
Velox 概览 | Velox: 现代化的向量化执行引擎
共 8473字,需浏览 17分钟
·
2022-02-20 14:13
今天来聊一下Meta去年开源的一个新的数据执行引擎:Velox。按照官方的说法:
听起来有点模糊,特征不鲜明的感觉。我给Velox的定义是: 一个现代化的向量化执行引擎。现代化意思是说它会充分利用最新的一些硬件特性比如AVX指令集;向量化则体现Velox整个执行模型是向量化的。目前有关Velox的信息还不是很多,只有官方网站里面的一些文档以及代码。因此这篇文章大概70%来自官方文档,30%来自对Velox代码的阅读以及我自己的思考总结。
Before Velox
从Velox代码里面的很多痕迹可以看出这个项目是起源于Presto的,很多概念的封装比如Task/Driver/Split, 跟Presto都是一样的; 再比如Operator定义的方法的签名都跟Presto一样,因此我们理解一下Meta在Presto上的优化历程有助于我们理解为什么会有Velox这个项目。Meta针对Presto的优化比较大的有Aria Presto, Presto Unlimited和Presto on Spark。
Aria Presto
Aria Presto是为了提升TableScan效率的一个项目,他们发现在生产环节中60%的时间是花在了TableScan上面,因此对TableScan进行优化很有意义。它主要做了下面几项优化:
Stream Reader: 他们优化了ORC Reader,使得它除了做TableScan之外还可以进行一些简单filter的过滤,这样可以使得从TableScan读出来的数据量降低。
Subfield Pruning: 如果查询需要从一个struct里面读出其中的一个字段,老的实现会把整个结构读出来再丢弃不需要的信息,而新的架构会只读需要的字段。
Adaptive Filter Ordering: 在执行filter的时候,有的过滤条件比别的过滤条件过滤度高,Presto会根据过滤度动态对filter的执行顺序进行调整。
Effective Row Skipping: 老的实现如果查询在一个列上已经把一些数据过滤掉了,但是在读取其它列的时候还是会读出来所有的数据,然后马上又丢弃掉,非常浪费CPU,而新的实现则直接不去读取这些不需要的数据。
Presto Unlimited
