
2021年9月字节跳动商业广告,算法岗面试题分享!
文 | 七月在线
编 | 小七


目录
FIGHTING
问题1:SVM相关,怎么理解SVM,对偶问题怎么来的,核函数是怎么回事。
问题2:集成学习的方式,随机森林讲一下,boost讲一下,XGBOOST是怎么回事讲一下。
问题3:决策树是什么东西,选择叶子节点的评价指标都有什么。对于连续值,怎么选择分割点。
问题4:模型评价指标都有什么,AUC是什么,代表什么东西。
问题5:关于样本不平衡都有什么方法处理
问题1:SVM相关,怎么理解SVM,对偶问题怎么来的,核函数是怎么回事。
SVM是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机。
SVM为什么要将原始问题转换为对偶问题来求解,原因如下:
对偶问题将原始问题中的约束转为了对偶问题中的等式约束;
方便核函数的引入;
改变了问题的复杂度。由求特征向量w转化为求比例系数a,在原始问题下,求解的复杂度与样本的维度有关,即w的维度。在对偶问题下,只与样本数量有关。
核函数的使用实际上是增加维度,把原本在低维度里的样本,映射到更高的维度里,将本来不可以线性分类的点,变成可以线性分类的。
问题2:集成学习的方式,随机森林讲一下,boost讲一下,XGBOOST是怎么回事讲一下。
集成学习的方式主要有bagging,boosting,stacking等,随机森林主要是采用了bagging的思想,通过自助法(bootstrap)重采样技术,从原始训练样本集N中有放回地重复随机抽取n个样本生成新的训练样本集合训练决策树,然后按以上步骤生成m棵决策树组成随机森林,新数据的分类结果按分类树投票多少形成的分数而定。
boosting是分步学习每个弱分类器,最终的强分类器由分步产生的分类器组合而成,根据每步学习到的分类器去改变各个样本的权重(被错分的样本权重加大,反之减小)
它是一种基于boosting增强策略的加法模型,训练的时候采用前向分布算法进行贪婪的学习,每次迭代都学习一棵CART树来拟合之前 t-1 棵树的预测结果与训练样本真实值的残差。
XGBoost对GBDT进行了一系列优化,比如损失函数进行了二阶泰勒展开、目标函数加入正则项、支持并行和默认缺失值处理等,在可扩展性和训练速度上有了巨大的提升,但其核心思想没有大的变化。
问题3:决策树是什么东西,选择叶子节点的评价指标都有什么。对于连续值,怎么选择分割点。
决策树有三种:分别为ID3,C4.5,Cart树
ID3损失函数︰
C4.5损失函数:
Cart树损失函数:
对于连续值往往通过随机取值、给定采样间隔或者根据样本的值这三种方法的其中一个选择分割点,据称,使用随机取值的办法最终得到的决策树(随机森林)最优。
问题4:模型评价指标都有什么,AUC是什么,代表什么东西。
准确率:分类正确的样本占总样本的比例
准确率的缺陷:当正负样本不平衡比例时,当不同类别的样本比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。
精确率:分类正确的正样本个数占分类器预测为正样本的样本个数的比例;
召回率:分类正确的正样本个数占实际的正样本个数的比例。
F1 score:是精确率和召回率的调和平均数,综合反应模型分类的性能。
Precision值和Recall值是既矛盾又统一的两个指标,为了提高Precision值,分类器需要尽量在“更有把握”时才把样本预测为正样本,但此时往往会因为过于保 守而漏掉很多“没有把握”的正样本,导致Recall值降低。
AUC是ROC曲线下面的面积,AUC可以解读为从所有正例中随机选取一个样本A,再从所有负例中随机选取一个样本B,分类器将A判为正例的概率比将B判为正例的概率大的可能性。AUC反映的是分类器对样本的排序能力。AUC越大,自然排序能力越好,即分类器将越多的正例排在负例之前。
问题5:关于样本不平衡都有什么方法处理
常用于解决数据不平衡的方法:
欠采样:从样本较多的类中再抽取,仅保留这些样本点的一部分;
过采样:复制少数类中的一些点,以增加其基数;
生成合成数据:从少数类创建新的合成点,以增加其基数。
添加额外特征:除了重采样外,我们还可以在数据集中添加一个或多个其他特征,使数据集更加丰富,这样我们可能获得更好的准确率结果。

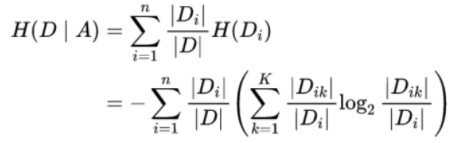
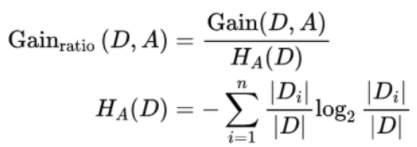
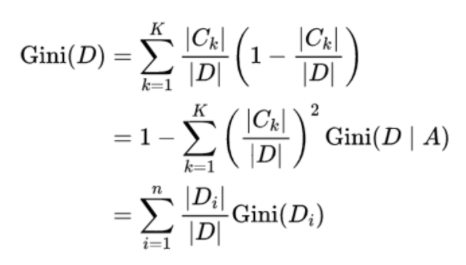
— 推荐阅读 — NLP ( 自然语言处理 )

CV(计算机视觉)
推荐
最新大厂面试题
AI开源项目论文