前所未有:用AI控制核聚变,DeepMind再登Nature

大数据文摘转载自数据实战派
毫无疑问,DeepMind 正在加速将其 AI 算法应用于最前沿的科学问题上。
继此前振奋业界的蛋白质预测成果之后,今日,DeepMind 又一个硬核研究亮相,在这篇名为 Magnetic control of tokamak plasmas through deep reinforcement learning的nature 文章,DeepMind 的科学家和来自 Swiss Plasma Center - EPFL 的研究者,共同提出了一种强化学习算法,来控制托卡马克核聚变反应堆内的等离子体。
这一进展将可以帮助物理学家更好地了解聚变的工作原理,并有希望加速这种“终极能源”的到来。
“在现实世界系统中最具挑战性的应用之一”
太阳源源不断的能量来自于原子核的聚合反应,即核聚变。因此,可控核聚变技术的实验装置,常被称作“人造太阳”。
但一直以来,人们希望找到有效控制和限制等离子体的方法,只有这样这种“终极能源”才能为人类所利用。
具体到工程实现上,科学家们正在尝试借助托卡马克装置通过使用磁场限制等离子体。
在托卡马克装置中,磁场线圈会限制等离子体粒子,以使等离子体达到聚变所需的条件。如下图所示,一组磁线圈产生一个强烈的“环形”场,围绕环面进行引导。一个中央螺线管(承载电流的磁体)产生一个沿“极向”方向的第二个磁场,即围绕环面的路径。这两个场产生了一个扭曲的磁场,将粒子限制在等离子体中。此外,还会有第三组磁线圈产生一个外极向场,用于塑造和定位等离子体。
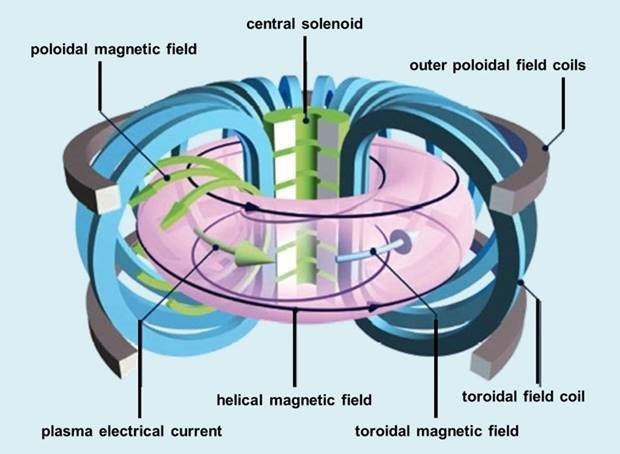
图丨环形场线圈(蓝色)、中央螺线管(绿色)和极向场线圈(灰色)。环面周围的磁场(黑色)限制了带电等离子体粒子的行进路径。(来源:EUROfusion)
其中一个困难之处在于,尽管这些控制器通常很有效,但每一次研究人员想要改变等离子体的配置,并尝试不同的形状以产生更多的能量或更清洁的等离子体时,都需要基于模型和仔细的模拟,进行大量的工程和设计工作,并平衡复杂的实时计算。
在 DeepMind 的这个方案中,通过使用强化学习(RL)生成非线性反馈控制器,一种全新的等离子体控制方法成为可能。DeepMind 的研究员 Martin Riedmiller 表示:“这是强化学习在现实世界系统中最具挑战性的应用之一”。
具体方案细节
他们开发了一个深度强化学习系统,来控制瑞士等离子体中心的可变配置托卡马克 内的 19 个电磁线圈,设计架构如下图所示: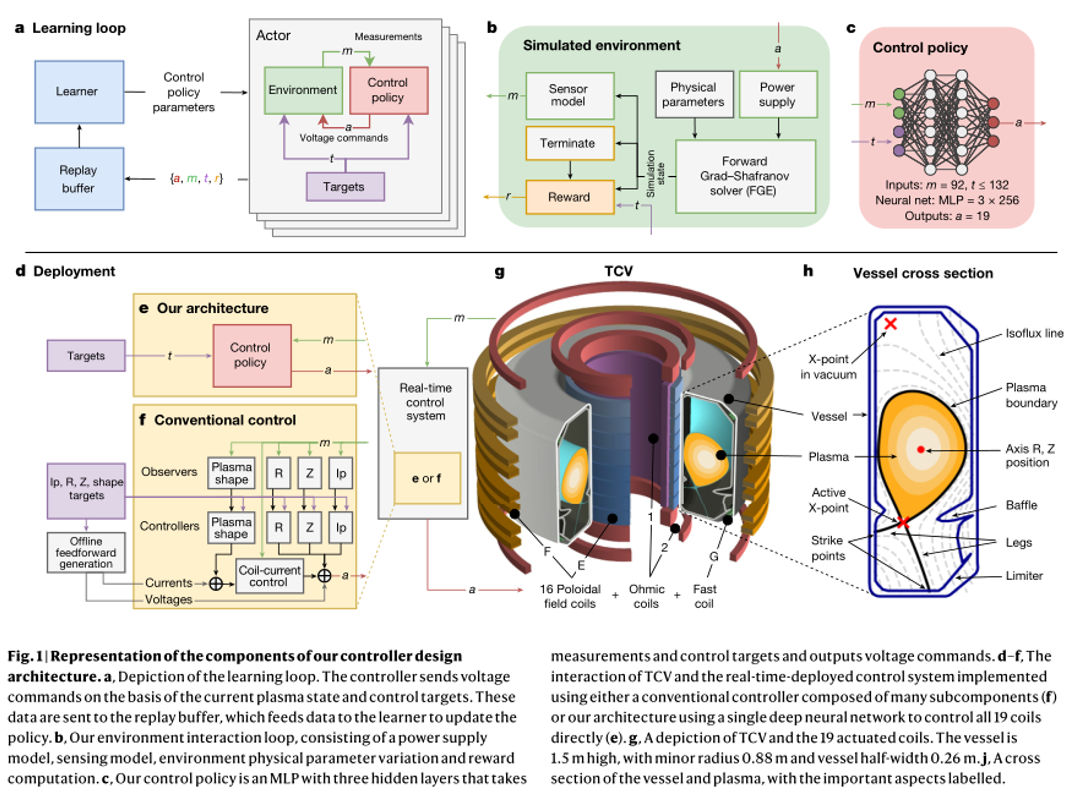
其包含以下三个主要阶段:首先,设计者指定实验目标,可能伴有时变控制目标。其次,深度 RL 算法与 tokamak 仿真器交互,寻找接近最优的控制策略以满足指定的目标。第三,控制策略以神经网络的形式直接在 tokamak 硬件上实时运行。
在第一阶段,实验目标由一组目标指定,这些目标可以包含各种各样的期望属性。这些属性范围从位置和等离子体电流的基本稳定到多个时变目标的复杂组合,包括具有指定延伸率、三角形和 X-点位置的精确形状轮廓。然后,将这些目标组合为一个“奖励函数”,在每个时间步中为状态分配标量质量度量。这个函数还惩罚达到不是所期望的终端状态的控制策略,如下所述。最重要的是,精心设计的奖励函数将被最小化,以给予学习算法最大的灵活性,进而达到预期的结果。
在第二个阶段,如图 1a,b 所示,高性能 RL 算法收集数据并通过与环境交互发现控制策略。
研究团队使用具有足够保真度的仿真器来描述等离子体形状和电流的演变,同时保持足够低的学习计算成本。
具体而言,团队采用了自由边界等离子体演化模型,以模拟极场线圈电压影响下等离子体状态演化的动力学过程。在该模型中,线圈和无源导体中的电流在电源外部施加的电压,以及其他导体和等离子体内部随时间变化的电流产生的感应电压的影响下发生变化。反过来,等离子体由 Grad-Shafranov(G-S)方程模拟。这组方程由 FGE 软件包进行数值求解。
RL 算法利用收集到的仿真器数据,针对指定的奖励函数找到一个接近最优的策略。
由于等离子体状态演化的计算要求,团队成员采用仿真器的数据速率明显低于典型的 RL 环境。因此,研究团队通过使用最大后验策略优化(MPO, maximum a posteriori policy optimization)算法,以克服数据缺乏的问题。MPO 支持跨分布式并行流的数据收集,并以数据高效的方式进行学习。
在第三阶段,将控制策略与相关的实验控制目标捆绑在一个可执行文件中,使用专为 10 khz 实时控制而设计的编译器,以最小化依赖并消除不必要的计算。
该可执行文件由 TCV 控制框架加载而来(图 1d)。每个实验都始于标准的等离子体形成过程,在此过程中,传统的控制器保持等离子体的位置和总电流。在称为“移交”(handover)的预定时间,控制切换到团队所采用的控制策略,然后启动 19 个 TCV 控制线圈,将等离子体形状和电流转换到期望目标。实验在训练后不进一步调整控制策略网络权重,换句话说,从仿真到硬件有“zero-shot”的转移。
控制策略通过学习过程的几个关键属性可靠地传递到 TCV,如图 1b 所示。研究团队确定了一种执行器和传感器模型,该模型包含了影响控制稳定性的特性,如延迟、测量噪声和控制电压偏移。团队成员通过分析实验数据,在训练过程中对等离子体压力、电流密度剖面和等离子体电阻率在适当的范围内应用了有针对性的参数变化,以解释变化的、不受控制的实验条件。
这在保证性能的同时,可以提供一定的健壮性。虽然仿真器通常是准确的,但在已知的一些区域性能表现欠佳。因此,团队在训练循环中建立了“学习区域回避”(learned-region avoidance),通过使用奖励和终止条件来避免这些问题,即当遇到特定条件时,立即停止模拟。
能力展示
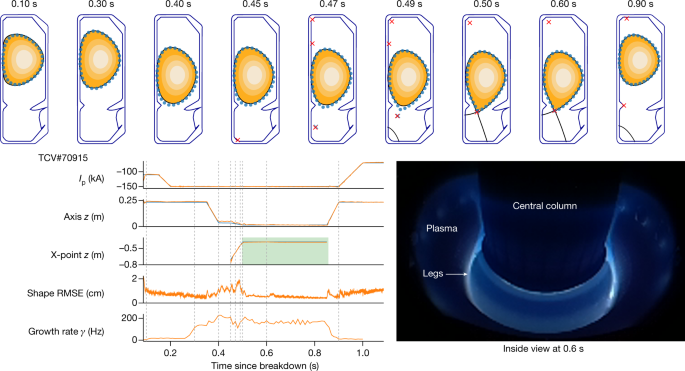
在论文的基础能力验证部分,团队首先展示了这一方案对等离子体平衡基本质量的精确控制。然后,通过复杂的、随时间变化的目标和物理相关的等离子体配置,系统对控制范围进行了广泛的平衡。最后,实验展示了对容器中具有多个等离子体“液滴”配置的同步控制。
另一个重要的能力——即为科学研究生成复杂配置的能力。每个演示都有自己的随时间变化的目标,但除此之外,使用相同的架构设置来生成控制策略,包括训练和环境配置,只需对奖励函数进行少量调整。
此外,RL 方法大大简化了控制系统。单个计算成本低的控制器取代了嵌套控制架构,消除了独立平衡重建的要求。这些综合优势,缩短了控制器开发周期,并能加速了更换等离子配置验证。
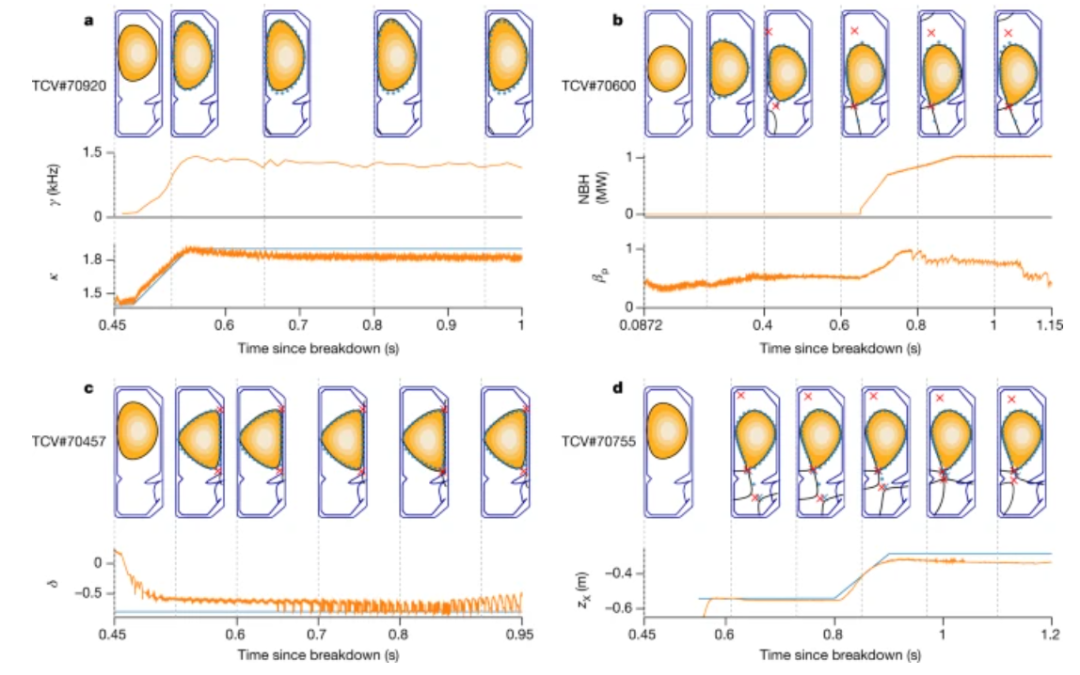
总而言之,研究人员认为,使用 AI 算法控制等离子体,将使在反应堆内进行不同条件的实验变得更加容易,帮助他们了解这个过程,并有可能加快商业核聚变的发展。AI 还学会了如何通过以人类以前从未尝试过的方式调整磁铁来控制等离子体,这表明可能会有新的反应堆配置可供探索。
正如瑞士等离子中心主任 Ambrogio Fasoli 所说:“我们可以通过这种控制系统来冒险,否则我们不敢冒险。” 人类操作员通常不愿意将等离子体推到一定限度之外。
有些事件我们必须避免,因为它们会损坏设备,如果我们确定有一个控制系统可以接近极限但不会超出极限,那么就可以探索更多的可能性。研究可以继续加速。”
参考:
https://www.nature.com/articles/s41586-021-04301-9#Sec4