
面霸篇:Java 核心集合容器全解(核心卷二)
共 19351字,需浏览 39分钟
·
2021-09-27 17:09
从面试角度作为切入点提升大家的 Java 内功,所谓根基不牢,地动山摇。
码哥在 《Redis 系列》的开篇 Redis 为什么这么快中说过:学习一个技术,通常只接触了零散的技术点,没有在脑海里建立一个完整的知识框架和架构体系,没有系统观。这样会很吃力,而且会出现一看好像自己会,过后就忘记,一脸懵逼。
我们需要一个系统观,清晰完整的去学习技术,在「面霸篇:Java 核心基础大满贯(卷一)」中,码哥梳理了 Java 高频核心知识点。
本篇将一举攻破 Java 集合容器知识点,跟着「码哥」一起来提纲挈领,梳理一个完整的 Java 容器开发技术能力图谱,将基础夯实。
什么是集合?
集合的特点
集合与数组的区别
集合框架有哪些优势
有哪些常用的集合类
集合的底层数据结构
Collection
Map
集合的 fail-fast 快速失败机制
List 接口
Itertator 是什么
如何边遍历边移除 Collection 中的元素?
如何实现数组和 List 之间的转换?
ArrayList 和 LinkedList 的区别是什么?
为什么 ArrayList 的 elementData 加上 transient 修饰?
介绍下 CopyOnWriteArrayList?
List、Set、Map 三者的区别?
Set 接口
说一下 HashSet 的实现原理?
Queue
BlockingQueue 是什么?
在 Queue 中 poll()和 remove()有什么区别?
Map 接口
HashMap 的实现原理?
JDK1.7 VS JDK1.8 比较
如何有效避免哈希碰撞
HashMap 的 put 方法的具体流程?
HashMap 的扩容操作是怎么实现的?
任何类都可以作为 Key 么?
为什么 HashMap 中 String、Integer 这样的包装类适合作为 K?
HashMap 为什么不直接使用 hashCode()处理后的哈希值直接作为 table 的下标?
HashMap 的长度为什么是 2 的幂次方
HashMap 和 ConcurrentHashMap 的区别
ConcurrentHashMap 实现原理
点击下方卡片,关注「码哥字节」
集合容器概述
什么是集合?
顾名思义,集合就是用于存储数据的容器。
集合框架是为表示和操作集合而规定的一种统一的标准的体系结构。任何集合框架都包含三大块内容:对外的接口、接口的实现和对集合运算的算法。
❝码老湿,可以说下集合框架的三大块内容具体指的是什么吗?
接口
面向接口编程,抽象出集合类型,使得我们可以在操作集合的时候不必关心具体实现,达到「多态」。
就好比密码箱,我们只关心能打开箱子,存放东西,并且关闭箱子,至于怎么加密咱们不关心。
接口实现
每种集合的具体实现,是重用性很高的数据结构。
算法
集合提供了数据存放以及查找、排序等功能,集合有很多种,也就是算法通常也是多态的,因为相同的方法可以在同一个接口被多个类实现时有不同的表现。
事实上,算法是可复用的函数。它减少了程序设计的辛劳。
集合框架通过提供有用的数据结构和算法使你能集中注意力于你的程序的重要部分上,而不是为了让程序能正常运转而将注意力于低层设计上。
集合的特点
对象封装数据,多个对象需要用集合存储; 对象的个数可以确定使用数组更高效,不确定个数的情况下可以使用集合,因为集合是可变长度。
集合与数组的区别
数组是固定长度的;集合可变长度的。 数组可以存储基本数据类型,也可以存储引用数据类型;集合只能存储引用数据类型。 数组存储的元素必须是同一个数据类型;集合存储的对象可以是不同数据类型。
由于有多种集合容器,因为每一个容器的自身特点不同,其实原理在于每个容器的内部数据结构不同。
集合容器在不断向上抽取过程中,出现了集合体系。在使用一个体系的原则:参阅顶层内容。建立底层对象。
集合框架有哪些优势
容量自动增长扩容; 提供高性能的数据结构和算法; 可以方便地扩展或改写集合,提高代码复用性和可操作性。 通过使用 JDK 自带的集合类,可以降低代码维护和学习新 API 成本。
有哪些常用的集合类
Java 容器分为 Collection 和 Map 两大类,Collection 集合的子接口有 Set、List、Queue 三种子接口。
我们比较常用的是 Set、List,Map 接口不是 collection 的子接口。
Collection 集合主要有 List 和 Set 两大接口
List:一个有序(元素存入集合的顺序和取出的顺序一致)容器,元素可以重复,可以插入多个 null 元素,元素都有索引。常用的实现类有 ArrayList、LinkedList 和 Vector。 Set:一个无序(存入和取出顺序有可能不一致)容器,不可以存储重复元素,只允许存入一个 null 元素,必须保证元素唯一性。 Set 接口常用实现类是 HashSet、LinkedHashSet 以及 TreeSet。
Map 是一个键值对集合,存储键、值和之间的映射。Key 无序,唯一;value 不要求有序,允许重复。
Map 没有继承于 Collection 接口,从 Map 集合中检索元素时,只要给出键对象,就会返回对应的值对象。
Map 的常用实现类:HashMap、TreeMap、HashTable、LinkedHashMap、ConcurrentHashMap
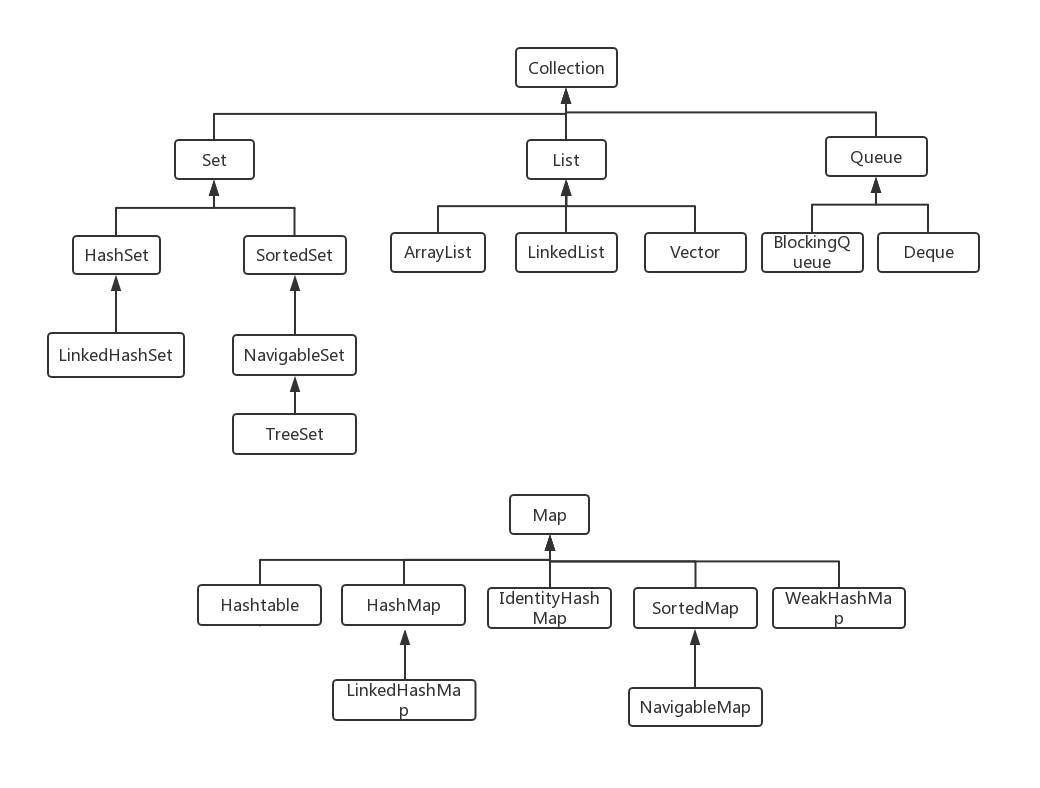
集合的底层数据结构
Collection
List
ArrayList:Object 数组; Vector:Object 数组; LinkedList:双向循环链表; Set
HashSet:唯一,无序。基于 HashMap 实现,底层采用 HashMap 保存数据。
它不允许集合中有重复的值,当我们提到 HashSet 时,第一件事情就是在将对象存储在 HashSet 之前,要先确保对象重写 equals()和 hashCode()方法,这样才能比较对象的值是否相等,以确保 set 中没有储存相等的对象。
如果我们没有重写这两个方法,将会使用这个方法的默认实现。
LinkedHashSet:LinkedHashSet 继承与 HashSet,底层使用 LinkedHashMap 来保存所有元素。
TreeSet(有序,唯一):红黑树(自平衡的排序二叉树。)
Map
HashMap:JDK1.8 之前 HashMap 由数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。
JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树,以减少搜索时间。
LinkedHashMap:LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。
内部还有一个双向链表维护键值对的顺序,每个键值对既位于哈希表中,也位于双向链表中。
LinkedHashMap 支持两种顺序插入顺序 、 访问顺序。
插入顺序:先添加的在前面,后添加的在后面。修改操作不影响顺序 访问顺序:所谓访问指的是 get/put 操作,对一个键执行 get/put 操作后,其对应的键值对会移动到链表末尾,所以最末尾的是最近访问的,最开始的是最久没有被访问的,这就是访问顺序。 HashTable:数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的
TreeMap:红黑树(自平衡的排序二叉树)
集合的 fail-fast 快速失败机制
Java 集合的一种错误检测机制,当多个线程对集合进行结构上的改变的操作时,有可能会产生 fail-fast 机制。
原因:迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个 modCount 变量。
集合在被遍历期间如果内容发生变化,就会改变 modCount 的值。
每当迭代器使用 hashNext()/next()遍历下一个元素之前,都会检测 modCount 变量是否为 expectedmodCount 值,是的话就返回遍历;否则抛出异常,终止遍历。
解决办法:
在遍历过程中,所有涉及到改变 modCount 值得地方全部加上 synchronized。 使用 CopyOnWriteArrayList 来替换 ArrayList