Presto Unlimited 简单来说是在Presto上实现了简单的类似MapReduce的机制。我们知道Hive里面的Bucketed Table的概念,它是把数据按照一个hash函数进行切分成不同的文件,然后查询的时候根据要查询的数据进行同样的hash,然后可以只访问某个文件而不是全部文件从而提升性能。而且bucket之间是独立的,因此一整个查询可以切分成针对一个个bucket的子任务,这样如果某个子任务失败,我们可以单独重试这个子任务,而不需要重试整个SQL。但是如果表不是bucketed table就做不了上面的优化了。
Presto Unlimited的做法是它把SQL执行划分成多个stage之后,会把Stage之间的中间结果按照SQL Join Key落地成bucketed临时表 -- 即使原始表不是bucketed table,这样后续部分的SQL Plan就可以得到上面说的bucketed table的执行效果,降低对内存的需求的同时也提高了稳定性。
Presto on Spark
Presto on Spark的出现是因为Meta的同学觉得在Presto做各种优化其实本质是为了把Presto搞的更稳定,更高效,对内存需求更少,而这个Spark都已经做过了,比如稳定性方面Spark会在task层面做各种自动重试的,比如内存方面,Spark天然就会把中间结果落盘,与其花费更多的人力和金钱在Presto上面把所有这些特性都再做一遍还不如直接把Presto跑在Spark上算了,也就是底层执行引擎用Spark,而上层的业务语意比如SQL语意用Presto。这个项目据说在Facebook内部生产环境也有一些应用了,但是从目前社区的流行度来看应该也用的不多。
从上面Presto的发展脉络并且结合Velox的一些公开资料我们可以看出Meta开始做Velox大概有两个原因:
Meta内部主要引擎是Presto和Spark,因此有个诉求是抽象一个公共的执行层,对它的优化对所有引擎都可以用。相比把一个引擎(Presto)基于另外一个引擎(Spark)来搞,还是搞一个公共的执行层比较好。
经过对Presto的一系列优化之后,Meta的同学认为持续在整个Java软件栈进行优化性价比已经不高了。Presto用Java语言开发,还是有一些天然的限制,比如GC压力,比如对于内存无法做一些更精细的控制,比如通过输入输出参数内存复用来实现Zero Copy。
因此有了Velox。
Velox功能简介
Velox的功能边界是这样的:

它不是一个end-to-end的面向用户的SQL执行引擎,它的输入是一个逻辑执行计划,输出是用户结果,其它执行引擎可以通过内嵌Velox来进行数据执行加速的目的,它提供如下的功能:
类型系统: 支持简单类型(int, string), 以及复杂嵌套类型: struct, map, array
向量系统:跟Apache Arrow兼容的列式内存格式,支持Flat, Dictionary, Constant, Sequence/RLE, Bias等编码格式。
表达式执行:完全向量化的表达式执行引擎。
内置函数:一整套遵从presto/spark语意的函数。
算子(Operator): 实现了数据处理常见的算子:TableScan,Projection,Filtering,GroupBy,OrderBy, Shuffle,HashJoin, Unnest等等。
I/O: 提供了一个通用的插件体系可以支持不同的文件格式(ORC/DWRF/Parquet), 以及不同的存储服务。
Network Serializer: 提供了一个接口来支持不同的网络通信协议,现在支持了PrestoPage和Spark的UnsafeRow。
资源管理:提供了memory arena, buffer manangement, tasks, drivers, thread pool, spilling, caching等等用来管理计算资源的primitives。
Velox提供的东西很多,我写这篇文章主要的出发点主要是Velox说自己很快,我想看看它到底为什么快,因此我会顺着这个主线来介绍其中的相关的几个部分,讲这些之前就要先说说我理解的向量化引擎是怎么样的一个概念。
我理解的向量化引擎
在介绍向量化之前,先讲讲在向量化之前执行引擎是怎么样的:
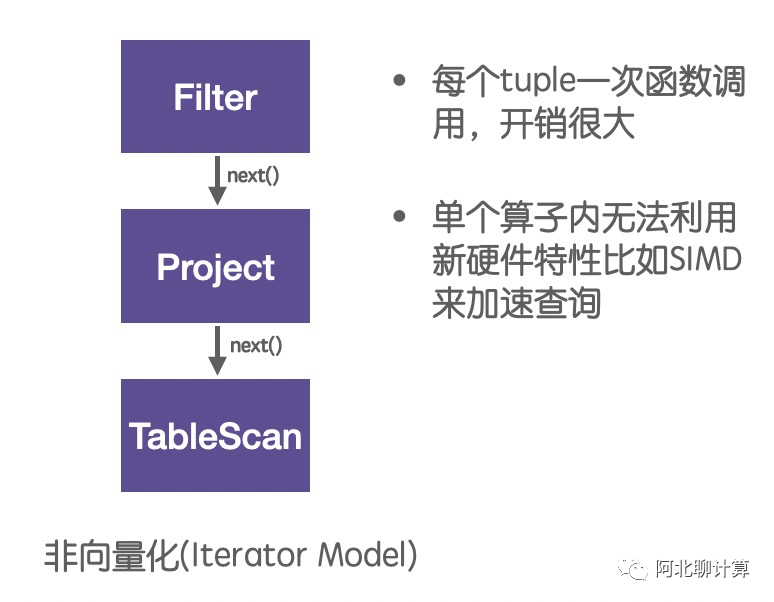
这是一个典型的Iterator模型,执行计划里面的每个算子通过调用下一个算子的next()方法来获取数据,数据被从最底层的Table里面一条一条的读取处理最终返回给客户,它的问题在于每个tuple都要调用一次函数,调用开销太大,而且因为每次只处理一条数据,无法利用新硬件的特性比如SIMD。
针对这种模型的改进有几种方法,今天我们会主要聚焦在向量化:
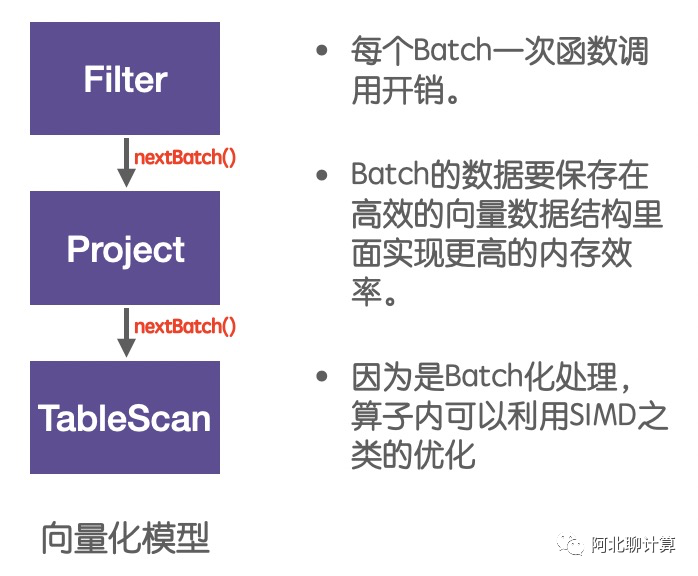
向量化模型每次处理的是一批数据,这些数据会被保存在一种叫做向量的数据结构里面,然后因为每次处理的是一批数据,因此在这每个Batch内部可以做各种优化。因此我总结向量化引擎为:
向量化引擎 = 高效的向量数据结构(Vector)
+ 批量化处理模型(nextBatch)
