
Linear-chain CRF的推导
共 3527字,需浏览 8分钟
·
2021-09-01 15:54
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达

来自:ChallengeHub
作者:致Great
前言
在推导线性链CRF之前,我们先看一个词性标注(POS)的例子
在我们想要标注book这个词的时候,是将其标注成名词noun或者动词verb是需要取决于当前词的前一个词的。在这种情境下,前一个词‘a’的词性一个限定词(determiner),所以我们选择将book标注成noun(名词)。对于这样的序列标记任务,以及更一般的结构化预测任务,Linear-chain CRF对标签之间的上下文依赖关系建模是有帮助的。
什么是结构化预测?
相信很多人对文本分类问题都比较熟悉,它的目标定义很简单,将一个文本样本输入到一个模型中,然后让模型输出一个结果标签,这个标签可以是一个二分类的标签,也可以是一个多分类的标签。而除了这种范式的问题外,NLP领域还有一大问题范式:序列类任务。这种任务最大的特点就是输出的标签是一个序列。而根据具体的任务形式,可以将序列类任务分成两种子类:
序列标注任务,对于一段文本,以词或者字符等基本语素为基本单位,模型输出的标签序列与原始文本的语素序列是一一对应的。具体的任务例子有词性标注,实体识别等。 序列生成任务,即大家熟知的NLG任务。与序列标注任务不同,它不要求输出的标签序列与原始文本序列一一对应,长度也不需要相同。常见的序列生成任务有机器翻译,文本摘要,智能对话回答生成等。
当然也可以将序列标注任务视作特殊的序列生成任务来做,只不过要加上长度的限定条件。
这种序列类任务的共同特点是每个文本样本都会有指数级或者无限量级的标签序列候选组合。对于词性标注来说,假设一共有n种词性,那么对一个长度为L的文本,所有可能出现的标签序列组合有种。对于序列生成任务如机器翻译来说,抛开一些模型的限定条件,它可能生成的标签序列即目标语种词序列是无限的。
基于上述特点,要解上述问题,需要设计一些方法,将问题结构化,使得模型能够较为高效得去学习,去训练。常用的结构化预测模型有:基于RNN的decoder、卷积网络作为decoder、引入注意力机制的decoder、条件随机场等等。
而常用的训练算法有:
Structured perceptron,structured large margin sampling corruptions of data 使用动态规划算法 使用强化学习或者minimum risk training
总结而言:结构化预测(Structured Prediction)是解决分类或回归问题的框架,其中输出变量相互依赖或约束。它可以被看作是我们利用输出空间中的结构的预测子集,可以理解为上一时刻的输出可以作为下一个预测的输入。结构化预测问题中使用的损失函数将输出视为一个整体。
词性标注任务定义
我们将输入序列单词记为,输出空间(即所有可能的词性目标序列的集合)记为,函数代表和的拟合函数,预测标签可以使用如下公式:
其中$y}^{\star}
y\in Yf(x, y)|S|·m$操作:条件随机场
条件随机场 (CRF, Lafferty et al., 2001 ) 是一种概率图模型,它结合了判别分类和图模型的优点。
3.1 判别式模型与生成式模型
对于分类任务的判别式模型中,我们直接对 建模,相反地生成式模型需要结合和预测结果的贝叶斯推断一起建模。怎么理解这句话?其实很简单,还是回到上面词性标注的任务,如果我们直接基于贪心思想直接基于条件概率构建模型,则它们之间的 本身没有依赖关系,直接变成了联合乘积就结束了。
生成式模型描述了一些标签如何是如何生成一些特征向量 X,而判别模型直接描述如何分配特征向量 X 一个标签。 CRF 是判别模型。
3.2 Probabilistic Graphical Models:概率图模型
概率图模型 (PGM) 将许多变量的复杂分布表示为变量较小子集的局部因素的乘积。生成模型先天然地可以由有向图模型表示,因为它们假设可以 生成,其中,而判别模型是纯天然的无向图模型(单纯的模型 :p ( y∣ x ))。请参见下图中左侧的生成 PGM 和右侧的判别式。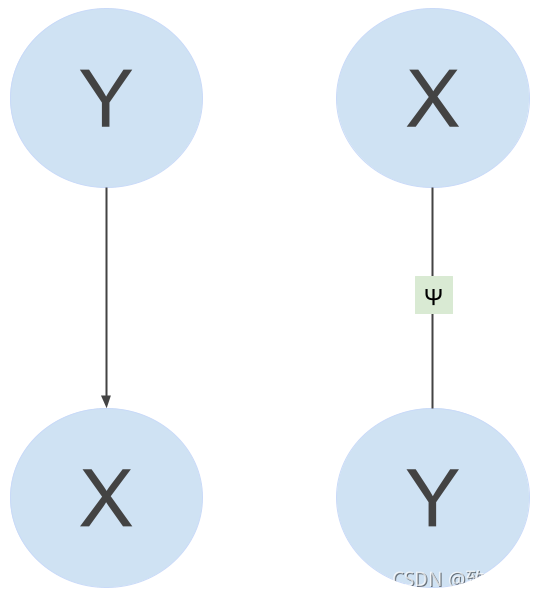
CRF 是判别模型,可以表示为因子图,由公式来建模表示:
表示节点,即随机变量(在此处词性标注任务中是一个pos tag),具体地用为随机变量建模,注意现在是代表了一批随机变量(想象对应一条sequence,包含了很多的tag),为这些随机变量的分布‘’
表示边,即概率依赖关系
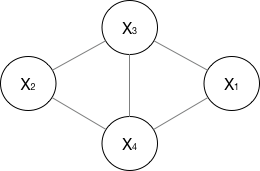
如果一个graph太大,可以用因子分解将 写为若干个联合概率的乘积。咋分解呢,将一个图分为若干个“小团”,注意每个团必须是“最大团”(就是里面任何两个点连在了一块,就是最大连通子图),则有:
其中代表一个最大团a上随机变量的联合概率,下面线性链CRF会解释道。N(a)代表最大团上的节点集合,N代表neighbors 的意思。其中 ,归一化是为了让结果算作概率。基于这种概率图结构,我们可以将CRF应用词性标注任务中,因为我们想要假设当前词性的标签依赖与此前字符的标签,这种基于概率图的CRF也称为 linear-chain CRF。
Linear-Chain CRF
现在我们设计一种针对词性标注的CRF模型,其中假设每一个标签依赖于先前标签,输入序列是词语{x}的序列,如下图“联通子图”表示: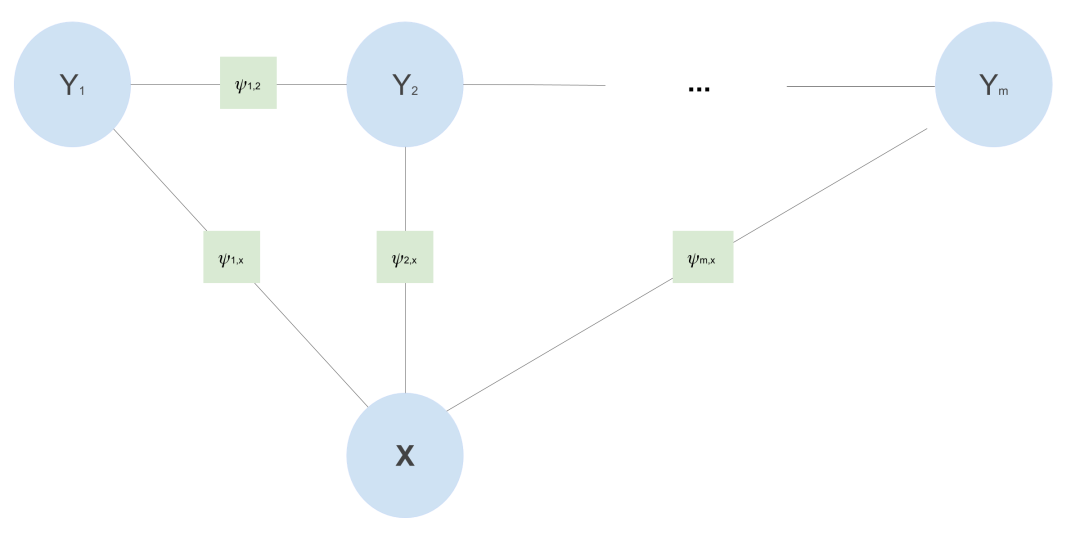 这个特定的线性链 CRF 意味着以下条件独立假设:
这个特定的线性链 CRF 意味着以下条件独立假设:
每个 POS 标签只依赖于它的直接前继和后继和 :
我们可以简单地将上述因子图中的所有因子相乘,得到分解后的条件概率分布:
另外,CRF奏效的一个重要因素是选择子团的计算方式,这个函数通常叫势函数,是一组实值特征函数的线性组合,即和、组合,如下公式所示: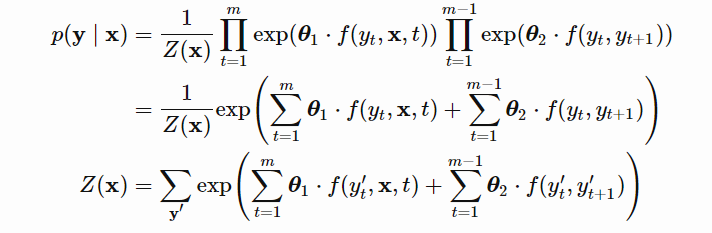 直观上我们可以这么理解上面这个公式,第一个累加和代表时刻的标签预测概率,第二个累加和代表和的同时发生的概率。幸运的是有了深度学习之后,特征函数不需要我们手动构建。就是partition function,来保证公式是一个正确定义的概率分布,保证所有y出现的概率总和为 1。我们看到上面公式的计算还是很麻烦的,接下来就是 belief propagation(消息传播)算法登场了。
直观上我们可以这么理解上面这个公式,第一个累加和代表时刻的标签预测概率,第二个累加和代表和的同时发生的概率。幸运的是有了深度学习之后,特征函数不需要我们手动构建。就是partition function,来保证公式是一个正确定义的概率分布,保证所有y出现的概率总和为 1。我们看到上面公式的计算还是很麻烦的,接下来就是 belief propagation(消息传播)算法登场了。
训练Linear-Chain CRF
我们可以用最大似然估计算法训练 CRF的参数,给定一组 N数据点,使用对似然执行梯度下降算法计算PGM的联合概率,这些可以通过消息传播算法来计算。让我们看一下对数似然:
为了优化参数,我们需要计算对数似然参数的梯度,如下: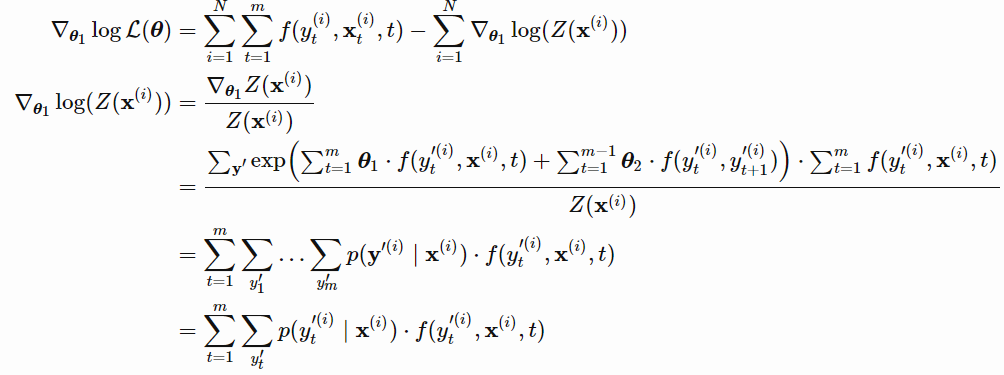
参数的梯度如下: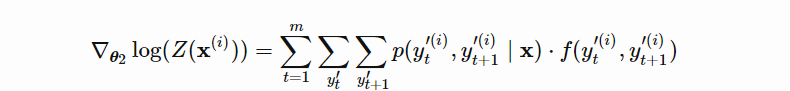
参数推理
条件随机场的概率计算问题就是给定条件随机场,输入序列x和输出序列y,计算提交概率P(Y_i}=y_{i}=y_{i-1},Y_{i}=y_{i}|x)。将问题拆分成多个子问题进行求解:
对于前向概率可以用如下公式计算: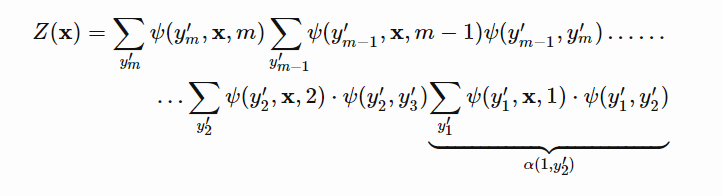 对于最后一项:
对于最后一项: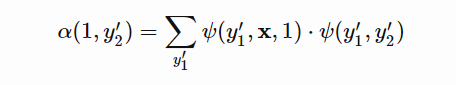 对于后向概率计算:
对于后向概率计算: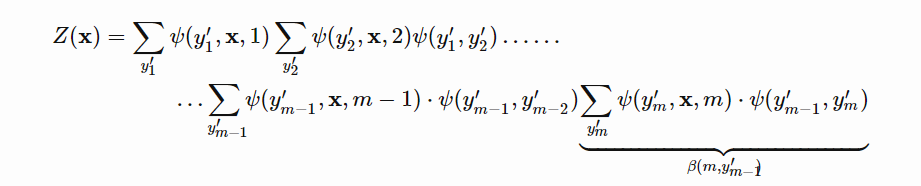 整体概率:
整体概率: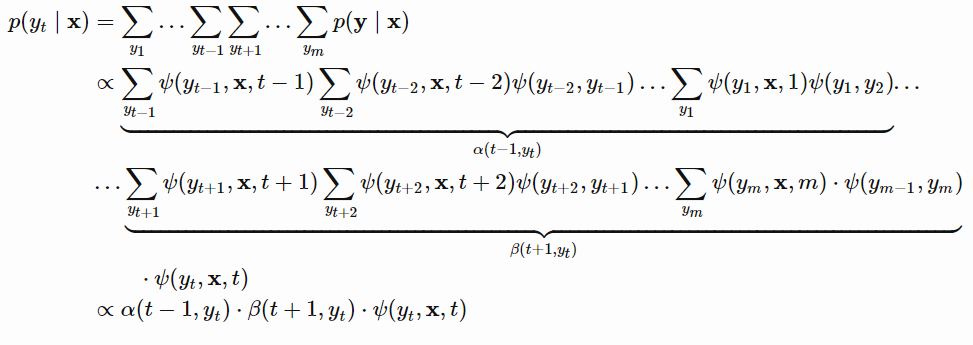 归一化之后:
归一化之后: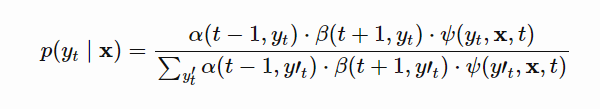
参考资料
Structured Prediction part one - Deriving a Linear-chain CRFCMU NLP课程总结—— Structured Prediction Basics概率图模型体系:HMM、MEMM、CRF
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!