
基于RNN的序列化推荐系统总结
作者 | 阳光明媚
1. Session-based Recommendations with Recurrent Neural Networks
Session-based Recommendations with Recurrent Neural Networks
本文首次将RNN引入了用户序列行为的建模,并取得了显著的效果提升。
解决的关键问题:
为了使得推荐系统能够学习用户的序列决策数据,引入一个排序损失函数,并用RNN模型来建模稀疏的序列决策数据。
挑战:
在序列化推荐的每一步,待选的物品数目巨大,在万到十万级别 点击流数据量大 关心模型对用户可能感兴趣的top物品的预测能力
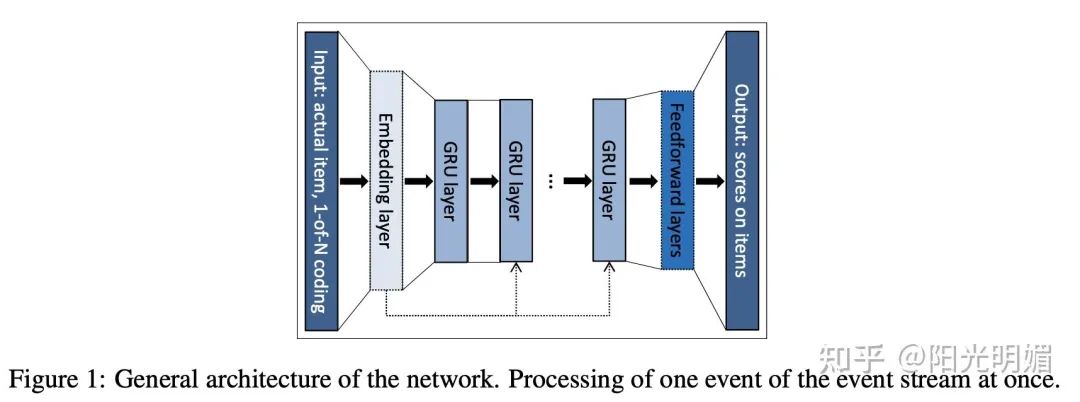
模型结构与算法细节:
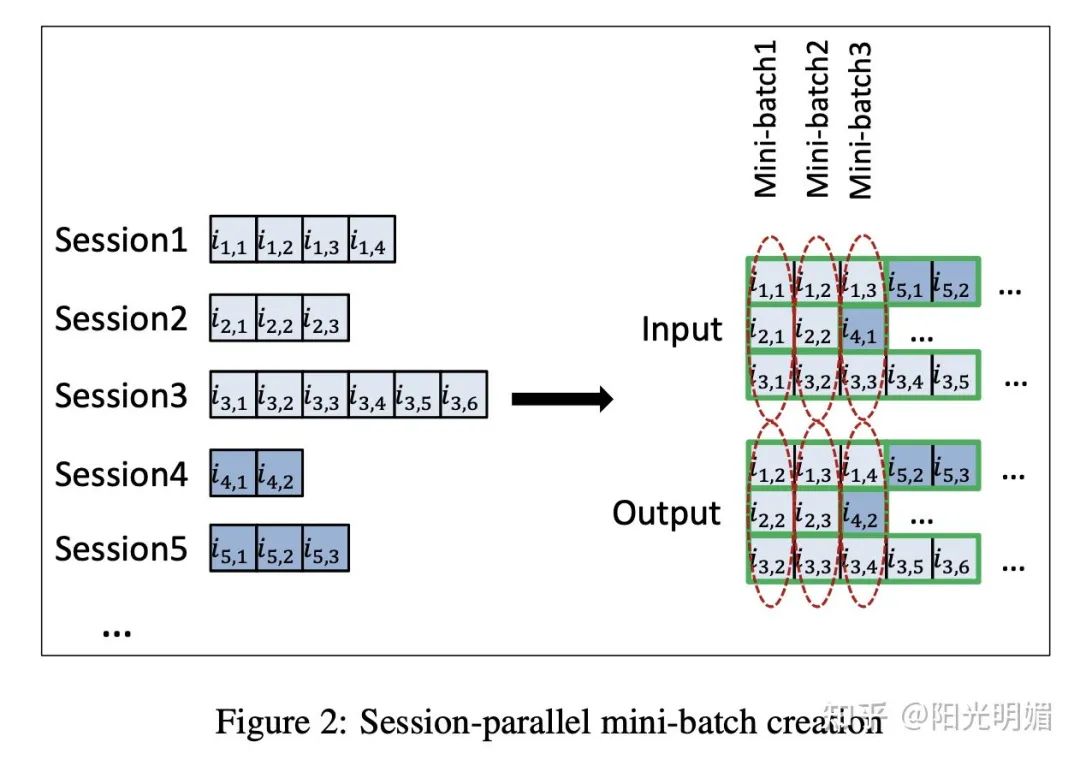
Session-parallel mini-batches
Sampling on the output
Ranking loss
Pointwise排序估计彼此独立的项目的得分或排名,损失的定义方式应使相关项目的排名较。 Pairwise排序比较一个正项目和一个负项目的得分或成对的排名,损失强制要求正项目的排名应低于负项目的排名。 Listwise排序使用所有项目的分数和等级,并将它们与完美顺序进行比较。由于它包括排序,通常计算成本更高,因此不经常使用。此外,如果只有一个相关的项目-在我们的案例中-listwise排序可以通过pairwise排序解决。

论文的模型部分到这里就结束了,下面看一下执行细节与实验部分
代码地址:
https://github.com/yhs968/pyGRU4REC
用GRU对输入建模:
# reset the hidden states if some sessions have just terminated
hidden = reset_hidden(hidden, mask).detach()
# Go through the GRU layer
logit, hidden = self.gru(input, target, hidden)
# Output sampling
logit_sampled = logit[:, target.view(-1)]
# Calculate the mini-batch loss
loss = self.loss_fn(logit_sampled)Top1 Loss的计算:
def TOP1Loss(logit):
"""
Args:
logit (BxB): Variable that stores the logits for the items in the session-parallel mini-batch.
Negative samples for a specific item are drawn from the other items in the
session-parallel minibatch, as mentioned in the original GRU4REC paper.
The first dimension corresponds to the batches, and the second dimension
corresponds to sampled number of items to evaluate.
"""
# differences between the item scores
diff = -(logit.diag().view(-1, 1).expand_as(logit) - logit)
# final loss
loss = F.sigmoid(diff).mean() + F.sigmoid(logit ** 2).mean()
return loss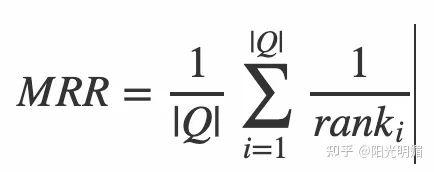
一个正确物品如果被排到了20名开外,记为0分。
baseline选择了基于流行度的推荐,和基于物品相似度的推荐:

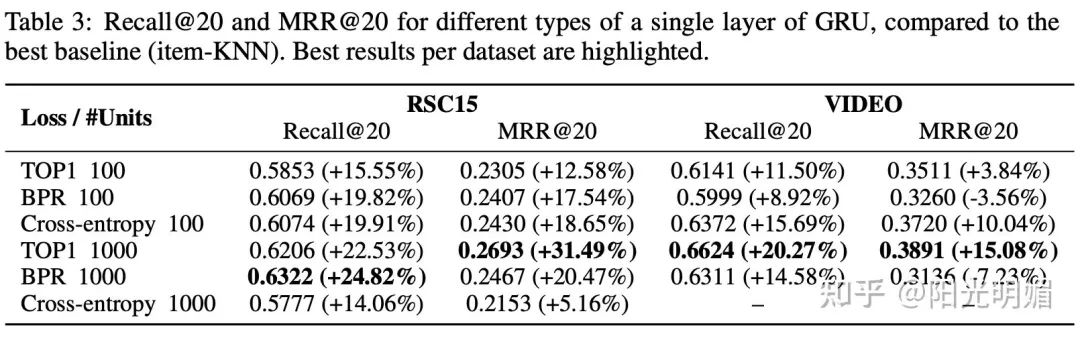
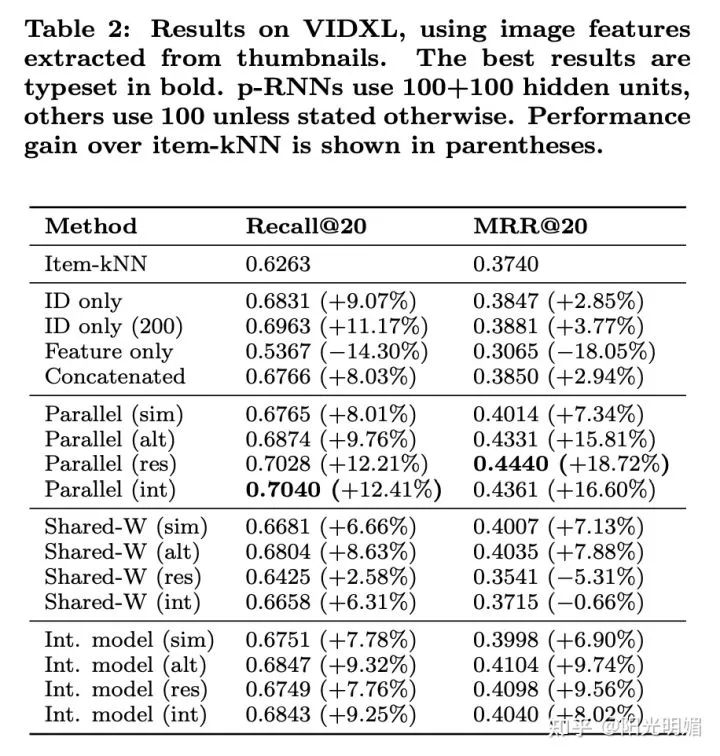