+ Batch内性能优化(SIMD etc)
下面我们就从这三个方面分别探究一下Velox是怎么做的。
高效的向量数据结构
跟Presto类似,Velox计算需要用到的内存都是从一个MemoryPool里面分配出来的,MemoryPool分配出来的一块连续的内存是以一个叫做Buffer的对象持有维护,而在这个Buffer对象之上就是Velox构建的各种高性能的Vector数据结构了。
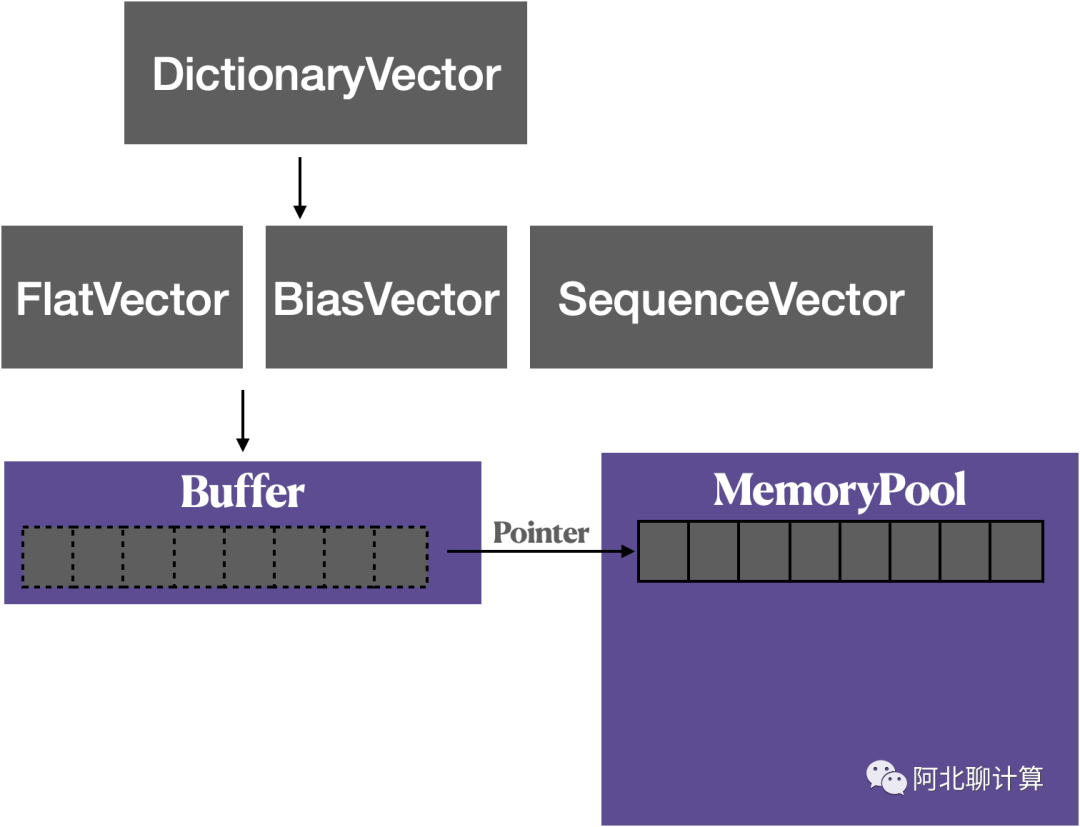
根据要保存的数据类型以及使用的场景,Velox支持下面的这些Vector:
FlatVector: 最基础的Vector,就是把数据简单的保存在里面。
BiasVector: 数据的值都很接近,利用base + offset的形式保存来降低内存占用。
SequenceVector: 这个名字不是很好,背后利用的Run-Length Encoding来降低内存占用。
DictionaryVector:利用字典编码,在distinct value远小于数据条数的时候可以降低内存占用。
除了这些编码的区别,在同一个Vector保存不同数据(保存int VS 保存一个struct)也是有一些区别的,下面分别介绍一下。
FlatVector
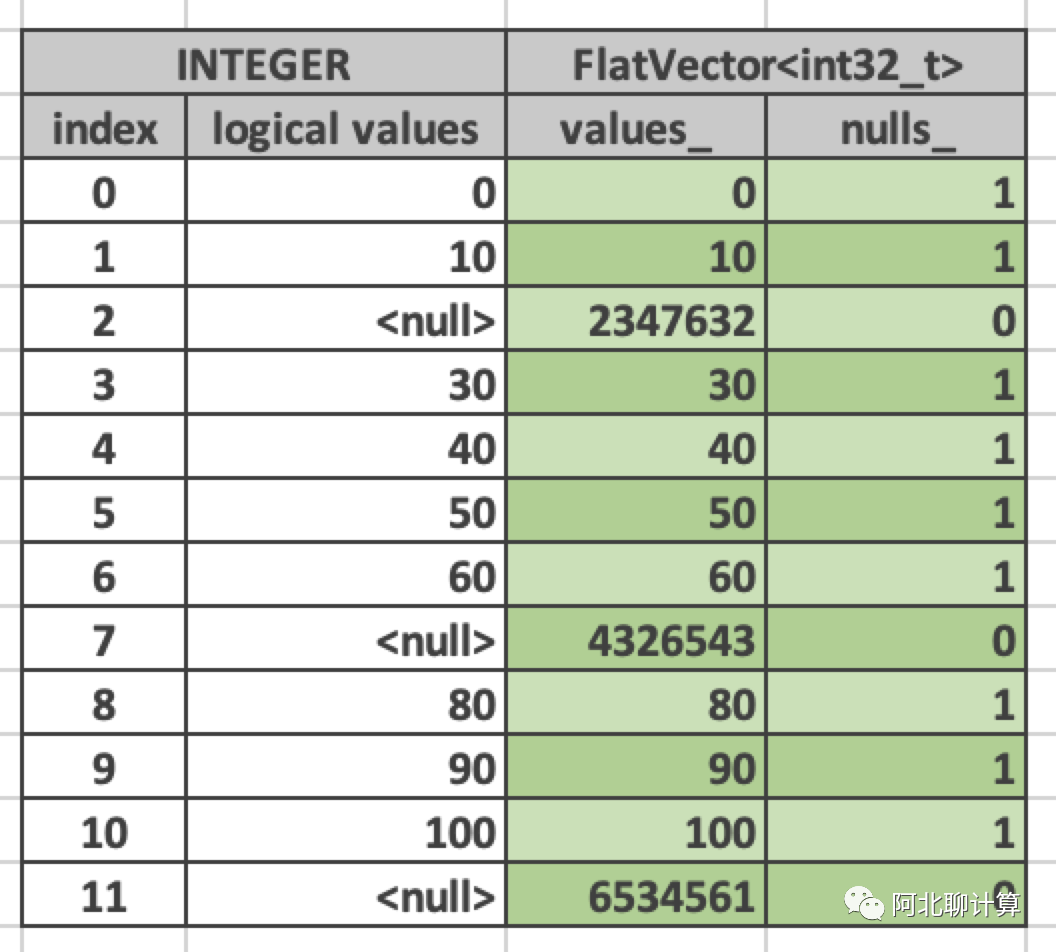
FlatVector由两部分组成:
values_: 真实值。
nulls: 每个值是否是null的bitmap,这个bitmap其它所有类型的Vector也都有。可以用它来进行关于nullness的快速的check。
BiasVector
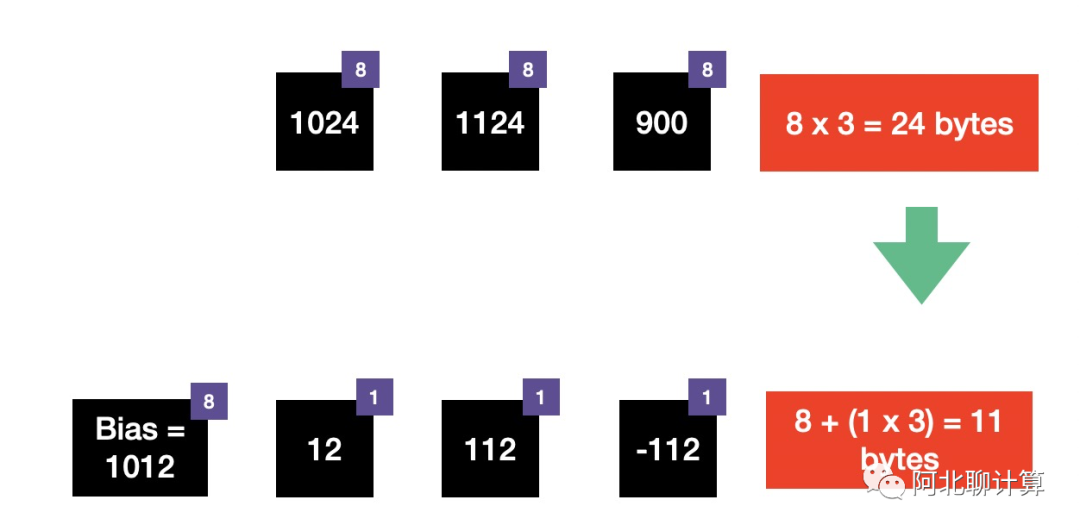
如果保存的数据在一定的范围内, 比如上面的例子里面最大值 - 最小值 < 255,那么通过保存 bias + offset,而不是保存所有的原始值来达到降低内存占用的目的。这里bias = 1012, 然后所有的元素不再保存实际值,而只保存与bias的offset,这样每个值只需要一个byte即可,因此总内存占用也从之前的24bytes降低到了11bytes。
SequenceVector
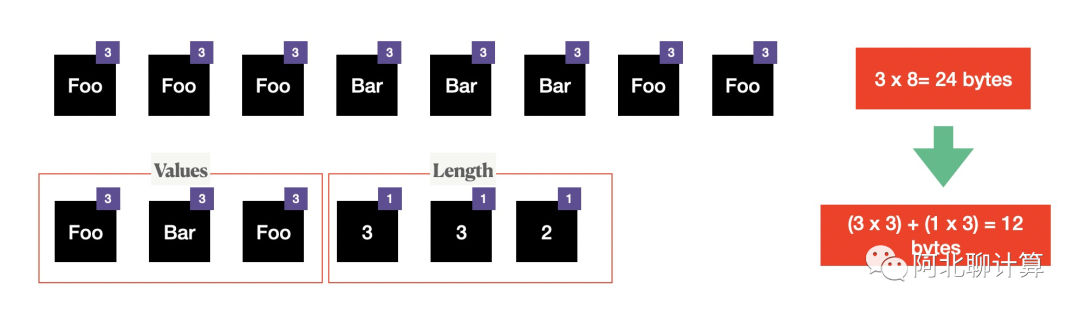
因为数据有这种连续出现的特性,利用Run-Length Encoding的特性,上面例子里面我们可以把内存占用从24bytes降低到12bytes。
DictionaryVector
