
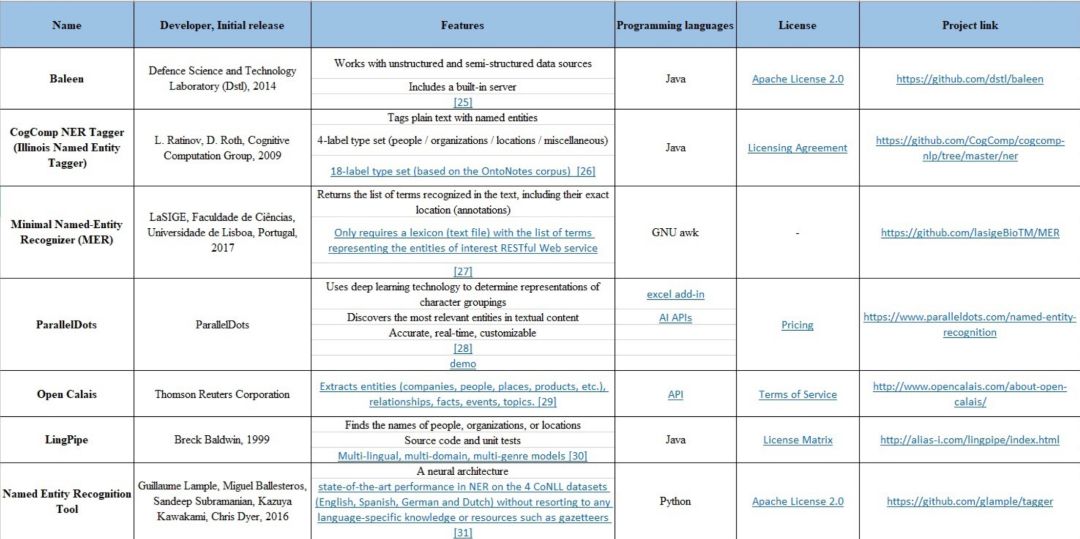
Python文本预处理:步骤、使用工具及示例
本文将讨论文本预处理的基本步骤,旨在将文本信息从人类语言转换为机器可读格式以便用于后续处理。此外,本文还将进一步讨论文本预处理过程所需要的工具。当拿到一个文本后,首先从文本正则化(text normalization) 处理开始。常见的文本正则化步骤包括:
将文本中出现的所有字母转换为小写或大写
将文本中的数字转换为单词或删除这些数字
删除文本中出现的标点符号、重音符号以及其他变音符号
删除文本中的空白区域
扩展文本中出现的缩写
删除文本中出现的终止词、稀疏词和特定词
文本规范化(text canonicalization)
input_str = ”The 5 biggest countries by population in 2017 are China, India, United States, Indonesia, and Brazil.”input_str = input_str.lower()print(input_str)
the 5 biggest countries by population in 2017 are china, india, united states, indonesia, and brazil.import reinput_str = ’Box A contains 3 red and 5 white balls, while Box B contains 4 red and 2 blue balls.’result = re.sub(r’\d+’, ‘’, input_str)print(result)
Box A contains red and white balls, while Box B contains red and blue balls.import stringinput_str = “This &is [an] example? {of} string. with.? punctuation!!!!” # Sample stringresult = input_str.translate(string.maketrans(“”,””), string.punctuation)print(result)
This is an example of string with punctuationinput_str = “ \t a string example\t “input_str = input_str.strip()input_str
‘a string example’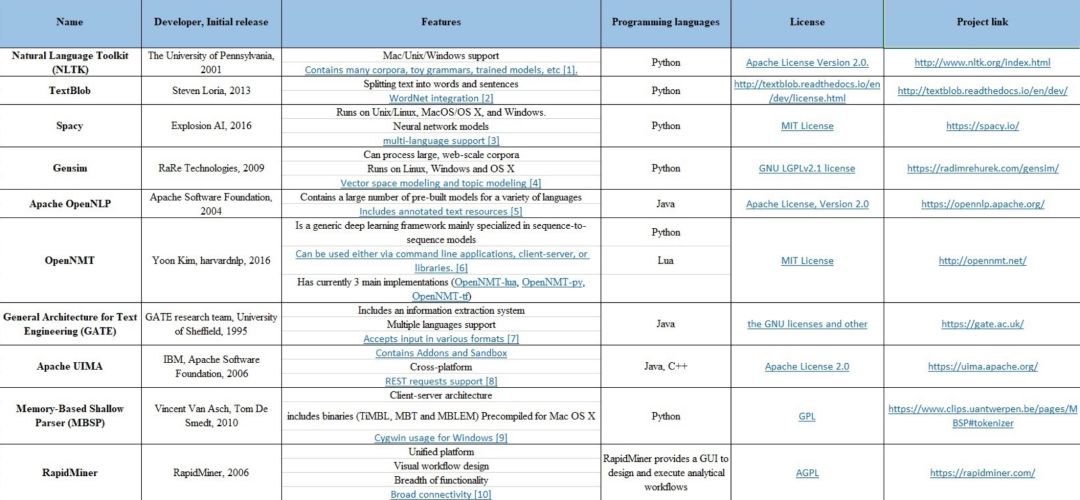
input_str = “NLTK is a leading platform for building Python programs to work with human language data.”stop_words = set(stopwords.words(‘english’))from nltk.tokenize import word_tokenizetokens = word_tokenize(input_str)result = [i for i in tokens if not i in stop_words]print (result)