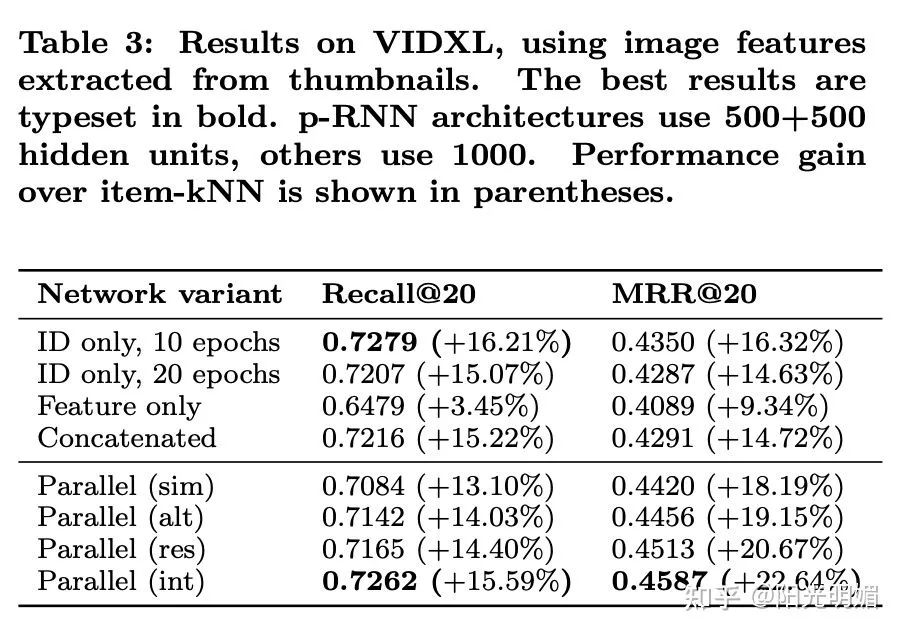
实验效果部分,可以看到提升非常显著:
Parallel recurrent neural network architectures for feature-rich session-based recommendations
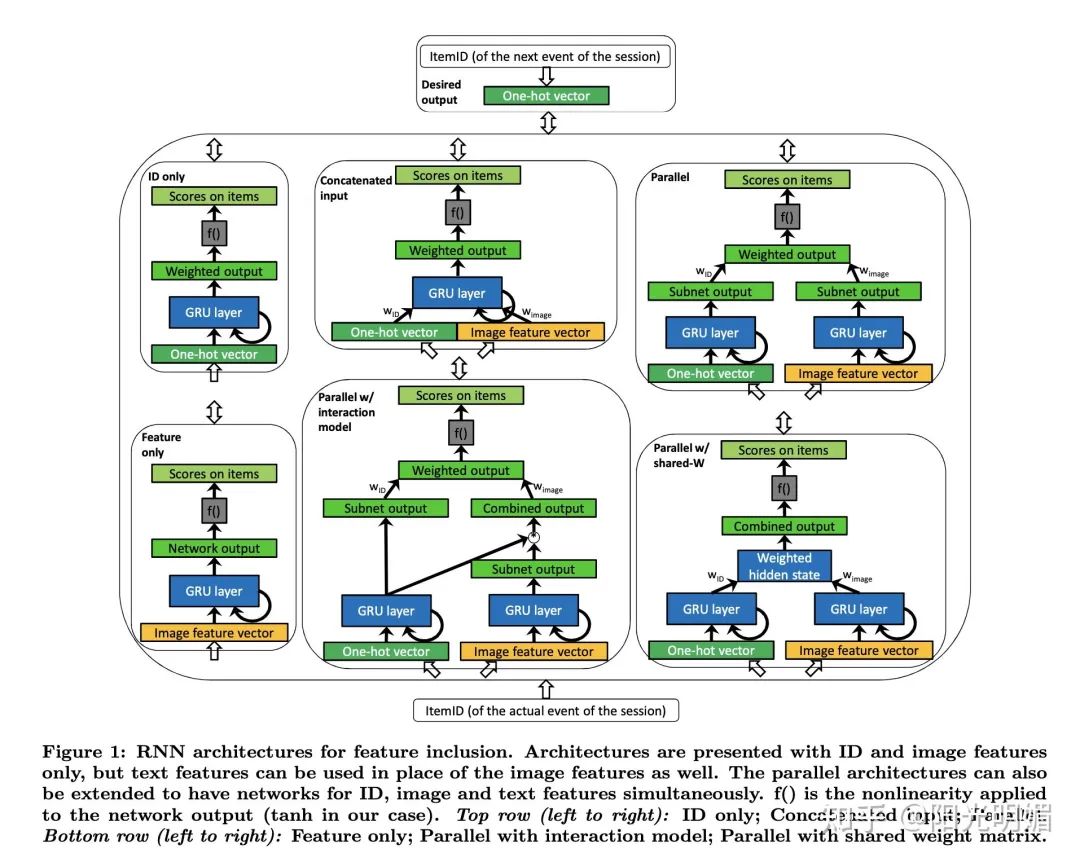
Simultaneous:所有参数同时进行训练,用作baseline。 Alternating:每个epoch只训练一个特征的网络,其他特征对应的网络参数固定,循环进行,例如:第一次训练ID网络,第二次图像网络,第三次ID网络....... Residual:每个网络分支依次训练,但是不会循环,每个网络分支的单次训练长度比Alternating要长,比如ID网络训练10个epoch,接着feature网络基于前面ID网络的参差训练10个epoch。每个网络分支基于之前训练过的网络分支的residual error的ensemble进行训练。 Interleaving:对于每个mini-batch,在网络分支间交替进行如下训练:第一个子网络正常训练,第二个子网络基于当前mini-batch在当前网络的残差训练。更为频繁的交替训练能使得网络之间的训练更为平衡,且这样做没有了同步训练的缺点。
评论