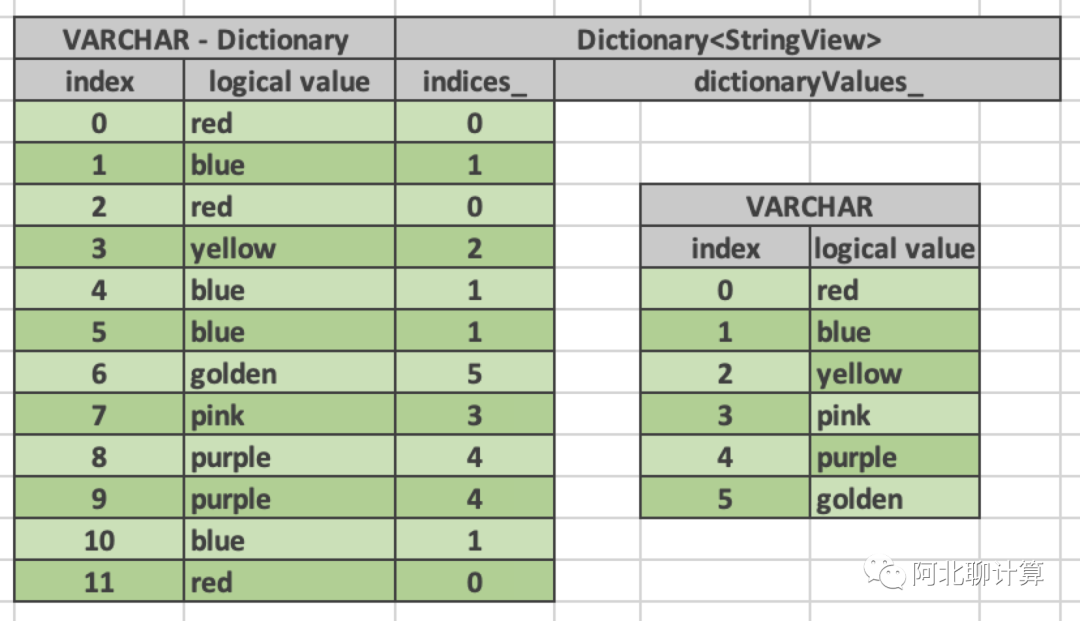
DiconaryVector是内部又嵌了一个Vector的二层结构(上图中的VARCHAR), 这个内嵌的Vector一般保存的是底层的distinct的数据,而DictionaryVector在外围维护了新一层的映射,让用户看到一个新的从底层Vector映射出来的Vector。它是Velox非常核心的一个数据结构,很多内存Zero Copy是通过它来实现的。
先说一个简单的例子,也就是上面示意图里面的例子,我们有一个数据集里面包含了关于颜色的记录,总的记录数可以有很多,比如10亿,但是颜色的唯一值却不多,在上面的例子里面只有6种,那么利用DictionaryVector,我们不需要保存所有的10亿纪录,我们只需要保存6条颜色值的数据,然后上层再建立这10亿条数据到这些真正颜色值的映射。这样比直接保存10亿个颜色值肯定要节省大量的内存。
再来一个例子,上面的例子是通过小的真实数据量来表达大量的逻辑数据的例子,下面我们来展示一个通过截取大量数据的一部分来表示少量逻辑数据的例子。
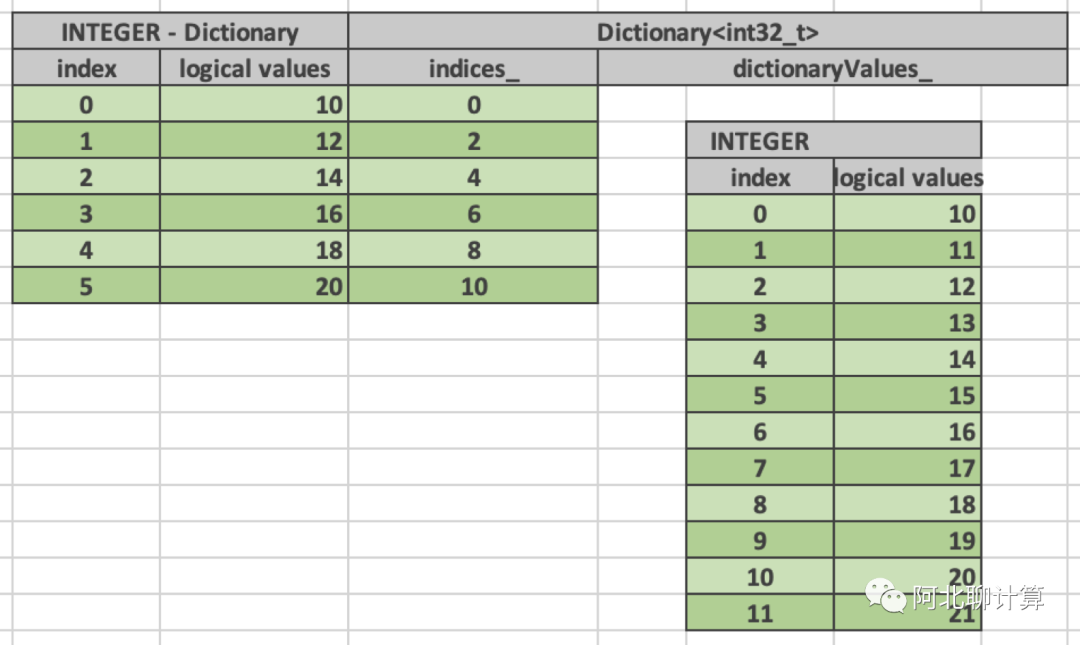
这里底层的vector含有12条数据,但是逻辑层面这个vector对用户可见的只有6条数据,这种做法的场景基本是为了做zero copy,这个底层的vector可能是用户的输入,然后经过一个表达式让我们找出其中符合某个条件的所有输入,那么剩下的数据肯定比输入少,这个时候我们可以通过使用DictionaryVector来复用输入数据的内存。
上面介绍了Vector的编码方式,下面再介绍一下几种复杂类型数据是怎么保存在Vector里面的。
ArrayVector
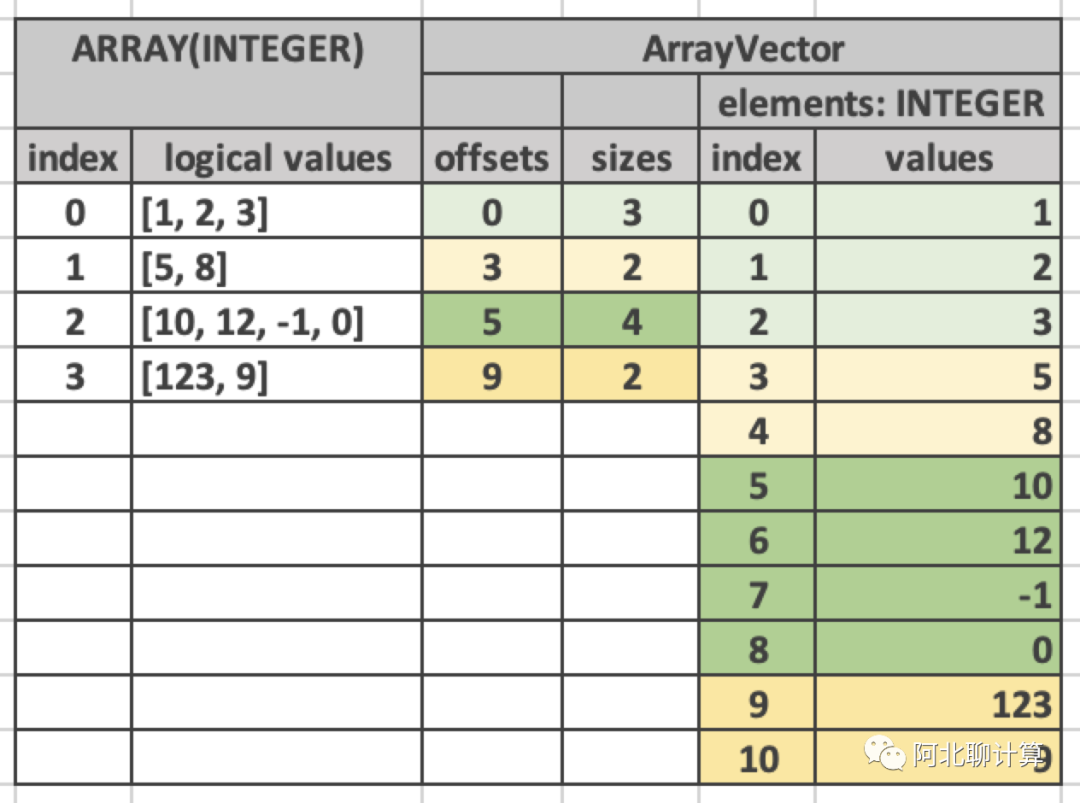
ArrayVector里面的每个元素都是一个Array,底层其实是把所有的Array打平放到一个总的Array,然后每个元素纪录在这个总的Array里面的offset + size即可。
RowVector
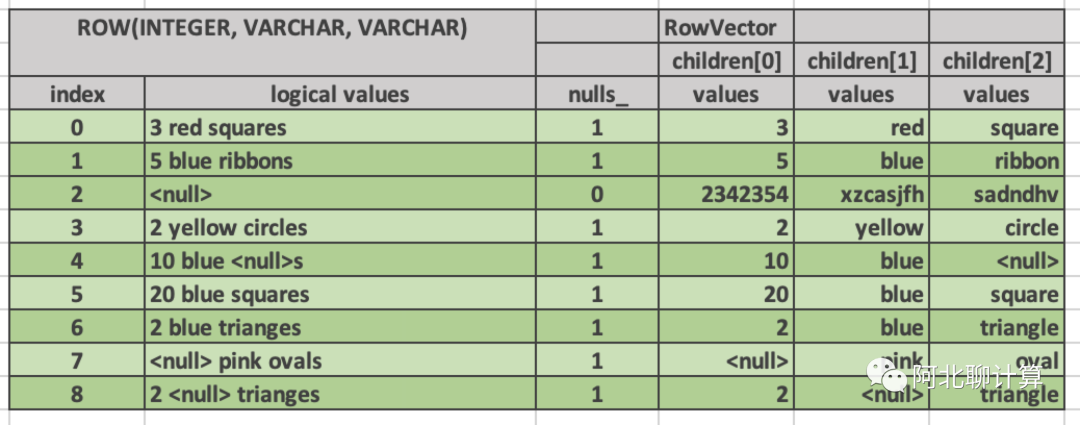
RowVector用来表达SQL里面的一行数据的Vector了,它的实现方式是对于每个column保存一个单独的children[i]字段,组合起来就是一个Row。