[‘NLTK’, ‘leading’, ‘platform’, ‘building’, ‘Python’, ‘programs’, ‘work’, ‘human’, ‘language’, ‘data’, ‘.’]from sklearn.feature_extraction.stop_words import ENGLISH_STOP_WORDSfrom spacy.lang.en.stop_words import STOP_WORDS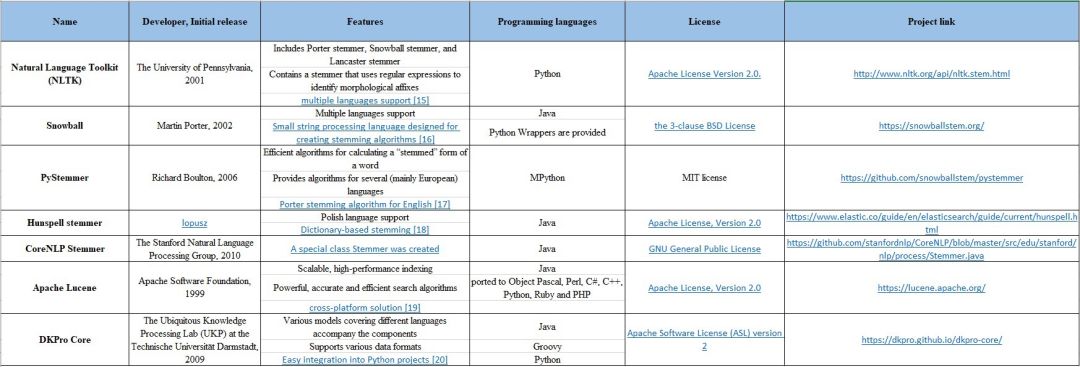
from nltk.stem import PorterStemmerfrom nltk.tokenize import word_tokenizestemmer= PorterStemmer()input_str=”There are several types of stemming algorithms.”input_str=word_tokenize(input_str)for word in input_str:print(stemmer.stem(word))
There are sever type of stem algorithm.from nltk.stem import WordNetLemmatizerfrom nltk.tokenize import word_tokenizelemmatizer=WordNetLemmatizer()input_str=”been had done languages cities mice”input_str=word_tokenize(input_str)for word in input_str:print(lemmatizer.lemmatize(word))
be have do language city mouseinput_str=”Parts of speech examples: an article, to write, interesting, easily, and, of”from textblob import TextBlobresult = TextBlob(input_str)print(result.tags)
[(‘Parts’, u’NNS’), (‘of’, u’IN’), (‘speech’, u’NN’), (‘examples’, u’NNS’), (‘an’, u’DT’), (‘article’, u’NN’), (‘to’, u’TO’), (‘write’, u’VB’), (‘interesting’, u’VBG’), (‘easily’, u’RB’), (‘and’, u’CC’), (‘of’, u’IN’)]input_str=”A black television and a white stove were bought for the new apartment of John.”from textblob import TextBlobresult = TextBlob(input_str)print(result.tags)
[(‘A’, u’DT’), (‘black’, u’JJ’), (‘television’, u’NN’), (‘and’, u’CC’), (‘a’, u’DT’), (‘white’, u’JJ’), (‘stove’, u’NN’), (‘were’, u’VBD’), (‘bought’, u’VBN’), (‘for’, u’IN’), (‘the’, u’DT’), (‘new’, u’JJ’), (‘apartment’, u’NN’), (‘of’, u’IN’), (‘John’, u’NNP’)]reg_exp = “NP: {? * }” rp = nltk.RegexpParser(reg_exp)result = rp.parse(result.tags)print(result)
(S (NP A/DT black/JJ television/NN) and/CC (NP a/DT white/JJ stove/NN) were/VBD bought/VBN for/IN (NP the/DT new/JJ apartment/NN)of/IN John/NNP)

from nltk import word_tokenize, pos_tag, ne_chunkinput_str = “Bill works for Apple so he went to Boston for a conference.”print ne_chunk(pos_tag(word_tokenize(input_str)))
(S (PERSON Bill/NNP) works/VBZ for/IN Apple/NNP so/IN he/PRP went/VBD to/TO (GPE Boston/NNP) for/IN a/DT conference/NN ./.)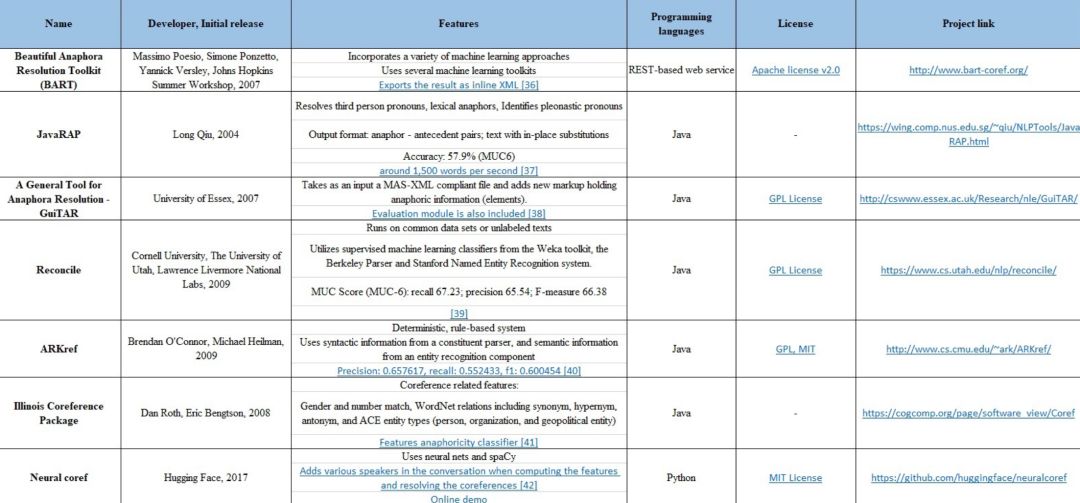
input=[“he and Chazz duel with all keys on the line.”]from ICE import CollocationExtractorextractor = CollocationExtractor.with_collocation_pipeline(“T1” , bing_key = “Temp”,pos_check = False)print(extractor.get_collocations_of_length(input, length = 3))
[“on the line”]
https://medium.com/@datamonsters/text-preprocessing-in-python-steps-tools-and-examples-bf025f872908
今天给大家推荐,七月在线【机器学习集训营 第十二期】课程。
1
专业的教学模式
【机器学习集训营 第十二期】,采取十二位一体的教学模式,包括12个环节:“入学测评、直播答疑、布置作业、阶段考试、毕业考核、一对一批改、线上线下结合、CPU&GPU双云平台、组织比赛、联合认证、面试辅导、就业推荐”。
2
完善的实战项目
只学理论肯定是不行的,学机器学习的核心是要做项目,本期集训营共13大实战项目.



3
专家级讲师团队
本期集训营拥有超豪华讲师团队,学员将在这些顶级讲师的手把手指导下完成本期课程的学习,挑战40万年薪。


授课老师、助教老师,多对一服务。从课上到课下,从专业辅导到日常督学、360度无死角为学员安心学习铺平道路。陪伴式解答学员疑惑,为学员保驾护航。
4
六大课程特色


5
完善的就业服务
学员在完成所有的阶段学习后,将会有一对一的就业服务,包括简历优化、面试求职辅导及企业内推三大部分。
为了确保学员能拿到满意的offer,七月在线还专门成立就业部,会专门为集训营学员提供就业服务,保证每一位学员都能拿到满意的offer。
扫码查看课程详情,同时大家也可以去看看之前学员的面试经验分享。
戳↓↓“阅读原文”查看课程详情!
评论