
TransUNet:基于 Transformer 和 CNN 的混合编码网络
Visual Transformer
Author:louwill
Machine Learning Lab
在深度学习医学图像分割领域,UNet结构一直以来都牢牢占据着主导地位。自从2015年提出U形结构以来,后续在UNet基础上做出的魔改网络不可计数。Tranformer结构逐渐开始用于视觉领域之后,基于UNet和Tranformer结合的相关结构和研究逐渐兴起。
UNet用了这么多年,效果好是毋庸置疑的。但硬要是找一些缺点,也不是找不到。由于CNN的平移不变性和捕捉长期依赖能力的不足,UNet在一定程度上依然有较大的提升空间。而Tranformer正好以捕捉序列之间的长期依赖而见长,将Tranformer结构融入到以CNN为主体的UNet中,能否进一步发挥UNet的威力呢?
答案是肯定的。今天我们要介绍的网络叫做TransUNet,正是一种充分结合UNet和Tranformer这两种结构的医学图像分割模型。提出TransUNet的论文为TransUNet:Transformers make strong encoders for medical image segmentation,发表于2021年2月,由约翰霍普金斯大学和电子科技大学等学校联合提出。
TransUNet结构
TransUNet完整结构如图1所示。
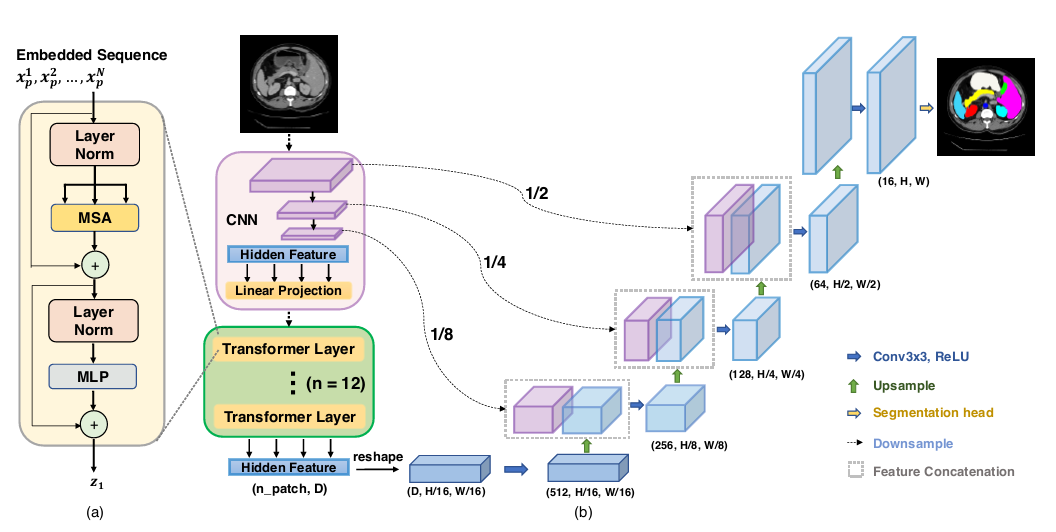
其中图(a)是一层Transformer结构示意图,图(b)是完整的TransUNet架构。Transformer结构不多说,对于图像块嵌入后,行常规的Layer Norm+MSA+MLP+残差连接结构处理。
我们重点看一下图(b)的TransUNet完整架构。完整的结构仍然是U形的编解码结构。先来看编码器部分,这也是TransUNet的关键部分。编码器部分先是对输入图像做了三层卷积下采样,对CNN得到的特征图进行图像块嵌入,同样也是要加位置编码,然后将块嵌入后的一维向量输入到12层Transformer结构中。所以TransUNet编码器的策略是CNN和Transformer混合构建编码器。这也是论文题目中make strong encoders的含义所在。
为什么要混合编码呢?这也是为了各自利用Transformer和CNN的优点来考虑的。Transformer更在注重全局信息,但容易忽略低分辨率下的图像细节,这对于解码器恢复像素尺寸伤害比较大,会导致分割结果很粗糙。而CNN正好可以弥补Transformer的这个缺点。所以混合编码在作者看来是大有裨益的。
然后是解码器,解码器比较简单,就是常规的转置卷积上采样恢复图像像素。同时从编码器的CNN下采样对应过来同层分辨率的级联。这些都属于原始的UNet的固有操作。
TransUNet实验
作者分别在Synapse多器官分割数据集和ACDC (自动化心脏诊断挑战赛)上实验了TransUNet的效果。具体地,对于混合编码器,论文中使用ResNet-50和ViT分别作为CNN和Transformer的backbone,并且都经过了ImageNet的预训练处理。
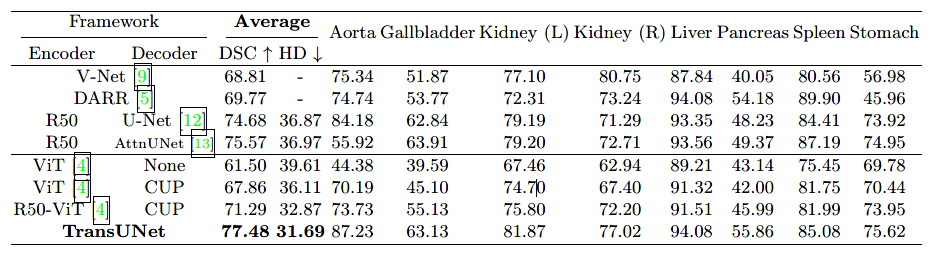
表1是TransUNet与VNet等模型的效果对比。
除了直接的模型精度比对之外,论文中还做了大量的消融实验研究。TransUNet的消融实验主要包括四个方面:1)跳跃连接数,2)输入图像分辨率,3)序列长度和图像分块大小,4)模型大小。
下面我们仅从第一个和第三个方面来看一下TransUNet的消融实验。第一个方面是尝试不同的跳跃连接数来观测模型分割的dice精度。对TransUNet网络分别不做添加、添加1和3条跳跃连接后的实验对比效果如图2所示。
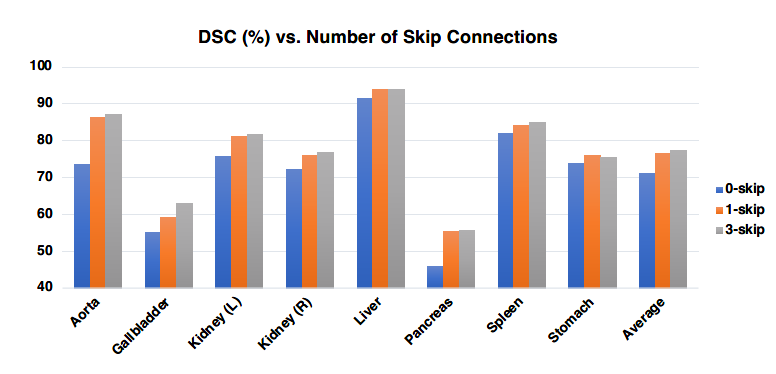
实验结果也再一次强化了跳跃连接对于U形结构分割网络的强大效果。
消融实验的第三个方面是关于图像分块大小和序列长度对于模型精度影响的。当然这两个说的是一回事,图像分块尺寸越小,图像分块数量就越多,也就是序列越长。一般认为,patch size越小,Transformer序列越长,就越能编码出更为复杂的依赖关系。论文中分别实验了32、16和8三个尺寸的patch size,实验效果如表2所示。

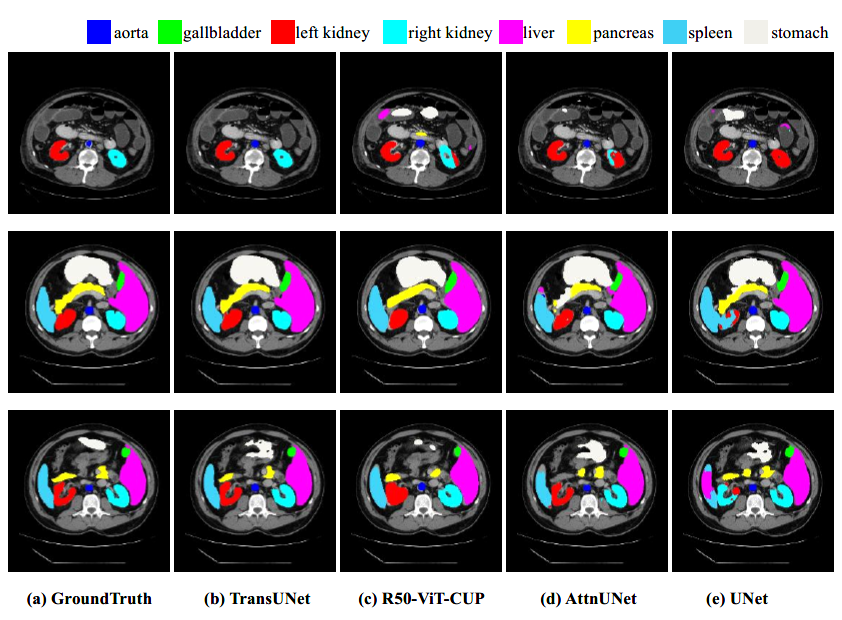
图3显示了TransUNet、R50-ViT-CUP、AttentionUNet和UNet四个模型在多器官分割数据上的可视化效果。从视觉效果上的对比来看,TransUNet无疑是跟Ground Truth最为接近的了。
TransUNet代码实现
TransUNet完整代码实现可参考论文作者提供的仓库:
https://github.com/Beckschen/TransUNet
按照图1的模型架构,TransUNet最后的搭建代码如下所示。
class TransUNet(nn.Module):def __init__(self, config, img_size=224, num_classes=21843, zero_head=False, vis=False):super(VisionTransformer, self).__init__()self.num_classes = num_classesself.zero_head = zero_headself.classifier = config.classifierself.transformer = Transformer(config, img_size, vis)self.decoder = DecoderCup(config)self.segmentation_head = SegmentationHead(in_channels=config['decoder_channels'][-1],out_channels=config['n_classes'],kernel_size=3,)self.config = configdef forward(self, x):if x.size()[1] == 1:x = x.repeat(1,3,1,1)x, attn_weights, features = self.transformer(x) # (B, n_patch, hidden)x = self.decoder(x, features)logits = self.segmentation_head(x)return logits
总结
TransUNet是率先将Transformer结构用于医学图像分割工作的研究。TransUNet将重视全局信息的Transformer结构和底层图像特征的CNN一起进行混合编码,能够更大程度上提升UNet的分割效果。
参考资料:
Chen J, Lu Y, Yu Q, et al. Transunet: Transformers make strong encoders for medical image segmentation[J]. arXiv preprint arXiv:2102.04306, 2021.
往期精彩:
ViT:视觉Transformer backbone网络ViT论文与代码详解
求个在看