稍微总结一下,看这些各种不同的Vector类型,我想到了RoaringBitmap,也是类似的思路,根据数据的特征,底层选用不同的Container(Array/Bitmap/Run)来保存, 来实现对于内存最大的节省。这其中DictionaryVector很关键,Velox里面很多地方通过大量使用DictionaryVector来避免数据拷贝。
批量化的执行模型
这一块比较简单,没有太多好说的,我们可以看一下Velox的Operator定义:
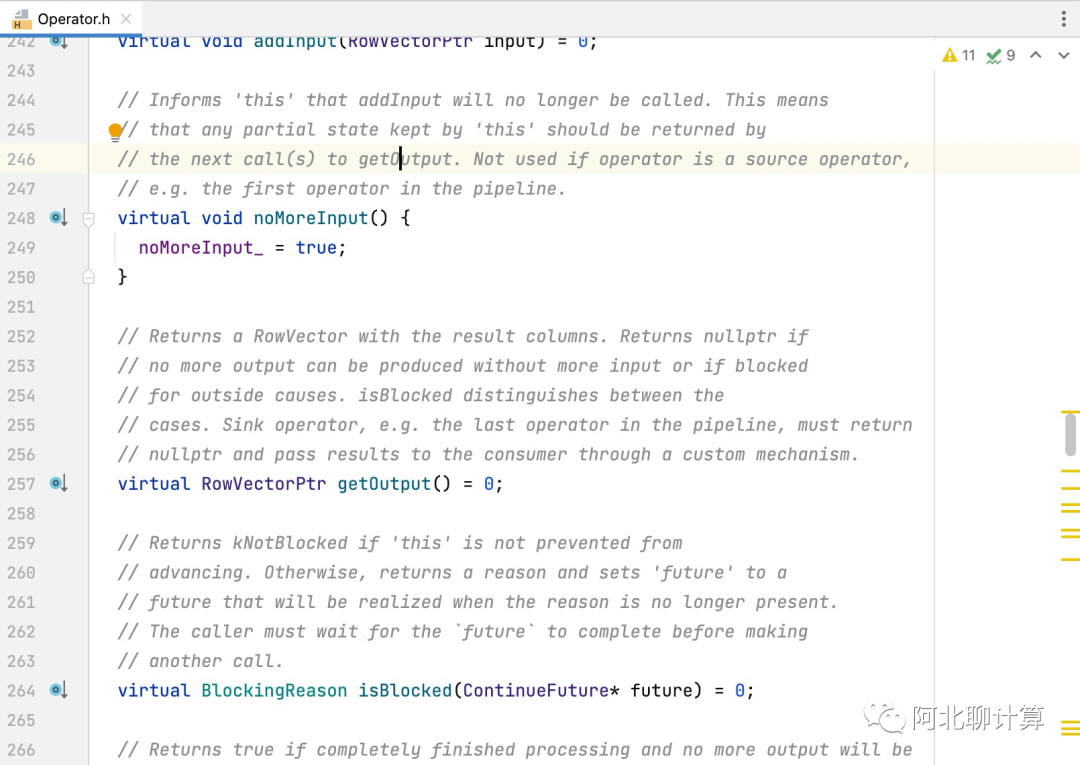
从这里可以看到两点,一是这个getOutput方法,就相当于我们上面说的 `nextBatch` 是批量化的,而且数据是保存在上面介绍的向量数据结构里面的。另外一个点是如果大家对Presto代码熟悉的话,这几个核心API的定义跟Presto几乎一样。
执行模型是批量化的了,但是如果你底层执行的还是还是一条一条执行,那还是不行,因此下面我们会介绍在一个批次内,表达式、函数等等是怎么执行的。
Batch内的性能优化
当一个算子拿到一批输入数据的时候这个数据是被保存在一个Vector里面的,那这一个Vector数据是怎么被高效计算产生输出数据的呢?这里以表达式的执行以及Zero Copy的例子来说明一下Velox在这方面的工作,
表达式的执行过程
表达式的的执行会被包含在FilterProject这个算子里面,每个表达式会被编译成一个Expr Tree,比如下面的表达式:
upper(a) > upper(‘Foo’)会被编译成下面的这样一个树形结构:
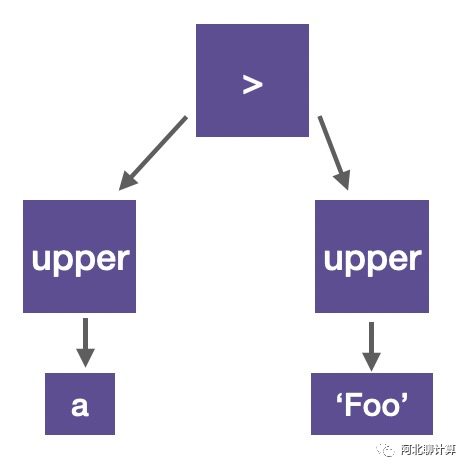
当一个表达式执行的时候它的流程大概是这样的:
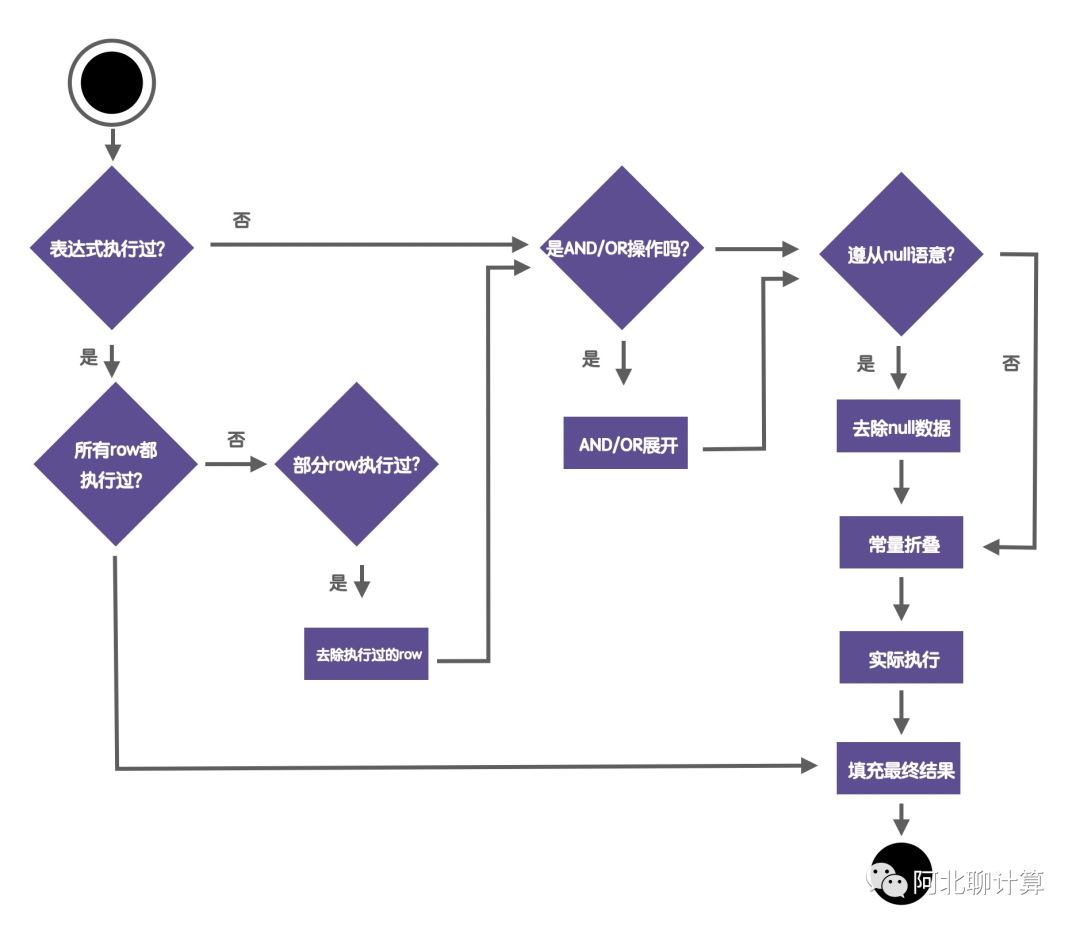
首先第一步是检查当前表达式是否已经执行过。因为表达式是一个树形结构,整个执行的过程是一个递归的过程,因此有可能现在要执行的当前子树已经执行过了,比如 (A + 5) / ((A + 5) + 6) 这里的 A + 5就被重复执行了,那么在执行第二个 A + 5的时候就可以不用执行了,直接用前面的结果。当然不是每个表达式都是这么理想的,有可能虽然某个表达式确实执行过,但是被执行的输入数据跟当前的输入数据不完全一样,那么我们要把到底执行过哪些输入识别出来,然后从输入里面去掉,只保留没有执行过的输入,从而提高性能。
第二步是看看当前要执行的是否是AND/OR操作,如果是的话,并且是嵌套的结构的话,我们可以把他们展开:
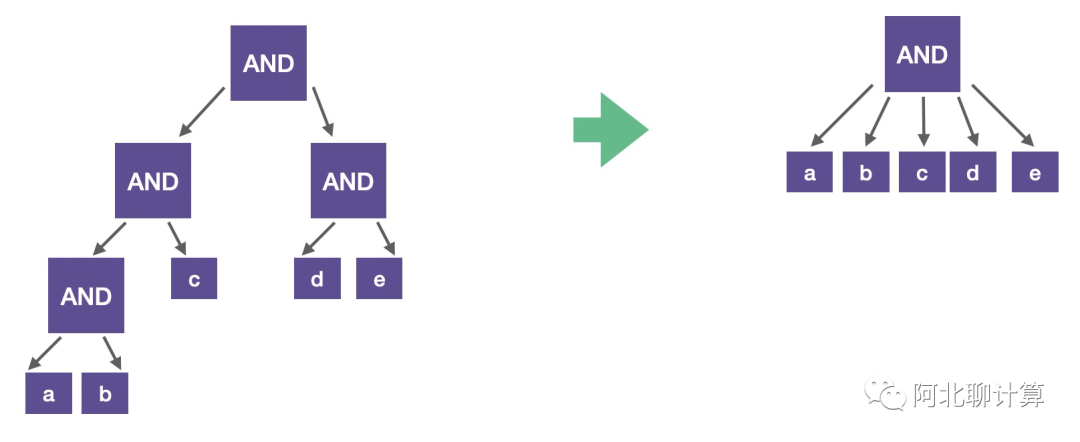
