
【Python基础】如何编写简洁美观的Python代码
编译 | VK
来源 | Analytics Vidhya
概述
Python风格教程将使你能够编写整洁漂亮的Python代码
在这个风格教程中学习不同的Python约定和Python编程的其他细微差别
介绍
你有没有遇到过一段写得很糟糕的Python代码?我知道你们很多人都会点头的。
编写代码是数据科学家或分析师角色的一部分。另一方面,编写漂亮整洁的Python代码完全是另一回事。作为一个精通分析或数据科学领域(甚至软件开发)的程序员,这很可能会改变你的形象。
那么,我们如何编写这种所谓漂亮的Python代码呢?
欢迎学习Python风格教程

数据科学和分析领域的许多人来自非编程背景。我们先从学习编程的基础知识开始,接着理解机器学习背后的理论,然后开始征服数据集。
在这个过程中,我们经常不练习核心编程,也不注意编程惯例。
这就是本Python风格教程将要解决的问题。我们将回顾PEP-8文档中描述的Python编程约定,你将成为一个更好的程序员!
目录
为什么这个Python风格的教程对数据科学很重要?
什么是PEP8?
了解Python命名约定
Python风格教程的代码布局
熟悉正确的Python注释
Python代码中的空格
Python的一般编程建议
自动格式化Python代码
为什么这个Python风格的教程对数据科学很重要
有几个原因使格式化成为编程的一个重要方面,尤其是对于数据科学项目:
可读性
好的代码格式将不可避免地提高代码的可读性。这不仅会使你的代码更有条理,而且会使读者更容易理解程序中正在发生的事情。如果你的程序运行了数千行,这将特别有用。
你会有很多的数据帧、列表、函数、绘图等,如果不遵循正确的格式准则,你甚至会很容易失去对自己代码的跟踪!
协作
如果你在一个团队项目上合作,大多数数据科学家都会这样做,那么好的格式化就成了一项必不可少的任务。
这样可以确保代码被正确理解而不产生任何麻烦。此外,遵循一个通用的格式模式可以在整个项目生命周期中保持程序的一致性。
Bug修复
当你需要修复程序中的错误时,拥有一个格式良好的代码也将有助于你。错误的缩进、不恰当的命名等都很容易使调试成为一场噩梦!
因此,最好是以正确的编写风格来开始编写你的程序!
考虑到这一点,让我们快速概述一下本文将介绍的PEP-8样式教程!
什么是PEP-8
PEP-8或Python增强建议是Python编程的风格教程。它是由吉多·范罗森、巴里·华沙和尼克·科格兰写的。它描述了编写漂亮且可读的Python代码的规则。
遵循PEP-8的编码风格将确保Python代码的一致性,从而使其他读者、贡献者或你自己更容易理解代码。
本文介绍了PEP-8指导原则中最重要的方面,如如何命名Python对象、如何构造代码、何时包含注释和空格,最后是一些很重要但很容易被大多数Python程序员忽略的一般编程建议。
让我们学习编写更好的代码!
官方PEP-8文档可以在这里找到。
https://www.python.org/dev/peps/pep-0008/
了解Python命名约定
莎士比亚有句名言:“名字里有什么?”. 如果他当时遇到了一个程序员,他会很快得到一个答复——“很多!”.
是的,当你编写一段代码时,你为变量、函数等选择的名称对代码的可理解性有很大的影响。看看下面的代码:
# 函数 1
def func(x):
a = x.split()[0]
b = x.split()[1]
return a, b
print(func('Analytics Vidhya'))
# 函数 2
def name_split(full_name):
first_name = full_name.split()[0]
last_name = full_name.split()[1]
return first_name, last_name
print(name_split('Analytics Vidhya'))
# 输出
('Analytics', 'Vidhya')
('Analytics', 'Vidhya')
这两个函数的作用是一样的,但是后者提供了一个更好的直觉让我们知道发生了什么,即使没有任何注释!
这就是为什么选择正确的名称和遵循正确的命名约定可以在编写程序时可以产生巨大的不同。话虽如此,让我们看看如何在Python中命名对象!