Collection 接口
List 接口
Itertator 是什么
Iterator 接口提供遍历任何 Collection 的接口。我们可以从一个 Collection 中使用迭代器方法来获取迭代器实例。
迭代器取代了 Java 集合框架中的 Enumeration,迭代器允许调用者在迭代过程中移除元素。
List<String> list = new ArrayList<>();
Iterator<String> it = list. iterator();
while(it. hasNext()){
String obj = it. next();
System. out. println(obj);
}
如何边遍历边移除 Collection 中的元素?
Iterator<Integer> it = list.iterator();
while(it.hasNext()){
*// do something*
it.remove();
}
一种最常见的错误代码如下:
for(Integer i : list){
list.remove(i)
}
运行以上错误代码会报 ConcurrentModificationException 异常。
如何实现数组和 List 之间的转换?
数组转 List:使用 Arrays. asList(array) 进行转换。 List 转数组:使用 List 自带的 toArray() 方法。
ArrayList 和 LinkedList 的区别是什么?
数据结构实现:ArrayList 是动态数组的数据结构实现,而 LinkedList 是双向链表的数据结构实现。 随机访问效率:ArrayList 比 LinkedList 在随机访问的时候效率要高,因为 LinkedList 是线性的数据存储方式,所以需要移动指针从前往后依次查找。 增加和删除效率:在非首尾的增加和删除操作,LinkedList 要比 ArrayList 效率要高,因为 ArrayList 增删操作要影响数组内的其他数据的下标。 内存空间占用:LinkedList 比 ArrayList 更占内存,因为 LinkedList 的节点除了存储数据,还存储了两个引用,一个指向前一个元素,一个指向后一个元素。 线程安全:ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
综合来说,在需要频繁读取集合中的元素时,更推荐使用 ArrayList,而在插入和删除操作较多时,更推荐使用 LinkedList。
为什么 ArrayList 的 elementData 加上 transient 修饰?
ArrayList 中的数组定义如下:
private transient Object[] elementData;
ArrayList 的定义:
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
ArrayList 实现了 Serializable 接口,这意味着 ArrayList 支持序列化。
transient 的作用是说不希望 elementData 数组被序列化。
每次序列化时,先调用 defaultWriteObject()方法序列化 ArrayList中的非 transient元素,然后遍历 elementData,只序列化已存入的元素,这样既加快了序列化的速度,又减小了序列化之后的文件大小。
介绍下 CopyOnWriteArrayList?
CopyOnWriteArrayList 是 ArrayList 的线程安全版本,也是大名鼎鼎的 copy-on-write(COW,写时复制)的一种实现。
在读操作时不加锁,跟 ArrayList 类似;在写操作时,复制出一个新的数组,在新数组上进行操作,操作完了,将底层数组指针指向新数组。
适合使用在读多写少的场景。例如 add(Ee)方法的操作流程如下:使用 ReentrantLock 加锁,拿到原数组的 length,使用 Arrays.copyOf 方法从原数组复制一个新的数组(length+1),将要添加的元素放到新数组的下标 length 位置,最后将底层数组指针指向新数组。
List、Set、Map 三者的区别?
List(对付顺序的好帮手):存储的对象是可重复的、有序的。 Set(注重独一无二的性质):存储的对象是不可重复的、无序的。 Map(用 Key 来搜索的专业户):存储键值对(key-value),不能包含重复的键(key),每个键只能映射到一个值。
Set 接口
说一下 HashSet 的实现原理?
HashSet底层原理完全就是包装了一下HashMapHashSet的唯一性保证是依赖与hashCode()和equals()两个方法,所以存入对象的时候一定要自己重写这两个方法来设置去重的规则。HashSet中的元素都存放在HashMap的key上面,而value中的值都是统一的一个 private static final Object PRESENT = new Object();
hashCode()与 equals()的相关规定:
如果两个对象相等,则 hashcode 一定也是相同的 两个对象相等,对两个 equals 方法返回 true 两个对象有相同的 hashcode 值,它们也不一定是相等的 综上,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖 hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。
==与 equals 的区别
==是判断两个变量或实例是不是指向同一个内存空间equals是判断两个变量或实例所指向的内存空间的值是不是相同==是指对内存地址进行比较equals()是对字符串的内容进行比较==指引用是否相同,equals()指的是值是否相同。
Queue
BlockingQueue 是什么?
Java.util.concurrent.BlockingQueue 是一个队列,在进行检索或移除一个元素的时候,线程会等待队列变为非空;
当在添加一个元素时,线程会等待队列中的可用空间。
BlockingQueue 接口是 Java 集合框架的一部分,主要用于实现生产者-消费者模式。
Java 提供了几种 BlockingQueue的实现,比如ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue、SynchronousQueue等。
在 Queue 中 poll()和 remove()有什么区别?
相同点:都是返回第一个元素,并在队列中删除返回的对象。 不同点:如果没有元素 poll()会返回 null,而 remove()会直接抛出 NoSuchElementException 异常。
Map 接口
Map 整体结构如下所示:
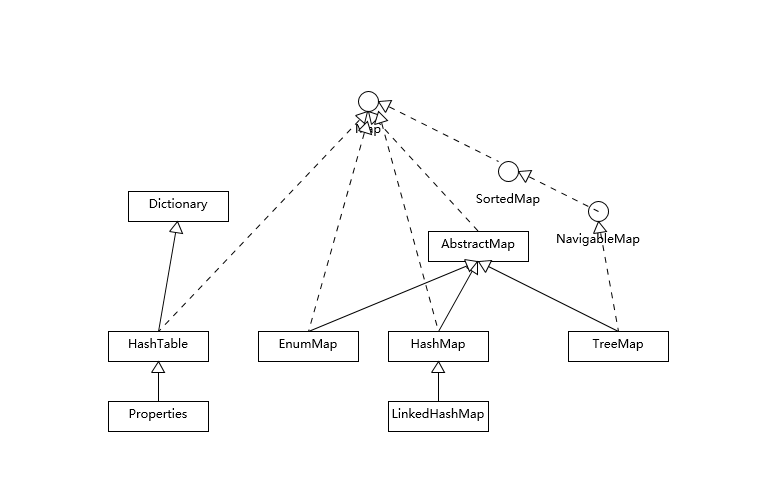
Hashtable 比较特别,作为类似 Vector、Stack 的早期集合相关类型,它是扩展了 Dictionary 类的,类结构上与 HashMap 之类明显不同。
HashMap 等其他 Map 实现则是都扩展了 AbstractMap,里面包含了通用方法抽象。
不同 Map 的用途,从类图结构就能体现出来,设计目的已经体现在不同接口上。
HashMap 的实现原理?
在 JDK 1.7 中 HashMap 是以数组加链表的形式组成的,JDK 1.8 之后新增了红黑树的组成结构,当链表大于 8 并且容量大于 64 时,链表结构会转换成红黑树结构。
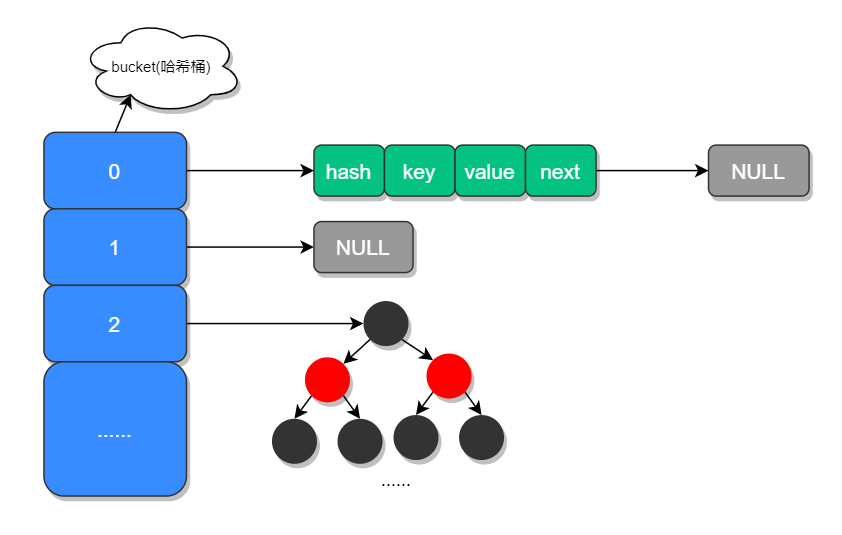
HashMap 基于 Hash 算法实现的:
当我们往 Hashmap 中 put 元素时,利用 key 的 hashCode 重新 hash 计算出当前对象的元素在数组中的下标。 存储时,如果出现 hash 值相同的 key,此时有两种情况。 如果 key 相同,则覆盖原始值; 如果 key 不同(出现冲突),则将当前的 key-value 放入链表中 获取时,直接找到 hash 值对应的下标,在进一步判断 key 是否相同,从而找到对应值。 理解了以上过程就不难明白 HashMap 是如何解决 hash 冲突的问题,核心就是使用了数组的存储方式,然后将冲突的 key 的对象放入链表中,一旦发现冲突就在链表中做进一步的对比。
JDK1.7 VS JDK1.8 比较
JDK1.8 主要解决或优化了一下问题:
resize 扩容优化 引入了红黑树,目的是避免单条链表过长而影响查询效率,红黑树算法请参考 解决了多线程死循环问题,但仍是非线程安全的,多线程时可能会造成数据丢失问题。
| 不同 | JDK 1.7 | JDK 1.8 |
|---|---|---|
| 存储结构 | 数组 + 链表 | 数组 + 链表 + 红黑树 |
| 初始化方式 | 单独函数:inflateTable() | 直接集成到了扩容函数resize()中 |
| hash 值计算方式 | 扰动处理 = 9 次扰动 = 4 次位运算 + 5 次异或运算 | 扰动处理 = 2 次扰动 = 1 次位运算 + 1 次异或运算 |
| 存放数据的规则 | 无冲突时,存放数组;冲突时,存放链表 | 无冲突时,存放数组;冲突 & 链表长度 < 8:存放单链表;冲突 & 链表长度 > 8:树化并存放红黑树 |
| 插入数据方式 | 头插法(先讲原位置的数据移到后 1 位,再插入数据到该位置) | 尾插法(直接插入到链表尾部/红黑树) |
| 扩容后存储位置的计算方式 | 全部按照原来方法进行计算(即 hashCode ->> 扰动函数 ->> (h&length-1)) | 按照扩容后的规律计算(即扩容后的位置=原位置 or 原位置 + 旧容量) |
如何有效避免哈希碰撞
主要是因为如果使用 hashCode 取余,那么相当于参与运算的只有 hashCode 的低位,高位是没有起到任何作用的。
所以我们的思路就是让 hashCode 取值出的高位也参与运算,进一步降低 hash 碰撞的概率,使得数据分布更平均,我们把这样的操作称为扰动,在JDK 1.8中的 hash()函数如下:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);// 与自己右移16位进行异或运算(高低位异或)
}
HashMap 的 put 方法的具体流程?
当我们 put 的时候,首先计算 key的hash值,这里调用了 hash方法,hash方法实际是让key.hashCode()与key.hashCode()>>>16进行异或操作,高 16bit 补 0,一个数和 0 异或不变,所以 hash 函数大概的作用就是:高 16bit 不变,低 16bit 和高 16bit 做了一个异或,目的是减少碰撞。
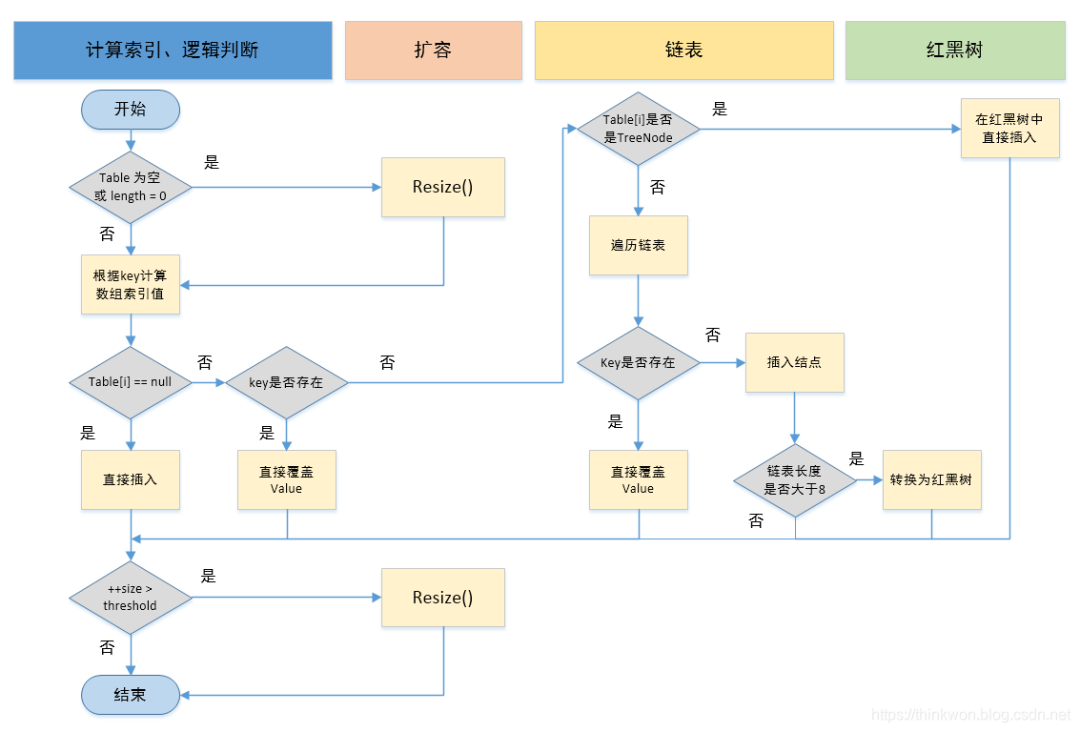
①.判断键值对数组 table[i]是否为空或为 null,否则执行 resize()进行扩容;
②.根据键值 key 计算 hash 值得到插入的数组索引 i,如果 table[i]==null,直接新建节点添加,转向 ⑥,如果 table[i]不为空,转向 ③;
③.判断 table[i]的首个元素是否和 key 一样,如果相同直接覆盖 value,否则转向 ④,这里的相同指的是 hashCode 以及 equals;
④.判断 table[i] 是否为 treeNode,即 table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向 ⑤;
⑤.遍历 table[i],判断链表长度是否大于 8,大于 8 的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现 key 已经存在直接覆盖 value 即可;
⑥.插入成功后,判断实际存在的键值对数量 size 是否超多了最大容量 threshold,如果超过,进行扩容。
HashMap 的扩容操作是怎么实现的?
①.在 jdk1.8 中,resize 方法是在 hashmap 中的键值对大于阀值时或者初始化时,就调用 resize 方法进行扩容;
②.每次扩展的时候,都是扩展 2 倍;
③.扩展后 Node 对象的位置要么在原位置,要么移动到原偏移量两倍的位置。
在 1.7 中,扩容之后需要重新去计算其 Hash 值,根据 Hash 值对其进行分发.
但在 1.8 版本中,则是根据在同一个桶的位置中进行判断(e.hash & oldCap)是否为 0,0 -表示还在原来位置,否则就移动到原数组位置 + oldCap。
重新进行 hash 分配后,该元素的位置要么停留在原始位置,要么移动到原始位置+增加的数组大小这个位置上。
任何类都可以作为 Key 么?
可以使用任何类作为 Map 的 key,然而在使用之前,需要考虑以下几点:
如果类重写了 equals() 方法,也应该重写 hashCode() 方法。
类的所有实例需要遵循与 equals() 和 hashCode() 相关的规则。
如果一个类没有使用 equals(),不应该在 hashCode() 中使用它。
用户自定义 Key 类最佳实践是使之为不可变的,这样 hashCode() 值可以被缓存起来,拥有更好的性能。
不可变的类也可以确保 hashCode() 和 equals() 在未来不会改变,这样就会解决与可变相关的问题了。
为什么 HashMap 中 String、Integer 这样的包装类适合作为 K?
String、Integer 等包装类的特性能够保证 Hash 值的不可更改性和计算准确性,能够有效的减少 Hash 碰撞的几率。
都是 final 类型,即不可变性,保证 key 的不可更改性,不会存在获取 hash 值不同的情况 内部已重写了 equals()、hashCode()等方法,遵守了 HashMap 内部的规范(不清楚可以去上面看看 putValue 的过程),不容易出现 Hash 值计算错误的情况;
HashMap 为什么不直接使用 hashCode()处理后的哈希值直接作为 table 的下标?
hashCode()方法返回的是 int 整数类型,其范围为-(2 ^ 31)~(2 ^ 31 - 1),约有 40 亿个映射空间,而 HashMap 的容量范围是在 16(初始化默认值)~2 ^ 30,HashMap 通常情况下是取不到最大值的,并且设备上也难以提供这么多的存储空间,从而导致通过hashCode()计算出的哈希值可能不在数组大小范围内,进而无法匹配存储位置;
HashMap 的长度为什么是 2 的幂次方
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀,每个链表/红黑树长度大致相同。这个实现就是把数据存到哪个链表/红黑树中的算法。
这个算法应该如何设计呢?
我们首先可能会想到采用 % 取余的操作来实现。
但是,重点来了:取余(%)操作中如果除数是 2 的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是 2 的 n 次方;)。
并且采用二进制位操作 &,相对于 % 能够提高运算效率,这就解释了 HashMap 的长度为什么是 2 的幂次方。
那为什么是两次扰动呢?
答:这样就是加大哈希值低位的随机性,使得分布更均匀,从而提高对应数组存储下标位置的随机性&均匀性,最终减少 Hash 冲突,两次就够了,已经达到了高位低位同时参与运算的目的;
HashMap 和 ConcurrentHashMap 的区别
ConcurrentHashMap 对整个桶数组进行了分割分段(Segment),每一个分段上都用 lock 锁进行保护,相对于 HashTable 的 synchronized 锁的粒度更精细了一些,并发性能更好,而 HashMap 没有锁机制,不是线程安全的。(JDK1.8 之后 ConcurrentHashMap 启用了一种全新的方式实现,利用 synchronized + CAS 算法。) HashMap 的键值对允许有 null,但是 ConCurrentHashMap 都不允许。
ConcurrentHashMap 实现原理
JDK1.7
首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
在 JDK1.7 中,ConcurrentHashMap 采用 Segment + HashEntry 的方式进行实现,结构如下:
一个 ConcurrentHashMap 里包含一个 Segment 数组。
Segment 的结构和 HashMap 类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个 HashEntry 数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 的锁。
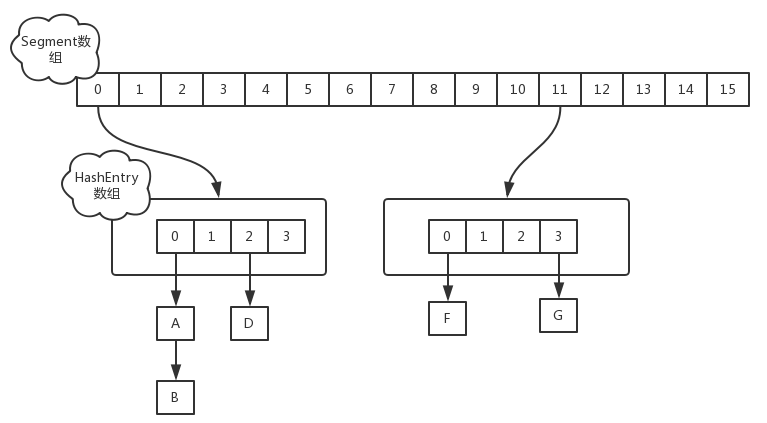
该类包含两个静态内部类 HashEntry 和 Segment ;前者用来封装映射表的键值对,后者用来充当锁的角色; HashEntry 内部使用 volatile 的 value 字段来保证可见性,get 操作需要保证的是可见性,所以并没有什么同步逻辑。 Segment 是一种可重入的锁 ReentrantLock,每个 Segment 守护一个 HashEntry 数组里得元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 锁。
get 操作需要保证的是可见性,所以并没有什么同步逻辑
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key.hashCode());
//利用位操作替换普通数学运算
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// 以Segment为单位,进行定位
// 利用Unsafe直接进行volatile access
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
//省略
}
return null;
}
而对于 put 操作,首先是通过二次哈希避免哈希冲突,然后以 Unsafe 调用方式,直接获取相应的 Segment,然后进行线程安全的 put 操作:
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
// 二次哈希,以保证数据的分散性,避免哈希冲突
int hash = hash(key.hashCode());
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
其核心逻辑实现在下面的内部方法中:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// scanAndLockForPut会去查找是否有key相同Node
// 无论如何,确保获取锁
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
// 更新已有value...
}
else {
// 放置HashEntry到特定位置,如果超过阈值,进行rehash
// ...
}
}
} finally {
unlock();
}
return oldValue;
}
JDK1.8
在JDK1.8 中,放弃了 Segment 臃肿的设计,取而代之的是采用 Node + CAS + Synchronized 来保证并发安全进行实现。
synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,效率又提升 N 倍。
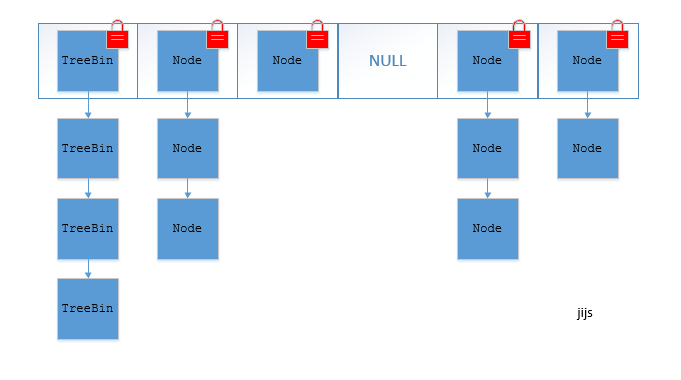
总体结构上,它的内部存储和 HashMap 结构非常相似,同样是大的桶(bucket)数组,然后内部也是一个个所谓的链表结构(bin),同步的粒度要更细致一些。
其内部仍然有 Segment 定义,但仅仅是为了保证序列化时的兼容性而已,不再有任何结构上的用处。
因为不再使用 Segment,初始化操作大大简化,修改为 lazy-load 形式,这样可以有效避免初始开销,解决了老版本很多人抱怨的这一点。
数据存储利用 volatile 来保证可见性。
使用 CAS 等操作,在特定场景进行无锁并发操作。
使用 Unsafe、LongAdder 之类底层手段,进行极端情况的优化。
另外,需要注意的是,“线程安全”这四个字特别容易让人误解,因为ConcurrentHashMap 只能保证提供的原子性读写操作是线程安全的。
误区
我们来看一个使用 Map 来统计 Key 出现次数的场景吧,这个逻辑在业务代码中非常常见。
开发人员误以为使用了 ConcurrentHashMap 就不会有线程安全问题,于是不加思索地写出了下面的代码:
在每一个线程的代码逻辑中先通过 containsKey 方法判断可以 是否存在。 key 存在则 + 1,否则初始化 1.
// 共享数据
ConcurrentHashMap<String, Long> freqs = new ConcurrentHashMap<>(ITEM_COUNT);
public void normaluse(String key) throws InterruptedException {
if (freqs.containsKey(key)) {
//Key存在则+1
freqs.put(key, freqs.get(key) + 1);
} else {
//Key不存在则初始化为1
freqs.put(key, 1L);
}
}
大错特错啊朋友们,需要注意 ConcurrentHashMap 对外提供的方法或能力的限制:
使用了 ConcurrentHashMap,不代表对它的多个操作之间的状态是一致的,是没有其他线程在操作它的,如果需要确保需要手动加锁。
诸如 size、isEmpty 和 containsValue 等聚合方法,在并发情况下可能会反映 ConcurrentHashMap 的中间状态。
因此在并发情况下,这些方法的返回值只能用作参考,而不能用于流程控制。
显然,利用 size 方法计算差异值,是一个流程控制。
诸如 putAll 这样的聚合方法也不能确保原子性,在 putAll 的过程中去获取数据可能会获取到部分数据。
正确写法:
//利用computeIfAbsent()方法来实例化LongAdder,然后利用LongAdder来进行线程安全计数
freqs.computeIfAbsent(key, k -> new LongAdder()).increment();
使用 ConcurrentHashMap 的原子性方法 computeIfAbsent 来做复合逻辑操作,判断 Key 是否存在 Value,如果不存在则把 Lambda 表达式运行后的结果放入 Map 作为 Value,也就是新创建一个 LongAdder 对象,最后返回 Value。
由于 computeIfAbsent 方法返回的 Value 是 LongAdder,是一个线程安全的累加器,因此可以直接调用其 increment 方法进行累加。
欢迎关注微信公众号:互联网全栈架构,收取更多有价值的信息。