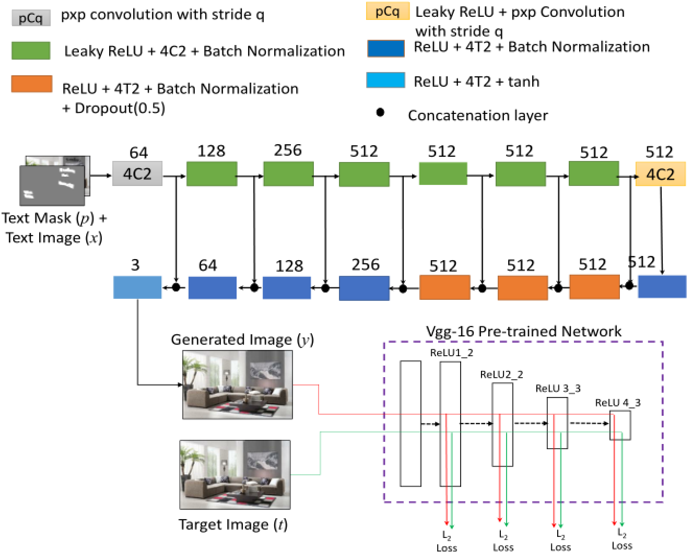
图 5 文字擦除网络的结构
2.3 全局判别器和Patch Level判别器
文章结合了全局判别器(D1)和Patch Level的判别器(D2)进行判别器的设计。全局的判别器用于判断生成图片的真或假,Patch Level的判别器用于确保局部区域的正确性。
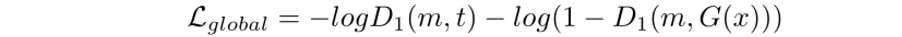
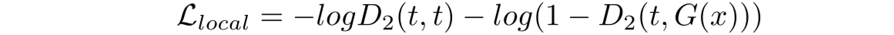
三、主要实验结果及可视化效果
作者分别通过文字检测的方法和图像质量评估的方法,对比了所提出方法的擦除性能。并且通过消融实验验证了各模块的有效性。
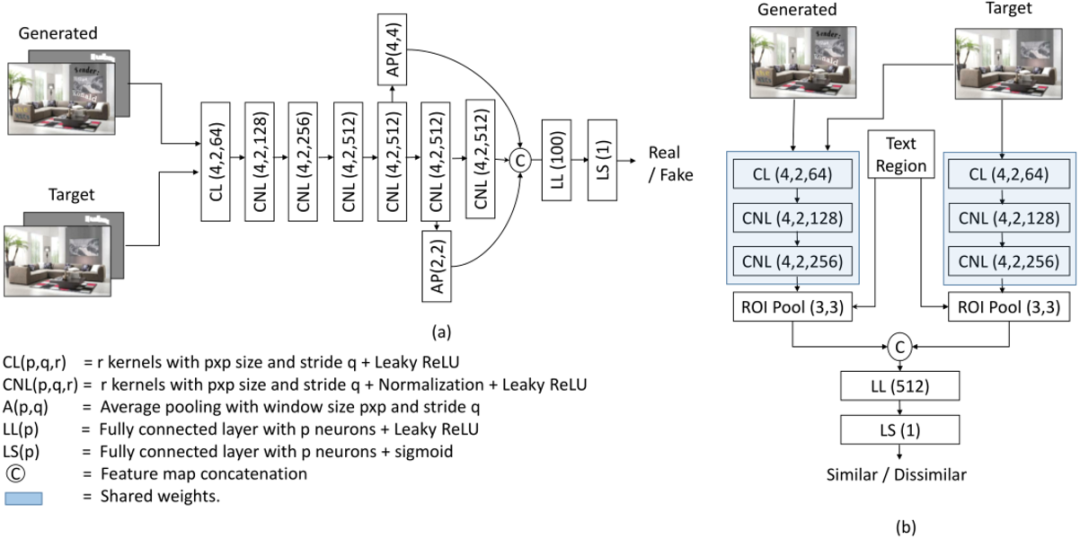
表1 文字擦除后检测指标的对比
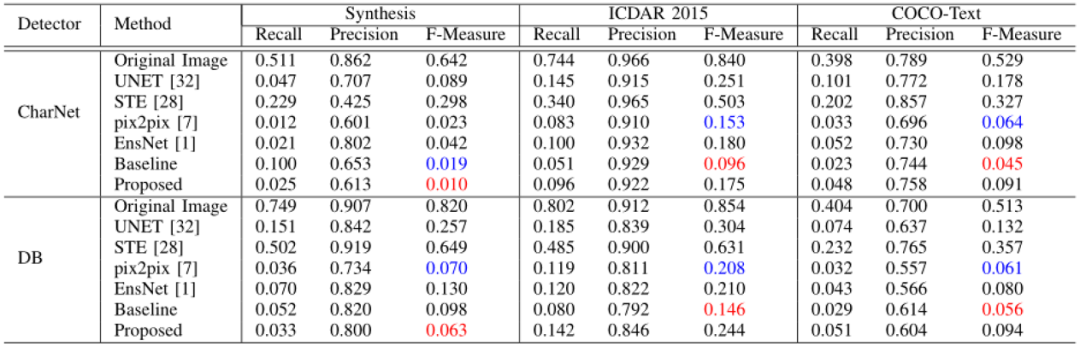