开头命名
这些技巧可以应用于命名任何实体,并且应该严格遵守。
遵循相同的模式
thisVariable, ThatVariable, some_other_variable, BIG_NO
避免使用长名字,同时也不要太节俭的名字
this_could_be_a_bad_name = “Avoid this!”
t = “This isn\’t good either”
使用合理和描述性的名称。这将有助于以后你记住代码的用途
X = “My Name” # 防止这个
full_name = “My Name” # 这个更好
避免使用以数字开头的名字
1_name = “This is bad!”
避免使用特殊字符,如@、!、#、$等
phone_ # 不好
变量命名
变量名应始终为小写
blog = "Analytics Vidhya"
对于较长的变量名,请使用下划线分隔单词。这提高了可读性
awesome_blog = "Analytics Vidhya"
尽量不要使用单字符变量名,如“I”(大写I字母)、“O”(大写O字母)、“l”(小写字母l)。它们与数字1和0无法区分。看看:
O = 0 + l + I + 1
全局变量的命名遵循相同的约定
函数命名
遵循小写和下划线命名约定
使用富有表现力的名字
# 避免
def con():
...
# 这个更好
def connect():
...
如果函数参数名与关键字冲突,请使用尾随下划线而不是缩写。例如,将break转换为break_u而不是brk
# 避免名称冲突
def break_time(break_):
print(“Your break time is”, break_,”long”)
类名命名
遵循CapWord(或camelCase或StudlyCaps)命名约定。每个单词以大写字母开头,单词之间不要加下划线
# 遵循CapWord
class MySampleClass:
pass
如果类包含具有相同属性名的子类,请考虑向类属性添加双下划线
这将确保类Person中的属性__age被访问为 _Person__age。这是Python的名称混乱,它确保没有名称冲突
class Person:
def __init__(self):
self.__age = 18
obj = Person()
obj.__age # 错误
obj._Person__age # 正确
对异常类使用后缀“Error”
class CustomError(Exception):
“””自定义异常类“””
类方法命名
实例方法(不附加字符串的基本类方法)的第一个参数应始终为self。它指向调用对象
类方法的第一个参数应始终为cls。这指向类,而不是对象实例
class SampleClass:
def instance_method(self, del_):
print(“Instance method”)
@classmethod
def class_method(cls):
print(“Class method”)
包和模块命名
尽量使名字简短明了
应遵循小写命名约定
对于长模块名称,首选下划线
避免包名称使用下划线
testpackage # 包名称
sample_module.py # 模块名称
常量命名
常量通常在模块中声明和赋值
常量名称应全部为大写字母
对较长的名称使用下划线
# 下列常量变量在global.py模块
PI = 3.14
GRAVITY = 9.8
SPEED_OF_Light = 3*10**8
Python风格教程的代码布局
现在你已经知道了如何在Python中命名实体,下一个问题应该是如何用Python构造代码!
老实说,这是非常重要的,因为如果没有适当的结构,你的代码可能会出问题,对任何评审人员来说都是最大的障碍。
所以,不用再多费吹灰之力,让我们来了解一下Python中代码布局的基础知识吧!
缩进
它是代码布局中最重要的一个方面,在Python中起着至关重要的作用。缩进告诉代码块中要包含哪些代码行以供执行。缺少缩进可能是一个严重的错误。
缩进确定代码语句属于哪个代码块。想象一下,尝试编写一个嵌套的for循环代码。在各自的循环之外编写一行代码可能不会给你带来语法错误,但你最终肯定会遇到一个逻辑错误,这可能会在调试方面耗费时间。
遵循下面提到的缩进风格,以获得一致的Python脚本风格。
始终遵循4空格缩进规则
# 示例
if value<0:
print(“negative value”)
# 另一个例子
for i in range(5):
print(“Follow this rule religiously!”)
建议用空格代替制表符
建议用空格代替制表符。但是当代码已经用制表符缩进时,可以使用制表符。
if True:
print('4 spaces of indentation used!')
将大型表达式拆分成几行
处理这种情况有几种方法。一种方法是将后续语句与起始分隔符对齐。
# 与起始分隔符对齐。
def name_split(first_name,
middle_name,
last_name)
# 另一个例子。
ans = solution(value_one, value_two,
value_three, value_four)
第二种方法是使用4个空格的缩进规则。这将需要额外的缩进级别来区分参数和块内其他代码。
# 利用额外的缩进。
def name_split(
first_name,
middle_name,
last_name):
print(first_name, middle_name, last_name)
最后,你甚至可以使用“悬挂缩进”。悬挂缩进在Python上下文中是指包含圆括号的行以开括号结束的文本样式,后面的行缩进,直到括号结束。
# 悬挂缩进
ans = solution(
value_one, value_two,
value_three, value_four)
缩进if语句可能是一个问题
带有多个条件的if语句自然包含4个空格。如你所见,这可能是个问题。随后的行也将缩进,并且无法区分if语句和它执行的代码块。现在,我们该怎么办?
好吧,我们有几种方法可以绕过它:
# 这是个问题。
if (condition_one and
condition_two):
print(“Implement this”)
一种方法是使用额外的缩进!
# 使用额外的缩进
if (condition_one and
condition_two):
print(“Implement this”)
另一种方法是在if语句条件和代码块之间添加注释,以区分这两者:
# 添加注释。
if (condition_one and
condition_two):
# 此条件有效
print(“Implement this”)
括号的闭合
假设你有一个很长的字典。你将所有的键值对放在单独的行中,但是你将右括号放在哪里?是在最后一行吗?还是跟在最后一个键值对?如果放在最后一行,右括号位置的缩进是多少?
也有几种方法可以解决这个问题。
一种方法是将右括号与前一行的第一个非空格字符对齐。
#
learning_path = {
‘Step 1’ : ’Learn programming’,
‘Step 2’ : ‘Learn machine learning’,
‘Step 3’ : ‘Crack on the hackathons’
}
第二种方法是把它作为新行的第一个字符。
learning_path = {
‘Step 1’ : ’Learn programming’,
‘Step 2’ : ‘Learn machine learning’,
‘Step 3’ : ‘Crack on the hackathons’
}
在二元运算符前换行
如果你试图在一行中放入太多的运算符和操作数,这肯定会很麻烦。相反,为了更好的可读性,把它分成几行。
现在很明显的问题是——在操作符之前还是之后中断?惯例是在操作符之前断行。这有助于识别操作符和它所作用的操作数。
# 在操作符之前断行
gdp = (consumption
+ government_spending
+ investment
+ net_exports
)
使用空行
将代码行聚在一起只会使读者更难理解你的代码。使代码看起来更整洁、更美观的一个好方法是在代码中引入相应数量的空行。
顶层函数和类应该用两个空行隔开
#分离类和顶层函数
class SampleClass():
pass
def sample_function():
print("Top level function")
类中的方法应该用一个空格行分隔
# 在类中分离方法
class MyClass():
def method_one(self):
print("First method")
def method_two(self):
print("Second method")
尽量不要在具有相关逻辑和函数的代码段之间包含空行
def remove_stopwords(text):
stop_words = stopwords.words("english")
tokens = word_tokenize(text)
clean_text = [word for word in tokens if word not in stop_words]
return clean_text
可以在函数中少用空行来分隔逻辑部分。这使得代码更容易理解
def remove_stopwords(text):
stop_words = stopwords.words("english")
tokens = word_tokenize(text)
clean_text = [word for word in tokens if word not in stop_words]
clean_text = ' '.join(clean_text)
clean_text = clean_text.lower()
return clean_text
行最大长度
一行不超过79个字符
当你用Python编写代码时,不能在一行中压缩超过79个字符。这是限制,应该是保持声明简短的指导原则。
你可以将语句拆分为多行,并将它们转换为较短的代码行
# 分成多行
num_list = [y for y in range(100)
if y % 2 == 0
if y % 5 == 0]
print(num_list)
导入包
许多数据科学家之所以喜欢使用Python,部分原因是因为有太多的库使得处理数据更加容易。因此,我们假设你最终将导入一堆库和模块来完成数据科学中的任何任务。
应该始终位于Python脚本的顶部
应在单独的行上导入单独的库
import numpy as np
import pandas as pd
df = pd.read_csv(r'/sample.csv')
导入应按以下顺序分组:
标准库导入 相关第三方进口 本地应用程序/库特定导入 在每组导入后包括一个空行
import numpy as np
import pandas as pd
import matplotlib
from glob import glob
import spaCy
import mypackage
可以在一行中从同一模块导入多个类
from math import ceil, floor
熟悉正确的Python注释
理解一段未注释的代码可能是一项费力的工作。即使是代码的原始编写者,也很难记住一段时间后代码行中到底发生了什么。
因此,最好及时对代码进行注释,这样读者就可以正确地理解你试图用这段代码实现什么。
一般提示
注释总是以大写字母开头
注释应该是完整的句子
更新代码时更新注释
避免写显而易见之事的注释
注释的风格
描述它们后面的代码段
与代码段有相同的缩进
从一个空格开始
# 从用户输入字符串中删除非字母数字字符。
import re
raw_text = input(‘Enter string:‘)
text = re.sub(r'\W+', ' ', raw_text)
内联注释
这些注释与代码语句位于同一行
应与代码语句至少分隔两个空格
以通常的#开头,然后是空格
不要用它们来陈述显而易见的事情
尽量少用它们,因为它们会分散注意力
info_dict = {} # 字典,用于存储提取的信息
文档字符串
用于描述公共模块、类、函数和方法
也称为“docstrings”
它们之所以能在其他注释中脱颖而出,是因为它们是用三重引号括起来的
如果docstring以单行结尾,则在同一行中包含结束符“””
如果docstring分为多行,请在新行中加上结束符“””
def square_num(x):
"""返回一个数的平方."""
return x**2
def power(x, y):
"""多行注释。
返回x**y.
"""
return x**y
Python代码中的空格
在编写漂亮的代码时,空格常常被忽略为一个微不足道的方面。但是正确使用空格可以大大提高代码的可读性。它们有助于防止代码语句和表达式过于拥挤。这不可避免地帮助读者轻松地浏览代码。
关键
避免将空格立即放在括号内
# 正确的方法
df[‘clean_text’] = df[‘text’].apply(preprocess)
不要在逗号、分号或冒号前加空格
# 正确
name_split = lambda x: x.split()
字符和左括号之间不要包含空格
# 正确
print(‘This is the right way’)
# 正确
for i in range(5):
name_dict[i] = input_list[i]
使用多个运算符时,只在优先级最低的运算符周围包含空格
# 正确
ans = x**2 + b*x + c
在分片中,冒号充当二进制运算符
它们应该被视为优先级最低的运算符。每个冒号周围必须包含相等的空格
# 正确
df_valid = df_train[lower_bound+5 : upper_bound-5]
应避免尾随空格
函数参数默认值不要在=号周围有空格
def exp(base, power=2):
return base**power
请始终在以下二进制运算符的两边用单个空格括起来: 赋值运算符(=,+=,-=,等) 比较(=,<,>!=,<>,<=,>=,输入,不在,是,不是) 布尔值(and,or,not)
# 正确
brooklyn = [‘Amy’, ‘Terry’, ‘Gina’, 'Jake']
count = 0
for name in brooklyn:
if name == ‘Jake’:
print(‘Cool’)
count += 1
Python的一般编程建议
通常,有很多方法来编写一段代码。当它们完成相同的任务时,最好使用推荐的编写方法并保持一致性。我在这一节已经介绍了其中的一些。
与“None”之类的进行比较时,请始终使用“is”或“is not”。不要使用相等运算符
# 错误
if name != None:
print("Not null")
# 正确
if name is not None:
print("Not null")
不要使用比较运算符将布尔值与TRUE或FALSE进行比较。虽然使用比较运算符可能很直观,但没有必要使用它。只需编写布尔表达式
# 正确
if valid:
print("Correct")
# 错误
if valid == True:
print("Wrong")
与其将lambda函数绑定到标识符,不如使用泛型函数。因为将lambda函数分配给标识符违背了它的目的。回溯也会更容易
# 选择这个
def func(x):
return None
# 而不是这个
func = lambda x: x**2
捕获异常时,请命名要捕获的异常。不要只使用一个光秃秃的例外。这将确保当你试图中断执行时,异常块不会通过键盘中断异常来掩盖其他异常
try:
x = 1/0
except ZeroDivisionError:
print('Cannot divide by zero')
与你的返回语句保持一致。也就是说,一个函数中的所有返回语句都应该返回一个表达式,或者它们都不应该返回表达式。另外,如果return语句不返回任何值,则返回None而不是什么都不返回
# 错误
def sample(x):
if x > 0:
return x+1
elif x == 0:
return
else:
return x-1
# 正确
def sample(x):
if x > 0:
return x+1
elif x == 0:
return None
else:
return x-1
如果要检查字符串中的前缀或后缀,请使用“.startswith()”和“.endswith()",而不是字符串切片。它们更干净,更不容易出错
# 正确
if name.endswith('and'):
print('Great!')
自动格式化Python代码
当你编写小的程序时,格式化不会成为一个问题。但是想象一下,对于一个运行成千行的复杂程序,必须遵循正确的格式规则!这绝对是一项艰巨的任务。而且,大多数时候,你甚至不记得所有的格式规则。
我们如何解决这个问题呢?好吧,我们可以用一些自动格式化程序来完成这项工作!
自动格式化程序是一个程序,它可以识别格式错误并将其修复到位。Black就是这样一种自动格式化程序,它可以自动将Python代码格式化为符合PEP8编码风格的代码,从而减轻你的负担。
BLACK:https://pypi.org/project/black/
通过在终端中键入以下命令,可以使用pip轻松安装它:
pip install black
但是让我们看看black在现实世界中有多大的帮助。让我们用它来格式化以下类型错误的程序:
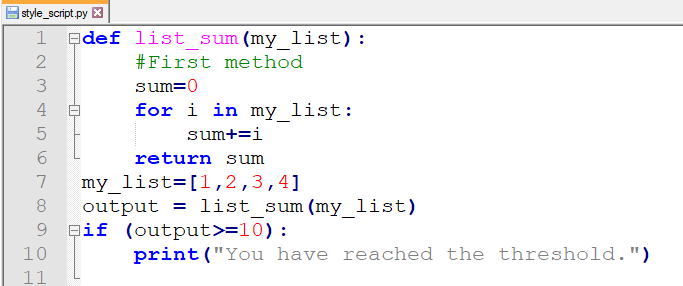
现在,我们要做的就是,前往终端并键入以下命令:
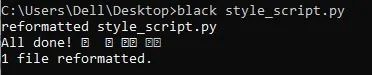
black style_script.py
完成后,black可能已经完成了更改,你将收到以下消息:
一旦再次尝试打开程序,这些更改将反映在程序中:
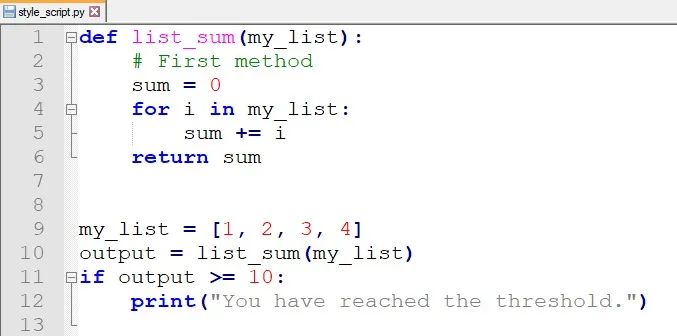
正如你所看到的,它已经正确地格式化了代码,在你不小心违反格式化规则的情况下它会有帮助。
Black还可以与Atom、Sublime Text、visualstudio代码,甚至Jupyter Notebook集成在一起!这无疑是一个你永远不会错过的插件。
除了black,还有其他的自动格式化程序,如autoep8和yapf,你也可以尝试一下!
结尾
我们已经在Python风格教程中讨论了很多关键点。如果你在代码中始终遵循这些原则,那么你将最终得到一个更干净和可读的代码。
另外,当你作为一个团队在一个项目中工作时,遵循一个共同的标准是有益的。它使其他合作者更容易理解。开始在Python代码中加入这些风格技巧吧!
原文链接:https://www.analyticsvidhya.com/blog/2020/07/python-style-guide/
看到这里,说明你喜欢这篇文章,请点击「在看」或顺手「转发」「点赞」。
往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/662nyZF
本站qq群1003271085。
加入微信群请扫码进群: