
HCP-Diffusion:中山大学开源的统一通用扩散模型代码
-
HCP-Diffusion 代码工具:https://github.com/7eu7d7/HCP-Diffusion -
HCP-Diffusion 图形界面:https://github.com/7eu7d7/HCP-Diffusion-webui
-
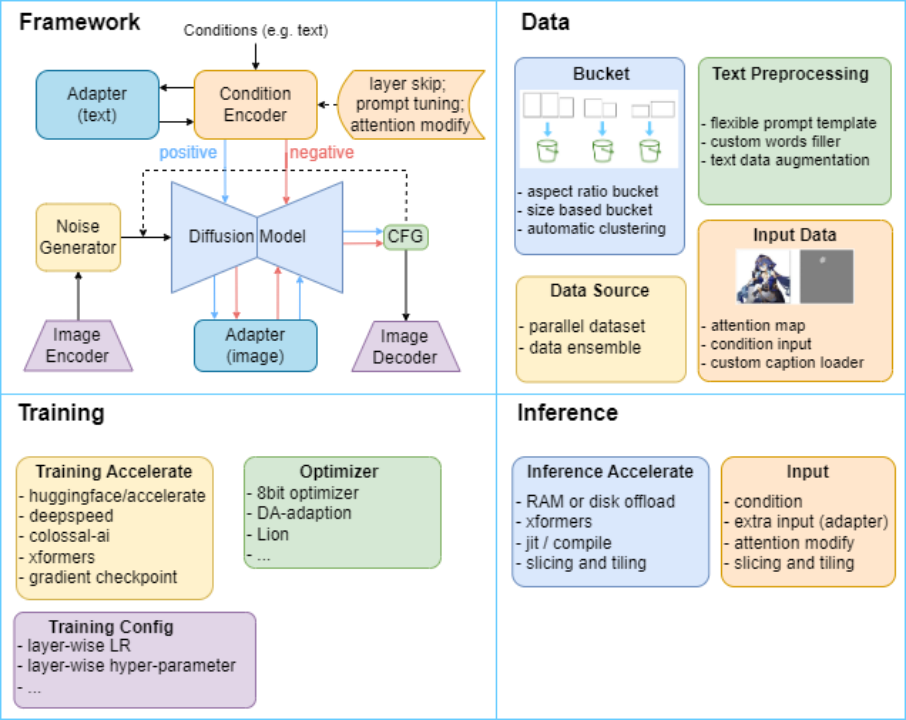
统一架构:搭建 Diffusion 系列模型统一代码框架 -
算子插件:支持数据、训练、推理、性能优化等算子算法,如 deepspeed, colossal-AI 和 offload 等加速优化 -
一键配置:Diffusion 系列模型可通过高灵活度地修改配置文件即可完成模型实现 -
一键训练:提供 Web UI,一键训练、推理
