
实时 OLAP, 从 0 到 1
共 4246字,需浏览 9分钟
·
2021-04-10 11:21
业务背景
机遇挑战
架构演进
架构优化
未来展望
一、业务背景
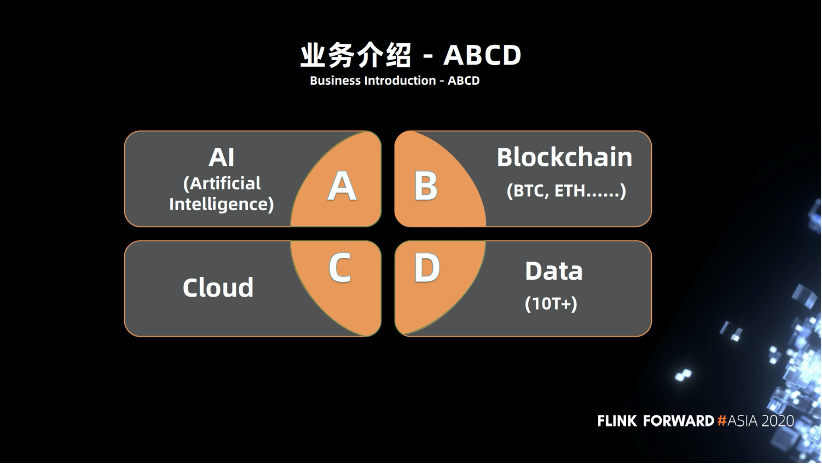

二、机遇挑战
不能做到实时处理数据
存在单点问题,比方某一条链路突然挂掉,此时整个环节都会出现问题

效率,效率问题是非常常见的。我们的表大概在几十亿量级,跑这种 SQL ,可能需要很长时间, SQL 查询比较慢,严重影响统计效率。
实时,数据不是实时的,需要等到一定的时间才会更新,如昨天的数据今天才能看到。
监控,实时需求,如实时风控,每当区块链出现一个区块,我们就要对它进行分析,但是区块出现的时间是随机的。缺乏完整的监控,有时候作业突然坏了,或者是没达到指标,我们不能及时知道。
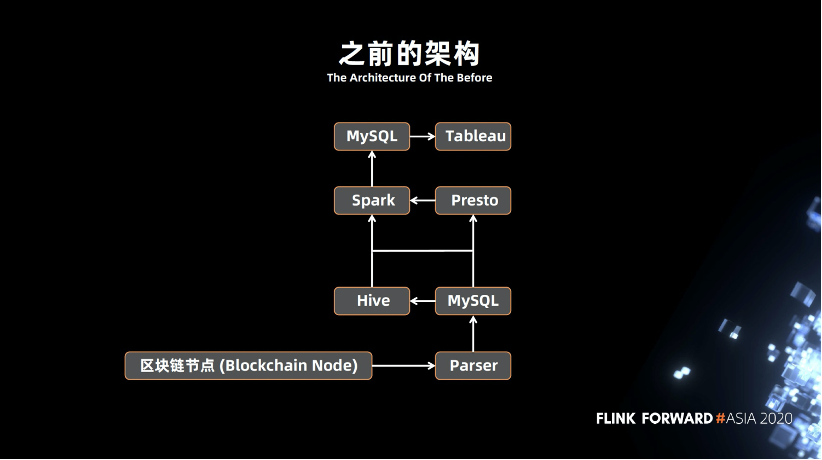
三、架构演进