这样可以简化表达式,减少函数掉用量,提高性能。
第三步我们会检查当前的表达式是否遵从null语意。所谓的null语意就是说如果输入是null,那么不管你内部逻辑是什么,输出也是null。那么如果遵从null语意的话,这些输入也是不需要计算的,直接返回null就好了,因此我们可以把这些输入也去掉,提高性能。
第四步我们看下是否有常量折叠的机会:

常量折叠是说不管输入是什么,对应的表达式的值都是确定的,那么我们可以直接在编译阶段折叠成常量,而不用为每个tuple再无谓的计算从而提高性能。
所有这些优化都应用之后,如果输入数据还有,那么我们开始真正的执行。在执行过程中Velox还会有一些优化的机会,比如Adaptive Conjunct Ordering:
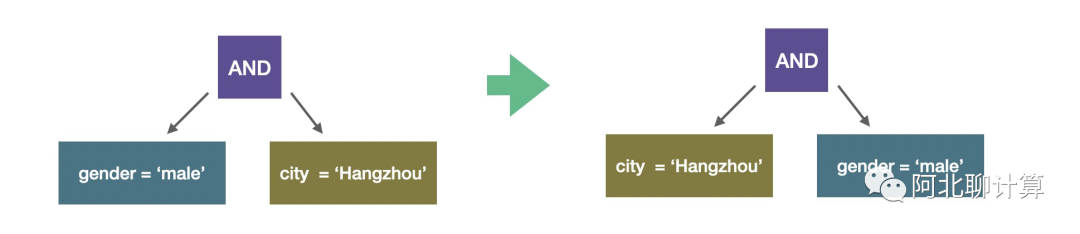
在上面的例子里面,AND有两个条件,一个针对gender,一个针对city,那么Velox在执行的过程中会发现city的过滤度会更高,它会把city这个过滤条件提到前面来先执行,从而提高性能。
Zero Copy
Zero Copy故名思义就是通过在执行的过程中不分配额外的内存完成部分查询逻辑的执行。这里以String函数的Zero Copy以及DictionaryVector的Zero Copy为例子来介绍一下。
先说操作string的substr这个函数的例子, 这个函数的作用截取输入字符串的一个子串作为返回值, 在Velox里面,它的实现是这样的:
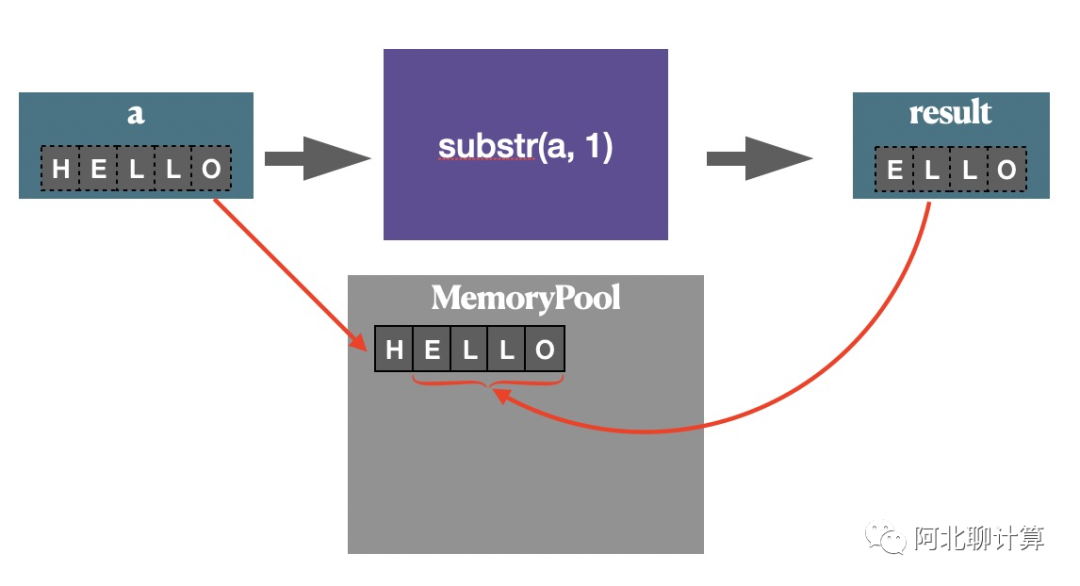
在上面的图里面,我们假设输入vector里面其中一个字符串是HELLO,那么函数substr(a, 1)的语意,它的返回值是ELLO,在Velox没有分配一块新的内存来表示ELLO,而是直接使用输入字符串的内存,只是把开始的位置稍做控制即可。当然这里Velox最作为这块内存的引用管理,保证这块内存不会被提前释放。但是这里重要的点是,为了返回函数结果这里是没有额外内存分配的,复用了输入字符串的内存。
再来一个element_at函数的例子:
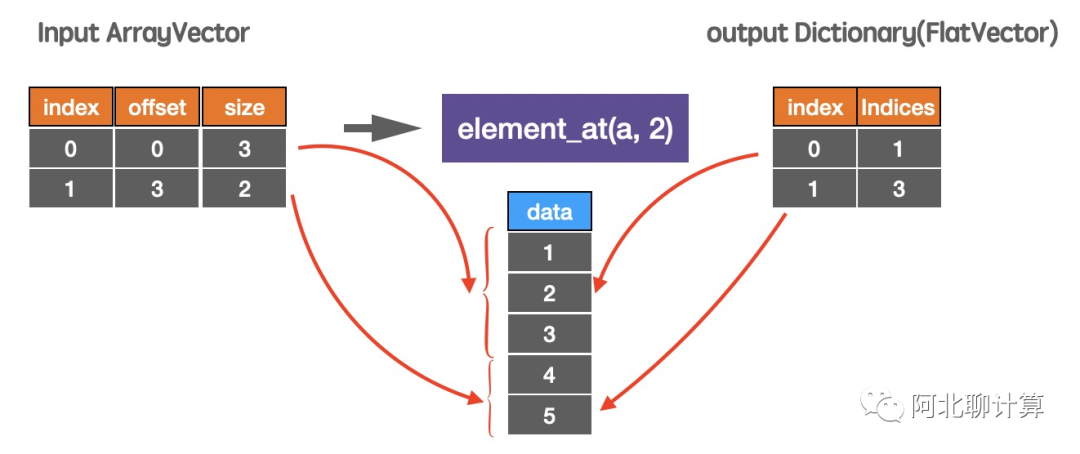
这里输入是一个ArrayVector,我们要找出每个Vector的第二个元素,也就是上面图里面的2和4,这里Velox的做法也不是生成一个新的包含2和4的Vector,它是在这个底层vector之上包一个DictionaryVector,然后通过维护index信息,告诉外层使用者这个vector里面有两个元素2和4。跟上面例子一样,重要的点在于这个过程中没有新的内存分配,Zero Copy!
Velox的应用
虽然Velox还是一个WIP的项目,但是基于Velox的应用已经在开发当中了,分别是Meta搞的基于Velox来加速Presto的Prestissimo项目以及基于Velox来加速Spark的OAP项目。
Prestissimo: Presto on Velox
Prestissimo 是Meta开发的,目的在于加速Presto查询,它的架构是这样的:
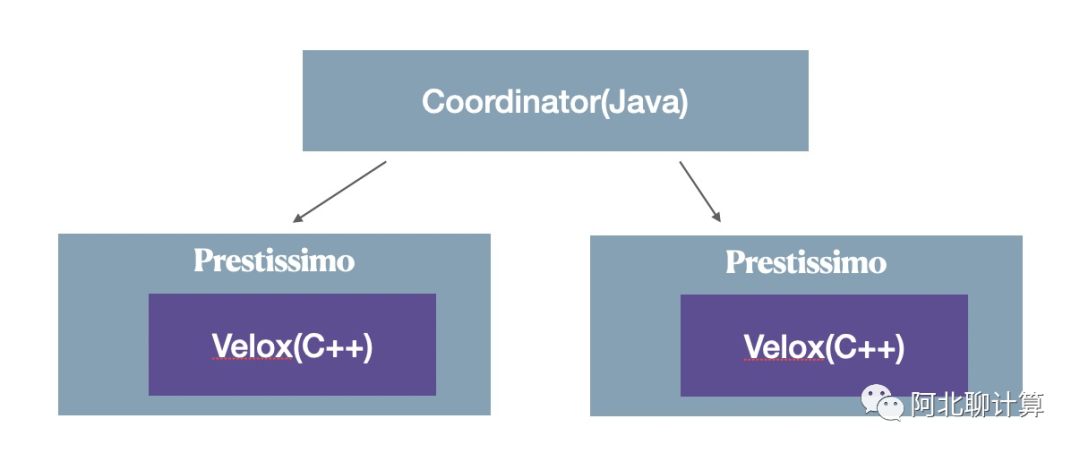
它是在一个Presto集群里面,把Worker换成Prestissimo,但是Coordinator还是原来的Java实现 -- 因为Coordinator上面主要是控制逻辑,也是Velox不涉及的点。而Prestissimo如果替代原来的Java版本的Worker呢?其实说白了也挺简单的,在一个集群里面Coordinator其实也不管你Worker到底是用什么语言实现的,只要你实现了Coordinator与Worker之间的交互协议就好了,而这个交互协议就是那些HTTP接口:
而Prestissimo只要实现这些接口,然后把具体的逻辑交给Velox来执行就好了。Prestissimo目前还没开源,在最近的一次公开talk说运行相同的查询只需要原生版本1/3的机器了。
Spark on Velox
Spark on Velox是Intel的一个团队在做,Spark的Open Analytics Package项目目标是用C++实现一个新的SQL语言,充分利用SIMD等等新特性,做的过程中发现Java代码和JNI代码耦合很紧,因此发起了一个项目想把这种强耦合关系打破,方便将来可以比较容易的切换底层C++部分的引擎,而这里作为实现就在对接Velox。
总结
Velox是一个现代化的向量化执行引擎,通过实现高性能的向量化数据结构,向量化的执行模型,单个批次内利用Zero Copy、新硬件特性比如SIMD来实现性能提升。
目前Velox还处在比较早期的状态,没有达到Production Ready,TPCH还没有跑通,不过从Github上面的交互来看,Meta还是投入了不少资源在做这件事情,从Prestissimo的测试来看能够以之前1/3的资源来执行相同的查询也是一个很大的性能提升,值得好好关注学习一下。
我创建了一个Velox相关的交流群,如果你确定你感兴趣,准备投入精力研究一下,欢迎加入: