
ClickHouse 案例 | ClickHouse 连接 ZK 频繁超时处理案例
共 3180字,需浏览 7分钟
·
2022-02-15 18:20
1、背景:
我们线上有一套clickhouse集群,5分片2副本总计10个实例,每个实例独占1台物理机,配套混布一个3节点zookeeper集群。
软件版本:centos 7.5 + CK 19.7.3 + ZK 3.4.13
从昨天开始应用写入日志开始堆积,并不断的报错zookeeper session timeout。
登录机器查看clickhouse的errlog,大量的timeout信息:
2021.09.29 05:48:19.940814 [ 32 ] {} app.log_dev_local (ReplicatedMergeTreeRestartingThread): ZooKeeper session has expired. Switching to a new session.
2021.09.29 05:48:19.949000 [ 25 ] {} app.log_k8s_local (ReplicatedMergeTreeRestartingThread): ZooKeeper session has expired. Switching to a new session.
2021.09.29 05:48:19.952341 [ 30 ] {} app.log_dev_local (ReplicatedMergeTreeRestartingThread): void DB::ReplicatedMergeTreeRestartingThread::run(): Code: 999, e.displayText() = Coordination::Exception: All con
nection tries failed while connecting to ZooKeeper. Addresses: 10.1.1.1:2181, 10.1.1.1.2:2181, 10.1.1.3:2181
2、诊断
查看zookeeper状态,3个实例都执行
echo stat|nc 127.0.0.1 2181
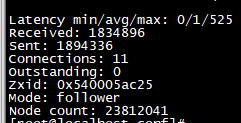
返回1个leader 2个follower,集群状态是正常的,但是该命令执行很慢。
尝试登录zk实例
sh /usr/lib/zookeeper/bin/zkCli.sh -server 127.0.0.1:2181
进入登录界面后执行 ls /卡顿半天,然后返回timeout。应该是ZK集群通信出了问题,先对其进行滚动重启,重启后问题依然存在。
尝试调优zk参数,当前参数为
tickTime= 2000
syncLimit = 10
minSessionTimeout = 4000
maxSessionTimeout = 120000
forceSync=yes
leaderServes = yes
调整成
tickTime= 2000
syncLimit = 100
minSessionTimeout = 40000
maxSessionTimeout = 600000
forceSync= no
leaderServes = no
重启集群后问题依然存在。
我们线上有4套CK集群,每套都独占一套zk,其余3套集群的zookeeper的内存只有几十K,Node count只有几万,而出问题的这套Node count有2千多万,zookeeper进程内存30G左右。
现在怀疑是Node count过多,导致节点通信拥堵,于是想办法降低Node数量:
该环境有一套kafka混用了ZK集群,为其搭建了一套专属ZK集群并将ZK元数据目录删除,node count和物理内存依然很高,问题没有解决。 清理无用表,找出600多个表,执行drop后,node count和物理内存依然很高,问题没有解决。降低Node count的尝试失败。
排查到现在,基本能想到的招数都已用到,再整理一下思路:
ZK节点响应很慢,但是集群状态是正常的; CK的insert经常超时,但是偶尔能执行成功; 增大ZK的超时参数,没有丝毫改善 ZK的node count非常多,当前的3个ZK实例占用内存很高(RSS一直在30G上下浮动)
zookeeper实例本质是1个java进程,有没有可能是达到内存上限频繁的触发full gc,进而导致ZK服务响应经常性卡顿?
搜索半天没有在机器上发现full gc的日志记录,只能直接验证一下猜想。
在/usr/lib/zookeeper/conf目录下新建1个文件java.env,内容如下:
export JVMFLAGS="-Xms16384m -Xmx32768m $JVMFLAGS"
滚动重启ZK集群,启动完毕后问题依然存在,但是ZK实例的RSS从原来的30G上升到了33G,超出了Xmx上限。
应该是没吃饱,修改一下文件参数
export JVMFLAGS="-Xms16384m -Xmx65536m $JVMFLAGS"
再次重启ZK集群,ZK实例的RSS飙升到55G左右就不再上升,困扰多时的问题也自动消失了,看来刚刚的full gc猜想是正确的。
既然已经证明是JVM heap内存的问题,那么刚刚调整的ZK参数就全部回滚,然后滚动重启ZK集群。
3、溯源
系统自此稳定了,但是zk进程占用的物理内存越来越大,没几天就达到了64G,照这个消耗速度,256G内存被耗光是迟早的事情。
为什么这套zk的node count会这么多,zk进程的RSS这么大?
登录zk,随意翻找一个表的副本目录,发现parts目录居然有8000多个znode,
登录到ck实例,执行
use system
select substring(name,1,6),count(*) from zookeeper where path='/clickhouse/tables/01-01/db/table/replicas/ch1/parts' group by substring(name,1,6) order by substring(name,1,6);
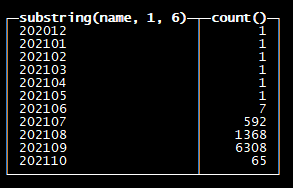
该表自从7月后znode part数量就一路飙升,在9月末达到最高值。
尝试执行optimize table table final,对降低part没什么用。
经和开发沟通后获悉,在7月的时候部分表的insert从每10s执行1次改成了1s执行1次,对应的就是part数量的飙升。
将这些表的insert统统改回了每10s执行1次,截止目前(10月28号),10月份的part基本回落到了一个正常值。
至于如何清理已有的znode,目前有2种方法:
将部分离线表导出后drop,然后再导入,操作后znode从2400w下降到了1700w 大部分表的数据都有生命周期,N个月后将不再需要的历史分区直接drop
至少目前可以确信znode不会再暴涨,zk进程的内存也不会继续增加,可以保证clickhouse集群稳定的运行下去。
4、小结
这次案例前后耗费了2天的时间才得以定位原因并解决,又耗费了更长的时间才找到问题根源,距离发稿截止日期已经过了整整1个月,期间没有再复发过。
java进程对Xms和Xmx设置很敏感,线上应用要密切关注其内存占用情况。
作者简介: 任坤,现居珠海,先后担任专职 Oracle 和 MySQL DBA,现在主要负责 MySQL、mongoDB、Redis 和 Clickhouse 维护工作。