
YOLOv5训练自己的数据集(超详细)
YOLOv5训练自己的数据集整个过程主要包括:环境安装----制作数据集----模型训练----模型测试----模型推理
一、准备深度学习环境
本人的笔记本电脑系统是:Windows10
首先进入YOLOv5开源网址 ,手动下载zip或是git clone 远程仓库,本人下载的是YOLOv5的5.0版本代码,代码文件夹中会有requirements.txt文件,里面描述了所需要的安装包。
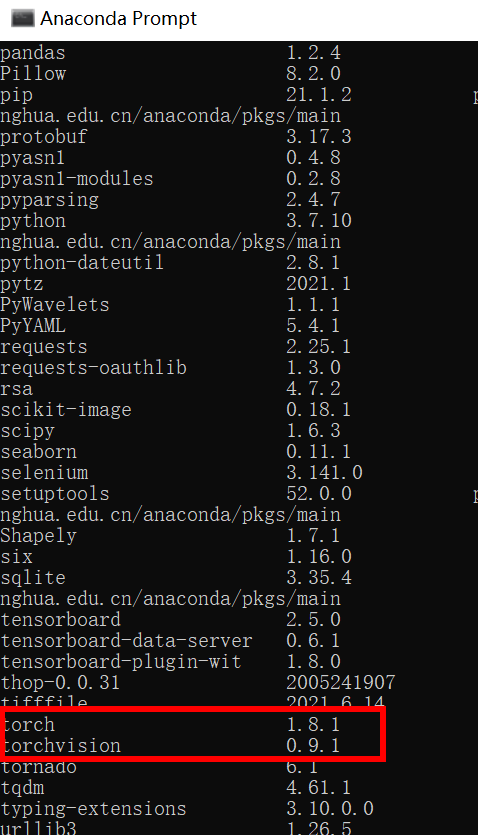
本文最终安装的pytorch版本是1.8.1,torchvision版本是0.9.1,python是3.7.10,其他的依赖库按照requirements.txt文件安装即可。
二、 准备自己的数据集
本人在训练YOLOv5时,选择的数据格式是VOC,因此下面将介绍如何将自己的数据集转换成可以直接让YOLOv5进行使用。
1、创建数据集
在YOLOv5文件夹中的data目录下创建mydata文件夹(名字可以自定义),目录结构如下,将之前labelImg标注好的xml文件和图片放到对应目录下
mydata
…images # 存放图片
…xml # 存放图片对应的xml文件
…dataSet #之后会在Main文件夹内自动生成train.txt,val.txt,test.txt和trainval.txt四个文件,存放训练集、验证集、测试集图片的名字(无后缀.jpg)
示例如下:
mydata文件夹下内容如下:

image为VOC数据集格式中的JPEGImages,内容如下:
xml文件夹下面为.xml文件(标注工具采用labelImage),内容如下:
dataSet 文件夹下面存放训练集、验证集、测试集的划分,通过脚本生成,可以创建一个split_train_val.py文件,代码内容如下:
import osimport randomimport argparseparser = argparse.ArgumentParser()parser.add_argument('--xml_path', default='xml', type=str, help='input xml label path')# 数据集的划分,地址选择自己数据下的ImageSets/Mainparser.add_argument('--txt_path', default='dataSet', type=str, help='output txt label path')opt = parser.parse_args()trainval_percent = 1.0train_percent = 0.9xmlfilepath = opt.xml_pathtxtsavepath = opt.txt_pathtotal_xml = os.listdir(xmlfilepath)if not os.path.exists(txtsavepath):os.makedirs(txtsavepath)num = len(total_xml)list_index = range(num)tv = int(num * trainval_percent)tr = int(tv * train_percent)trainval = random.sample(list_index, tv)train = random.sample(trainval, tr)file_trainval = open(txtsavepath + '/trainval.txt', 'w')file_test = open(txtsavepath + '/test.txt', 'w')file_train = open(txtsavepath + '/train.txt', 'w')file_val = open(txtsavepath + '/val.txt', 'w')for i in list_index:name = total_xml[i][:-4] + '\n'if i in trainval:file_trainval.write(name)if i in train:file_train.write(name)else:file_val.write(name)else:file_test.write(name)file_trainval.close()file_train.close()file_val.close()file_test.close()
