
为什么人工智能需要可解释性?
👆点击“博文视点Broadview”,获取更多书讯

人工智能技术与系统已经开始频繁地出现在人们的工作和生活中,智能财务系统、智能招聘系统和智能推荐系统等不一而足——这些智能系统正在逐步改变社会生活的方方面面,影响甚至决定人的命运。
似乎在我们还没弄明白人工智能到底是怎么一回事的时候,人工智能的实际应用就已经跑得很远了。
然而,我们真的了解人工智能吗?到底什么是人工智能?人工智能的决策机制到底是怎样工作的?它今后将朝着怎样的方向发展?
这些问题都与人工智能系统的可解释性(Explainability)息息相关。
为什么人工智能需要可解释性?
为了回答这个问题,让我们首先考察一个图像识别模型的实验结果:
若干哈士奇和狼的样本图片,如图1(a)、图1 (b)所示,被用于训练一个深度神经网络结合逻辑回归的识别模型;该模型能够将绝大部分的正确图片分类,但却将雪地背景中的哈士奇误判为狼,如图1(c)所示;对该模型的可解释性研究揭示,如图1(d)所示,该识别器从训练数据中学到“可以将图片中的大面积白色背景(雪地)作为识别狼的依据”!
识别模型之所以学到了这个判决依据,是因为训练样本中所有的狼都是在雪地背景上的,而哈士奇不是。