表2 图像质量指标的对比
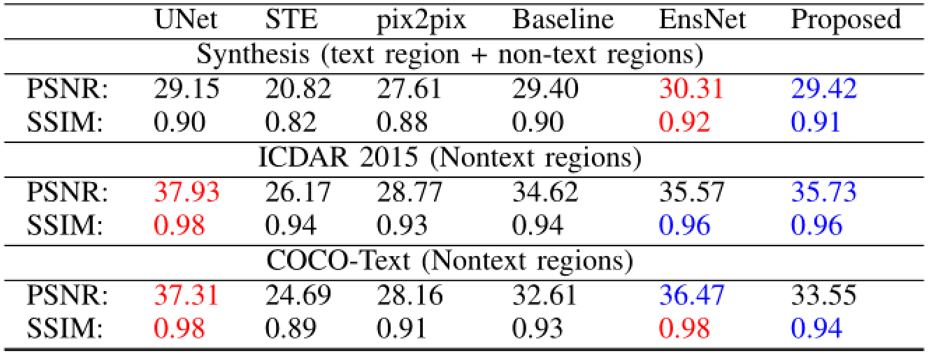
表3 各模块的消融实验
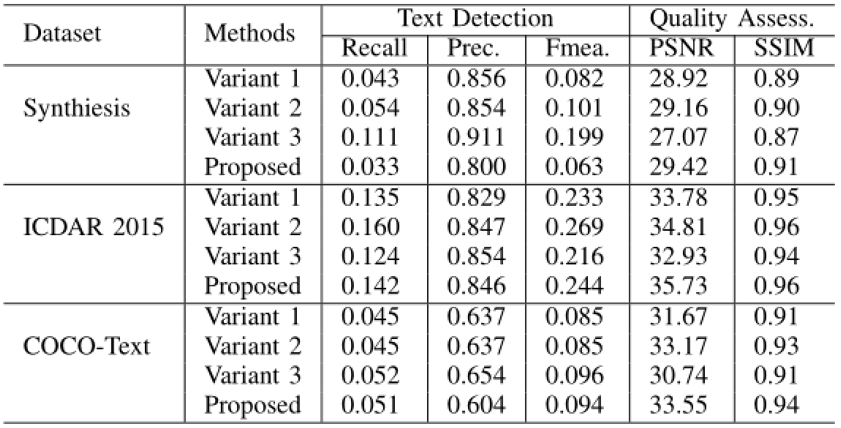

图 7 可视化不同方法的擦除效果

四、总结
五、相关资源
论文地址:
https://ieeexplore.ieee.org/abstract/document/9509541
参考文献
原文作者: Prateek Keserwani, Partha Pratim Roy
撰稿:黄宇浩
免责声明:(1)本文仅代表撰稿者观点,撰稿者不一定是原文作者,其个人理解及总结不一定准确及全面,论文完整思想及论点应以原论文为准。(2)本文观点不代表本公众号立场。
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