运行代码后,在dataSet 文件夹下生成下面四个txt文档:

三个txt文件里面的内容如下:

2、转换数据格式
接下来准备labels,把数据集格式转换成yolo_txt格式,即将每个xml标注提取bbox信息为txt格式,每个图像对应一个txt文件,文件每一行为一个目标的信息,包括class, x_center, y_center, width, height格式。
格式如下:
创建voc_label.py文件,将训练集、验证集、测试集生成label标签(训练中要用到),同时将数据集路径导入txt文件中,代码内容如下:
# -*- coding: utf-8 -*-import xml.etree.ElementTree as ETimport osfrom os import getcwdsets = ['train', 'val', 'test']classes = ["a", "b"] # 改成自己的类别abs_path = os.getcwd()print(abs_path)def convert(size, box):dw = 1. / (size[0])dh = 1. / (size[1])x = (box[0] + box[1]) / 2.0 - 1y = (box[2] + box[3]) / 2.0 - 1w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn x, y, w, hdef convert_annotation(image_id):in_file = open('data/mydata/xml/%s.xml' % (image_id), encoding='UTF-8')out_file = open('data/mydata/labels/%s.txt' % (image_id), 'w')tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = obj.find('Difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))b1, b2, b3, b4 = b# 标注越界修正if b2 > w:b2 = wif b4 > h:b4 = hb = (b1, b2, b3, b4)bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')wd = getcwd()for image_set in sets:if not os.path.exists('data/mydata/labels/'):os.makedirs('data/mydata/labels/')image_ids = open('data/mydata/dataSet/%s.txt' % (image_set)).read().strip().split()list_file = open('paper_data/%s.txt' % (image_set), 'w')for image_id in image_ids:list_file.write(abs_path + '/mydata/images/%s.jpg\n' % (image_id))convert_annotation(image_id)list_file.close()
3、配置文件
1)数据集的配置
在yolov5目录下的data文件夹下新建一个mydata.yaml文件(可以自定义命名),用来存放训练集和验证集的划分文件(train.txt和val.txt),这两个文件是通过运行voc_label.py代码生成的,然后是目标的类别数目和具体类别列表,mydata.yaml内容如下:
2) 选择一个你需要的模型
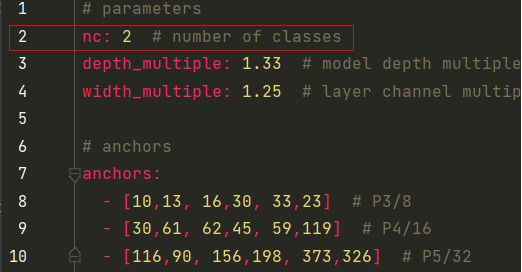
在yolov5目录下的model文件夹下是模型的配置文件,这边提供s、m、l、x版本,逐渐增大(随着架构的增大,训练时间也是逐渐增大),假设采用yolov5x.yaml,只用修改一个参数,把nc改成自己的类别数,需要取整(可选) 如下:
至此,自定义数据集已创建完毕,接下来就是训练模型了。
三、模型训练
1、下载预训练模型
在YOLOv5的GitHub开源网址上下载对应版本的模型
2、训练
在正式开始训练之前,需要对train.py进行以下修改:
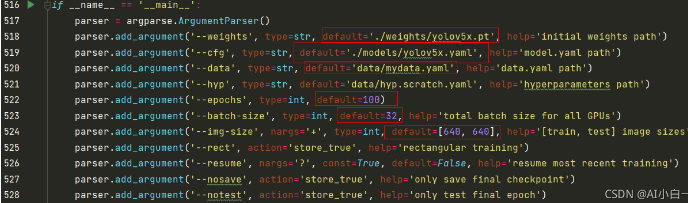
以上参数解释如下:
epochs:指的就是训练过程中整个数据集将被迭代多少次,显卡不行你就调小点。
batch-size:一次看完多少张图片才进行权重更新,梯度下降的mini-batch,显卡不行你就调小点。
cfg:存储模型结构的配置文件
data:存储训练、测试数据的文件
img-size:输入图片宽高,显卡不行你就调小点。
之后运行训练命令如下:
python train.py --img 640 --batch 32 --epoch 300 --data data/mydata.yaml --cfg models/yolov5x.yaml --weights weights/yolov5x.pt --device '0,1' 四、模型测试
评估模型好坏就是在有标注的测试集或者验证集上进行模型效果的评估,在目标检测中最常使用的评估指标为mAP。
在test.py文件中指定数据集配置文件和训练结果模型,如下:
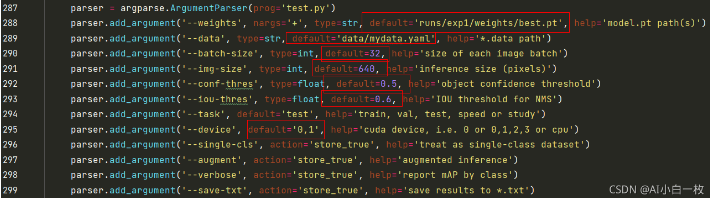
通过下面的命令进行模型测试:
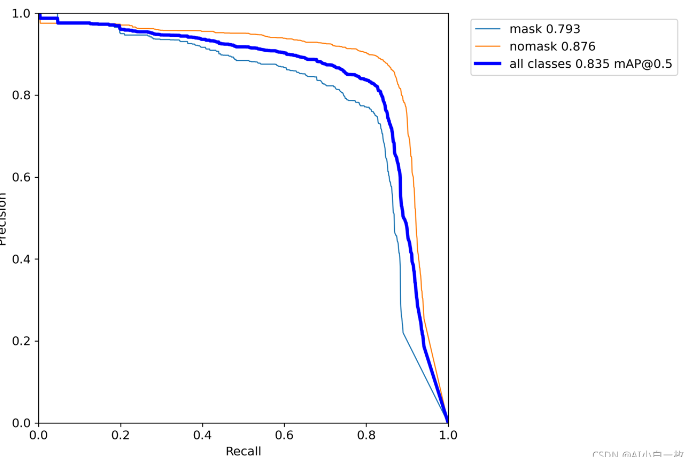
python test.py --data data/mydata.yaml --weights runs/exp1/weights/best.pt --augment模型测试效果如下:
五、模型推理
最后,模型在没有标注的数据集上进行推理,在detect.py文件中指定测试图片和测试模型的路径,其他参数(img_size、置信度object confidence threshold、IOU threshold for NMS)可自行修改,如下:
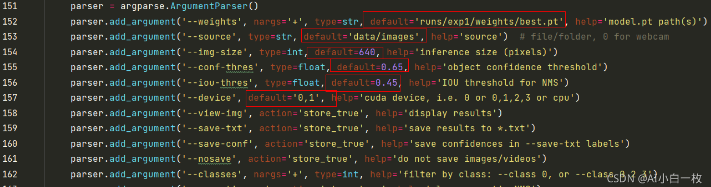
使用下面的命令,其中,weights使用最满意的训练模型即可,source则提供一个包含所有测试图片的文件夹路径即可。
python detect.py --weights runs/exp1/weights/best.pt --source inference/images/ --device 0,1测试完毕后,每个测试图片会在指定的inference/output输出文件夹中生成结果图片文件,如下:
本人训练的数据集是口罩数据集,检测后的效果如下图所示:


版权声明:本文为CSDN博主「AI追随者」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:
https://blog.csdn.net/qq_40716944/article/details/118188085
声明:部分内容来源于网络,仅供读者学习、交流之目的文章版权归原作者所有。如有不妥,请联系删除。