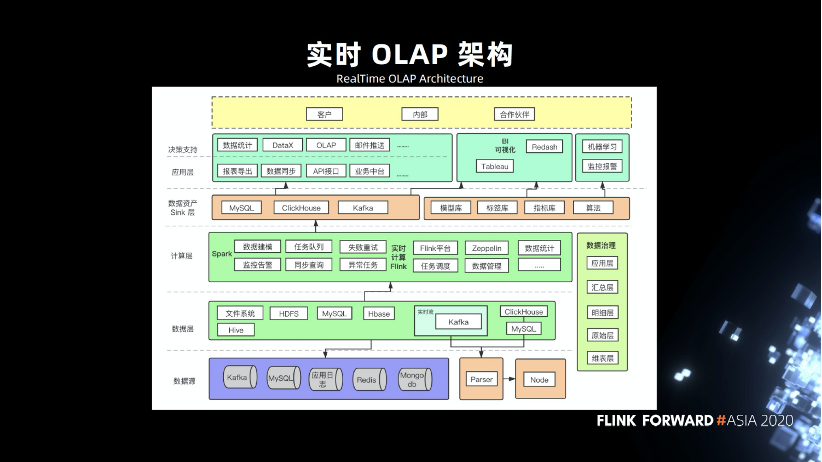


为什么演进这么慢,因为区块链的发展还没有达到一定量级,无法像某些大公司有上亿级别或者 PB 级别的数据量。我们的数据量没有那么大,区块链是一个新鲜的事物,没有一定的历史。另外的问题就是资源问题,由于人员不足,人员成本上也有所控制。
刚才讲的架构,我们总结了它适合怎样的企业。首先是有一定的数据规模,比说某个企业 MySQL 只有几千万的数据,用 MySQL , Redis , MongoDB 都可以,就不适合这套架构。其次是需要一定的成本控制,这一整套成本算下来比 Spark 那一套会低很多。要有技术储备,要开发了解相关的东西。
区块链数据的特点。数据量比较多,历史数据基本上是不变的,实时数据相对来说是更有价值的,数据和时间存在一定的关联。
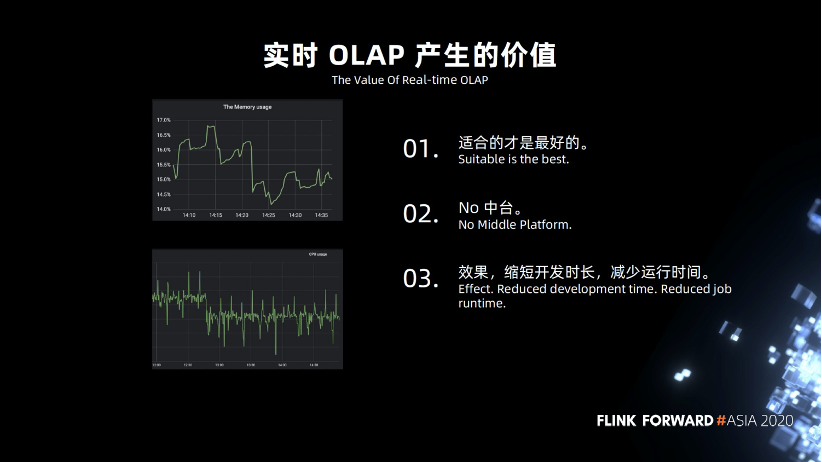
适合的是最好的,不要盲目追求新技术,比如数据湖,虽然好,但是我们的数据量级实际上用不到。 我们不考虑建设技术中台,我们的公司规模是中小型,部门沟通起来比较容易,没有太多的隔阂,没有发展到一定的组织规模,所以我们没有打算发展技术中台,数据中台,不盲目跟风上中台。 我们达到的效果是缩短了开发的时长,减少作业的运行时间。
四、架构优化

自定义 sink 。
ClickHouse 要一次性插入很多数据,需要控制好写入的频次,优先写入本地表,耗时比较多。
我们主要用在智能合约的交易分析,新增的数据比较多,比较频繁,每几秒就有很多数据。数据上关联比较多。