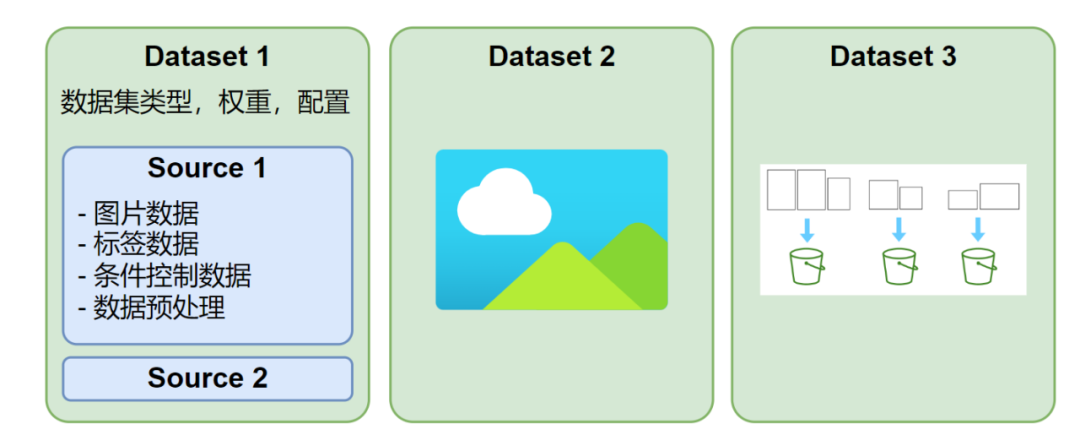
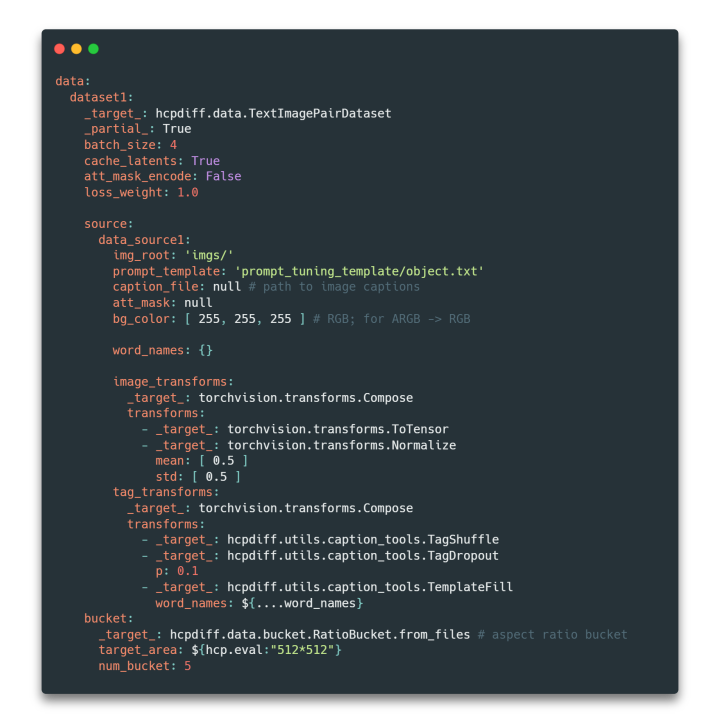




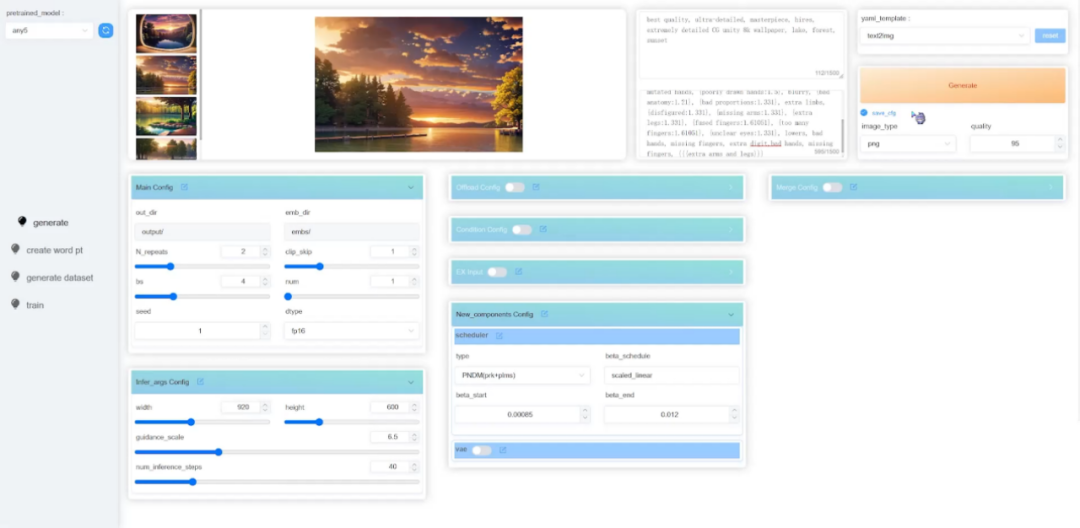
实验室简介
中山大学人机物智能融合实验室 (HCP Lab) 由林倞教授于 2010 年创办,近年来在多模态内容理解、因果及认知推理、具身学习等方面取得丰富学术成果,数次获得国内外科技奖项及最佳论文奖,并致力于打造产品级的AI技术及平台。实验室网站:http://www.sysu-hcp.net
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击一杯奶茶,成为AIGC+CV视觉的前沿弄潮儿!,加入 AI生成创作与计算机视觉 知识星球!
评论