图1
在实验中,人类评判员了解到这样的判决依据后,对该模型的信任度下降到 11%,即使模型的判别准确率达到 90% 以上[1]。
从这个简单的实验可以看出,了解人工智能模型的正确决策机制,是提升人类对人工智能模型信任度的重要方法。
而现有人工智能可解释性的研究成果揭示,基于数据驱动的人工智能系统决策机制,离取得人类信任这一终极目标,至少还存在机器学习决策机制的理论缺陷、机器学习的应用缺陷、人工智能系统未能满足合规要求三方面的差距。
图1的实验结果揭示出,如果仅仅是在输入数据(如“狼”的样本)和 预期结果(“狼”的识别结果)之间建立(概率)关联(Association),由于数据样本普遍存在局限和偏见(bias),这种关联学习不可避免地会学到一种虚假关系(Spurious Relationship),比如狼与雪地背景的相关性。
而以此作为决策依据的模型可能在大部分测试数据上表现良好,但其实并没有学到基于正确因果关系的推理决策能力,在面对与训练样本不一致的情况时,其表现就会大失水准。
按照2011年图灵奖得主、加利福尼亚大学洛杉矶分校计算机系Judea Pearl 教授的观点[2–4],这种基于关联分析(Association)的学习方式是一种低层次的认知,而为了从可能存在虚假关系的概率关联中进一步甄别出真正的因果关系,需要通过主动干预(Intervention)实验来拓展观测现象,并运用反事实推理(Counterfactual Reasoning)去伪存真,发现其内在因果关系。
如图2所 示,Judea Pearl教授将这样的因果推理学习概括为从低到高的三个认知层次。
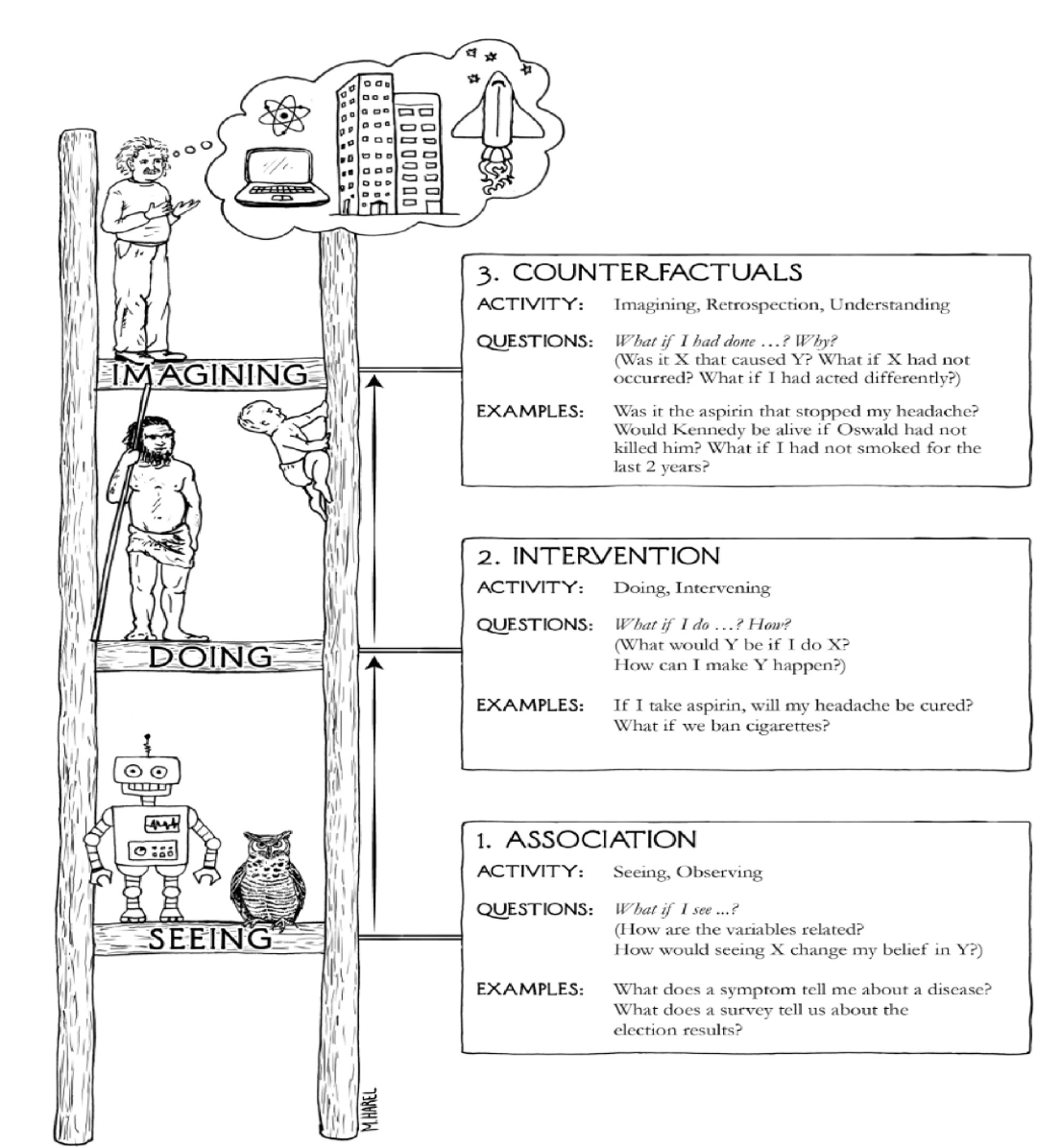
图2
按照这个理论架构,当前以深度学习为代表的数据驱动式机器学习尚停留在第一个层次,亟待引入主动干预和反事实推理等方法来厘清并强化智能决策的内在因果关系,进一步提升模型可信度。
在实际应用层面,通过刷海量数据的填鸭式学习得到的人工智能系统存在一系列隐患,并可能引发严重的社会问题:
首先,由于数据样本收集的局限和偏见,导致数据驱动的人工智能系统也是有偏见的,这种偏见甚至无异于人类社会中的偏见。比如,芝加哥法院使用的犯罪风险评估算法 COMPAS 被证明对黑人犯罪嫌疑人造成 了系统性歧视,白人更多被错误地评估为具有低犯罪风险,而黑人被错误地评估为具有高犯罪风险,且黑人的概率比白人高出一倍[5]。将个人的前途命运托付给这样有偏见的人工智能系统,既损害了社会公平,又会引起社会群体的矛盾对立。
其次,雪上加霜,“黑盒”似的深度神经网络还常常犯一些十分低级的、人类不可能犯的错误,表现出安全性上的潜在风险。如图3 所示,一个深度神经网络原本能够正确识别图片中有一辆校车,但在对少量图片像素做一些人眼不能察觉的改动之后,图片就被识别为鸵鸟[6]。更有甚者,人们只要戴上一副特制的眼镜,在现实环境中就能够骗过使用深度神经网络的人脸识别系统[7];考虑到人脸识别系统在金融支付等场景中的广泛应用,这种潜在的金融和社会风险令人不寒而栗。
最后,最重要的是从决策机制来看,当前对深度学习算法的分析还处于不透明的摸索阶段。尤其是拥有亿万个参数的超大规模预训练神经网络, 如BERT[8]、GPT3[9] 等,其决策过程在学术上仍然没有清晰的说明。这种“黑盒”似的深度神经网络暂时无法获得人类的充分理解与信任,大规模应用此类预训练模型的潜在风险不容忽视。

图3
从这些风险可以看出,现在的人工智能系统总体上仍然不能获得人们足够的信任,不能放心地被大规模部署应用。尤其是在金融、医疗、法律等AI 决策能够产生重大影响、风险极高的领域,人们期待一种能够合理解释其决策机制及过程的人工智能系统,也就是可信赖的人工智能,能够获得普罗大众的信任和认可,并得以和谐地融入人类社会的方方面面。
事实上,在金融、医疗和法律等重大领域,已经对人工智能系统应用风险的防范和监管立法,已经在逐步加强和实施落实。
比如,欧盟高级人工智能专家组起草的《可信人工智能道德原则指导》指出[10],可信人工智能系统必须满足七个方面的要求:
人类监管纠错
技术安全及鲁棒
隐私保护和数据治理
透明及可解释
算法公平及无歧视
环保及社会影响
问责制度
中国新一代人工智能治理专业委员会在2019年6月发布的《新一代人工智能治理原 则——发展负责任的人工智能》政策文件中指出,要突出发展负责任的人工智能,强调公平公正、尊重隐私、安全可控等八条原则,因此,提高可解释性成为推广智能模型在各行各业应用的必由之路[11]。
在金融领域,荷兰中央银行在2019年7月发布的《金融行业人工智能应用一般原则》中,提出了稳健、问责、公平、道德伦理、专业和透明六个方面的技术应用原则。
中国人民银行在《金融科技(FinTech)发展规划(2019– 2021)》中也明确提出“健全人工智能金融应用安全监测预警机制,研究制定人工智能金融应用监管规则,强化智能化金融工具安全认证,确保把人工智能金融应用规制在安全可控范围内”[12]。
更进一步,中国人民银行在 2021年3月发布的《人工智能算法金融应用评价规范》中明确提出,人工智能建模的可解释性主要集中于算法建模准备、建模过程、建模应用提出基本要求、评 价方法与判定准则等过程[13]。新加坡及中国香港的金融监管部门,均要求使用金融科技的机构对其技术标准和使用方式进行审慎的内部管理,并对其用 户履行充分的告知和解释义务,确保金融产品消费者的知情权(更多金融行业可解释人工智能内容,参见《可解释人工智能导论》一书第 7 章)。
在医疗领域,美国FDA在2021年1月发布《基于人工智能/机器学习的 医疗器械软件行动计划》,提出了良好机器学习质量管理规范(Good Machine Learning Practice,GMLP),提倡以患者为中心提高产品透明度,加强对算法偏差和鲁棒性的监管,推动真实世界性能监测。
中国国家药品监督管理局依托人工智能医疗器械标准化技术归口单位推动人工智能医疗器械标准规范的建立,其出台的《人工智能医疗器械质量要求和评价——第 2 部分:数据集 通用要求》已经在 2020 年进入报批阶段。该要求考虑了在人工智能可解释性 方面的要求。
虽然对人工智能可解释性的监管要求已经在法律和规章制度层面逐步完善,但如何将这些制度层面的规则具体细化落实为可实现的技术方案,仍是可解释人工智能亟待研究和解决的挑战。
参考文献:
[1] RIBEIRO M T, SINGH S, GUESTRIN C. "why should i trust you?" explaining the predictions of any classififier[C]//Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. 2016: 1135-1144.
[2] PEARL J, MACKENZIE D. The book of why: The new science of cause and effffect[M]. 1st ed. USA: Basic Books, Inc., 2018.
[3] PEARL J. Models, reasoning and inference[J]. Cambridge, UK: Cambridge University Press, 2000, 19.
[4] PEARL J. Bayesianism and causality, or, why i am only a half-bayesian[M]//Foundations of bayesianism. Springer, 2001: 19-36.
[5] Angwin, Julia; Larson, Jeffff. “machine bias”[EB/OL]. 2016. https://www.propublica.org/a rticle/machine-bias-risk-assessments-in-criminal-sentencing.
[6] SZEGEDY C, ZAREMBA W, SUTSKEVER I, et al. Intriguing properties of neural networks[C/OL]//International Conference on Learning Representations. 2014. http: //arxiv.org/abs/1312.6199.
[7] CHEN X, LIU C, LI B, et al. Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning[J]. arXiv e-prints, 2017: arXiv:1712.05526.
[8] DEVLIN J, CHANG M W, LEE K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. arXiv e-prints, 2018: arXiv:1810.04805.
[9] BROWN T, MANN B, RYDER N, et al. Language models are few-shot learners[C/OL]// LAROCHELLE H, RANZATO M, HADSELL R, et al. Advances in Neural Information Processing Systems: volume 33. Curran Associates, Inc., 2020: 1877-1901. https://procee dings.neurips.cc/paper/2020/fifile/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf.
[10] European Commission High-Level Expert Group on Artifificial Intelligence. Ethics guidelines for trustworthy ai[Z]. 2019.。
[11] 人工智能治理专业委员会. 新一代人工智能治理原则——发展负责任的人工智能 [Z]. 2019.
[12] 中国人民银行. 金融科技(FinTech)发展规划(2019-2021 年)[Z]. 2019.
[13] 中国人民银行. 人工智能算法金融应用评价规范 [Z]. 2021.

本文摘自《可解释人工智能导论》一书,欢迎阅读本书了解更多相关内容!
粉丝专享购书码,下单即减63元!


如果喜欢本文 欢迎 在看丨留言丨分享至朋友圈 三连 热文推荐
▼点击阅读原文,了解本书详情~