批量导入时失败和容错。
Upsert 的优化。
开发了常用 UDF ,大家知道 ClickHouse 官方是不支持 UDF 的吗?只能通过打补丁,保证 ClickHouse 不会挂。
我们也在做一些开源方面的跟进,做一些补丁方面的尝试,把我们业务上,技术上常用的 UDF ,集合在一起。
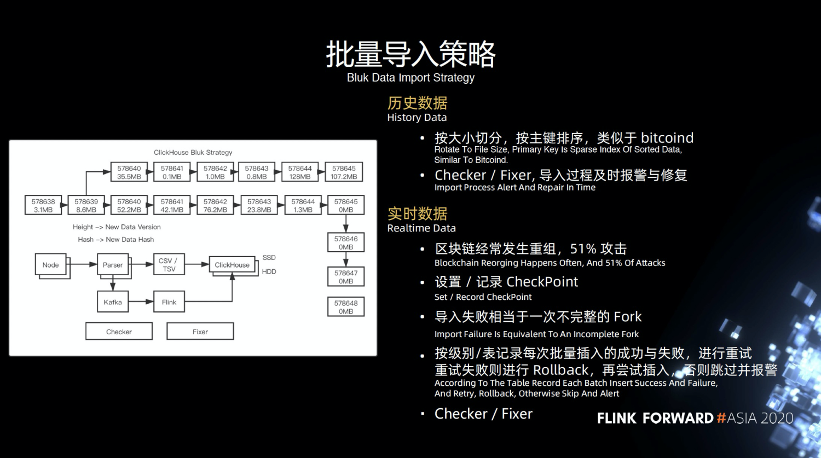
历史数据,可以认为是一种冷数据,相对来说不会经常改变。导入的时候按照大小切分,按照主键排序,类似于 bitcoind ,底层的 Checker 和 Fixer 工作,导入过程中及时进行报警和修复。比如导入某一数据失败了,如何更好的及时发现,之前就只能人肉监控。
实时数据,我们需要不断解析实时数据,大家可能对重组,51%的概念不太熟悉,这里简单讲一下,上图最长的链也是最重要的链,它上面的一条链是一个重组并且分叉的一条链,当有一个攻击者或者矿工去挖了上面的链,最终的结果会导致这条链被废弃掉,拿不到任何奖励。

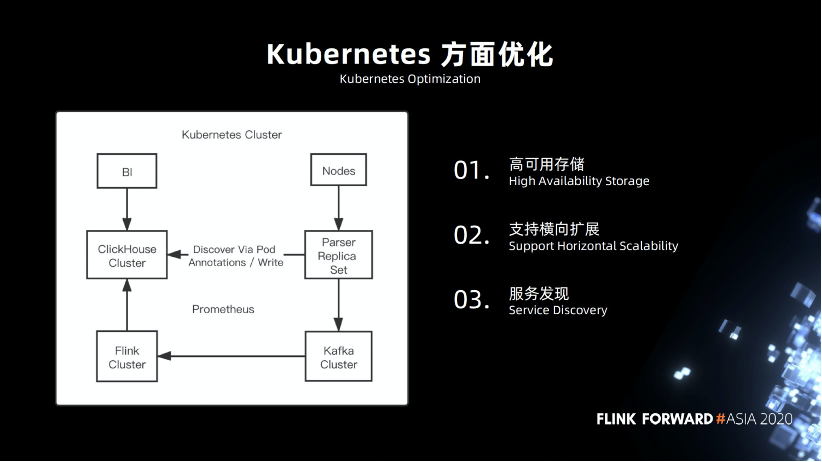
高可用的存储,在早期的时候,我们就尽可能的将服务部署在 Kubernetes,包括 Flink 集群,基础业务组件,币种节点,ClickHouse 节点,在这方面 ClickHouse 做的比较好,方便兼容,支持高可用操作。
支持横向扩展。
服务发现方面,我们做了一些定制。

采用 Final 进行查询,等待数据合并完成。
在数据方面的话,实现幂等性,保证唯一性,通过主键排序,整理出来一组数据,再写入。
写入异常时就及时修复和回填,保证最终一致性。
五、未来展望

扩展更多的业务和数据。之前我们的业务模式比较单一,只有数据方面的统计,之后会挖掘更多信息,包括链上追踪,金融方面的审计。
赚更多的钱,尽可能的活下去,我们才能去做更多的事情,去探索更多的盈利模式。
跟进 Flink 和 PyFlink 的生态,积极参与开源的工作,优化相关作业。探索多 sink 方面的工作,原生 Kubernetes 的实践。

数据建模的规范,规定手段,操作。
Flink 和机器学习相结合。
争取拿到实时在线训练的业务,Flink 做实时监控,是非常不错的选择。大公司都已经有相关的实践。包括报警等操作。
总的来说的话,路漫漫其修远兮,使用 Flink 真不错。更多 Flink 相关技术交流,可扫码加入社区钉钉大群~
 戳我,回顾作者分享视频!
戳我,回顾作者分享视频!