
支付宝 SOFATracer 原理与实践
架构之美
共 5191字,需浏览 11分钟
·
2021-08-13 23:09

- 背景 -
图片来源:
https://www.splunk.com/en_us/data-insider/what-is-distributed-tracing.html#benefits-of-distributed-tracing
故障定位难,一次请求往往需要涉及到多个服务,排查问题甚至需要拉上多个团队; 完整调用链路梳理难,节点调用关系分析; 性能分析难,确认性能短板节点。
Log; Trace; Metrics 。
- OpenTracing -
TraceId and SpanId; 操作名称; 耗时; 服务调用结果。
ChildOf,同步服务调用,客户端需要服务端的结果返回才能进行后续处理; FollowsFrom,异步服务调用,客户端不等待服务端结果。
- SOFATracer -
0ad1348f1403169275002100356696
traceIdStr.append(ip).append(System.currentTimeMillis()).append(getNextId()).append(getPID());
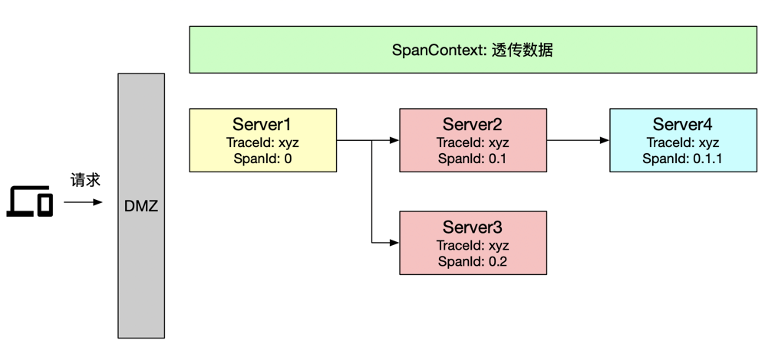
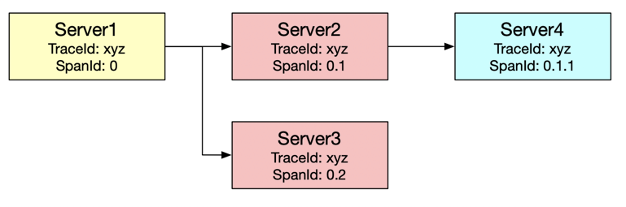
点代表调用深度; 数字代表调用顺序; SpanId 由客户端创建。
Trace 数据的生成、传递和上报; Trace 上下文的解析和注入。
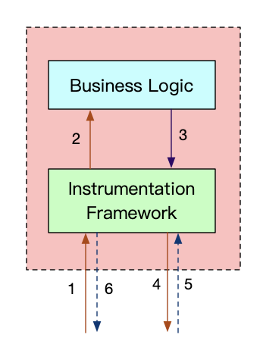
Server Received (SR), 创建一个新的父 Span 或者从上下文中提取; 调用业务代码; 业务代码再次发起远程服务调用; Client Send (CS) 创建一个子 Span,传递 TraceId、SpanId 和透传数据; Client Received (CR), 结束当前子 Span,记录/上报 Span; Server Send (SS) 结束父 Span,记录/上报 Span。
Filter,请求过滤器 (Dubbo, SOFARPC, Spring MVC);
AOP 切面 (DataSource, Redis, MongoDB);
a.Proxy
b.ByteCode generating
Hook 机制 (Spring Message, RocketMQ)。

client-digest:调用 Span; server-digest:被调用 Span; client-stat:一分钟内调用 Span 的数据聚合; server-stat:一分钟内被调用 Span 的数据聚合。
- APM -
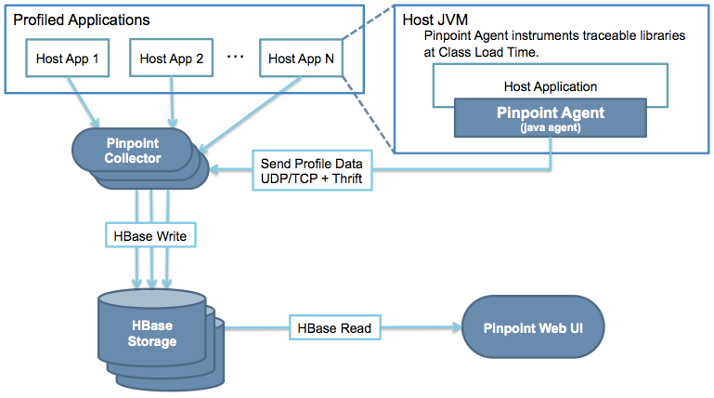
图片来源:
https://pinpoint-apm.github.io/pinpoint/overview.html
有向无环图的图形化展示; 按照 TraceId 查询; 按照调用者查询; 按照被调用者查询; 按照 IP 查询。
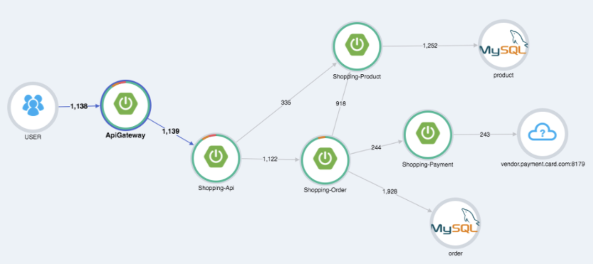
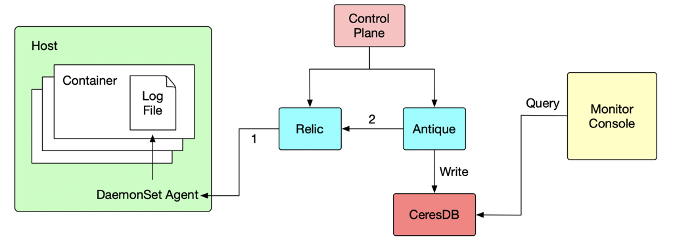
存储 & 分析,丰富的终端特性; 全链路压测; 性能剖析; 监控 & 报警:CPU、内存和 JVM 信息等。

- 展望 -
- 相关资料 -
SOFATracer 快速开始: https://www.sofastack.tech/projects/sofa-tracer/component-access/ SOFATracer Github 项目: https://github.com/sofastack/sofa-tracer OpenTracing: https://opentracing.io/ OpenTelemetry: https://opentelemetry.io/

评论