
再见 CSV,速度提升 150 倍!(留言送书)

为什么要和CSV再见?
CSV再见。其实也谈不上彻底再见吧,日常还是要用的,这里再介绍一个更加高效的数据格式。Python处理数据时保存和加载文件属于日常操作了,尤其面对大数据量时我们一般都会保存成CSV格式,而不是Excel。一是因为Excel有最大行数1048576的限制,二是文件占用空间更大,保存和加载速度很慢。CSV没有行数限制,相对轻便,但是面对大数据量时还是略显拉夸,百万数据量储存加载时也要等好久。。不过很多同学都借此机会抻抻懒腰、摸摸鱼,充分利用时间也不错 。
。CSV 并不是唯一的数据存储格式。今天和大家介绍一个速度超快、更加轻量级的二进制格式保存格式:feather。Feather是什么?
Feather 是一种用于存储数据帧的数据格式。它最初是为了 Python 和 R 之间快速交互而设计的,初衷很简单,就是尽可能高效地完成数据在内存中转换的效率。Feather 也不仅限于 Python 和 R 了,基本每种主流的编程语言中都可以用 Feather 文件。不过,要说明下,它的数据格式并不是为长期存储而设计的,一般的短期存储。如何在Python中操作Feather?
Python 中,可以通过 pandas 或 Feather 两种方式操作。首先需要安装feather-format。# pip
pip install feather -format
# Anaconda
conda install -c conda-forgefeather-format
Feather、Numpy 和 pandas 来一起配合。数据集有 5 列和 1000 万行随机数。import feather
import numpy as np
import pandas as pd
np.random.seed = 42
df_size = 10000000
df = pd.DataFrame({
'a': np.random.rand(df_size),
'b': np.random.rand(df_size),
'c': np.random.rand(df_size),
'd': np.random.rand(df_size),
'e': np.random.rand(df_size)
})
df.head()
csv的操作难度一个水平线,非常简单。DataFrame 直接to_feather 的 Feather 格式:df.to_feather('1M.feather')
Feather 库执行相同操作的方法:feather.write_dataframe(df, '1M.feather')
pandas加载:df = pd.read_feather('1M.feather')
Feather 加载:df =feather.read_dataframe('1M.feather')
和CSV的区别
feather和csv的差距有多大。下图显示了上面本地保存 DataFrame 所需的时间: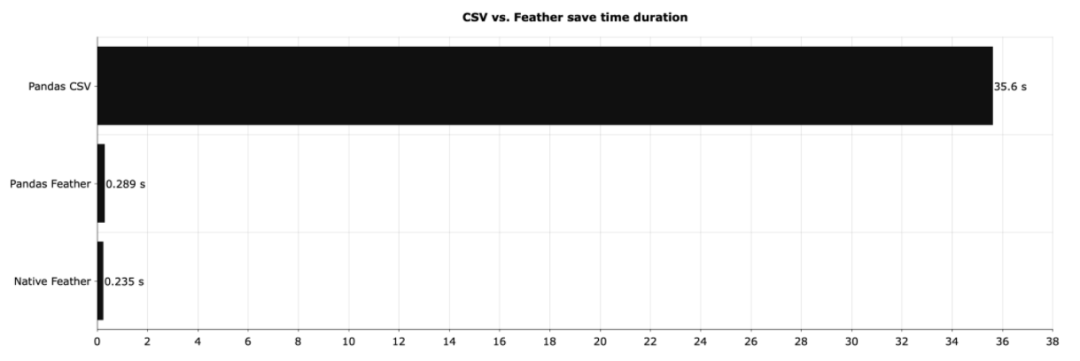
Feather(图中的Native Feather)比 CSV 快了将近 150 倍左右。如果使用 pandas 处理 Feather 文件并没有太大关系,但与 CSV 相比,速度的提高是非常显著的。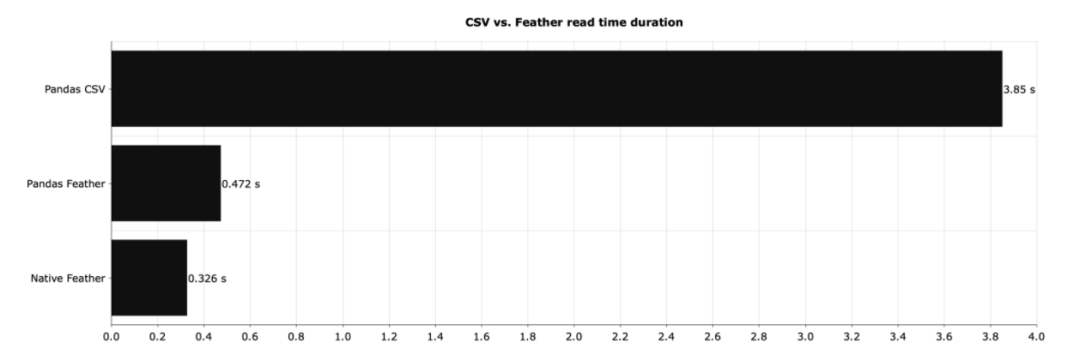
CSV 的读取速度要慢得多。并且CSV占用的磁盘空间也更大。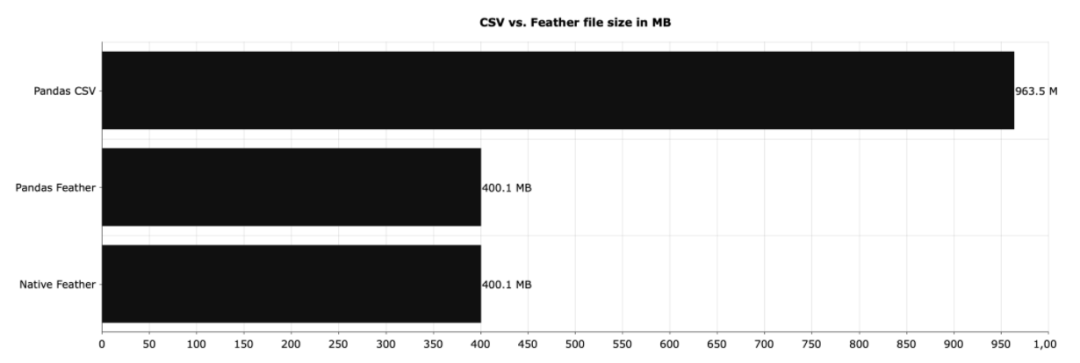
CSV 文件占用的空间是 Feather 文件占用的空间的两倍多。假如我们每天存储千兆字节的数据,那么选择正确的文件格式至关重要。Feather 在这方面完全碾压了 CSV。Parquet,也是一个可以替代CSV 的格式。结语
 。 这个东西怎么说呢
。 这个东西怎么说呢 ,当你需要它时,它就有用,如果日常没有速度和空间的强烈需求,还是老老实实
,当你需要它时,它就有用,如果日常没有速度和空间的强烈需求,还是老老实实CSV吧。CSV已经用惯了,改变使用习惯还是挺难的。

留言送书


推荐理由:
第1部分是基础篇,带领初学者实践Python开发环境和掌握基本语法,同时对网络协议、Web客户端技术、数据库建模编程等网络编程基础深入浅出地进行学习;
推荐理由:
(1)实战技能:本书讲解了Python编程从入门到精通可能涉及的100个关键技能。
推荐理由:
本书既适合非计算机专业出身的编程初学者,也适合即将走上工作岗位的广大毕业生,或已经有编程经验但想转行做Python应用开发的专业人士。同时,本书还可以作为广大职业院校、计算机培训班的教学参考用书。
推荐理由:
随着网络技术的迅速发展,如何有效地提取并利用信息,以及如何有效地防止信息被爬取,已成为一个巨大的挑战。本书从零基础开始讲解,系统全面,案例丰富,注重实战,既适合Python程序员和爬虫爱好者阅读学习,也可以作为广大职业院校相关专业的教材或参考用书。础操作、图形处理基本操作、简单图形的绘制和对象的管理等内容
推荐理由:
本书主要讲解数据分析与大数据处理所需的技术、基础设施、核心概念、实施流程。从编程语言准备、数据采集与清洗、数据分析与可视化,到大型数据的分布式存储与分布式计算,贯穿了整个大数据项目开发流程。本书轻理论、重实践,目的是让读者快速上手。
推荐理由:
专注于Python数据分析与可视化操作中实际用到的技术。相比大而全的书籍资料,本书能让读者尽快上手,开始项目开发。本书以“零基础”为起点,系统地介绍了Python在数据处理与可视化分析方面的应用
推荐理由:
理论性与实用性兼备,既可作为初学者的入门书籍,也可作为求职者的面试宝典,更可作为职场人士转岗的实用手册。本书适合需要全面学习机器学习算法的初学者、希望掌握机器学习算法数学理论的程序员、想转行从事机器学习算法的专业人员、对机器学习算法兴趣浓厚的人员、专业培训机构学员和希望提高Python编程水平的程序员。
推荐理由:
本书以零基础讲解为宗旨,面向学习数据科学与人工智能的读者,通俗地讲解每一个知识点,旨在帮助读者快速打下数学基础。本书适合准备从事数据科学与人工智能相关行业的读者。
推荐理由:
本书首先介绍算法的概念和特点,然后介绍数据结构,再逐步深入介绍各类算法,通过解决实际问题加深理解。本书选取了近年来比较热门的语言Python作为载体,来实现算法的功能。这不但可以让读者系统地学习算法的相关知识,而且还能提高读者对Python语言的应用水平。
活动规则:
活动截止时我们将从本文的精选留言中选出 九位粉丝的走心留言赠送书籍,以上书籍任选一本免费包邮赠送~
活动截止时间: 2021 年 9 月 22 日 16:00 整
悄悄告诉你,群内不仅仅和以上送书活动同步,还有红包送哦~
进群方法:
扫描下方二维码,添加小编微信,邀请进群
往期推荐
今天因为您的点赞和在看,让我元气满满!
悄悄告诉你,群内不仅仅和以上送书活动同步,还有红包送哦~
进群方法:
扫描下方二维码,添加小编微信,邀请进群
往期推荐
进群方法:
扫描下方二维码,添加小编微信,邀请进群
今天因为您的点赞和在看,让我元气满满!