
Inception 新结构 | 究竟卷积与Transformer如何结合才是最优的?
共 6197字,需浏览 13分钟
·
2022-06-30 11:50


最近的研究表明,
Transformer具有强大的远程关系建模的能力,但在捕获高频局部信息方面却无能为力。为了解决这个问题,本文提出了Inception Transformer,简称iFormer,可以有效地学习视觉数据中包含高频和低频信息的综合特征。具体来说,本文设计了一个
Inception mixer将卷积和最大池化的优势移植到Transformer中捕获高频信息。与最近的mixer不同,Inception mixer通过通道拆分机制带来更高的效率,同时采用并行卷积/最大池化路径和自注意力路径作为high-frequency mixer和low-frequency mixer可以灵活地对分散在其中的判别信息进行建模。考虑到
Low-level Layer在捕捉高频细节方面发挥更多作用,而High-level Layer在建模低频全局信息方面发挥更多作用,作者进一步引入frequency ramp structure,即逐渐减小送到high-frequency mixer的维度,并增加low-frequency mixer的维度(一句话就是ResNet的层次设计思想),可以有效地权衡不同层的高频和低频分量。在一系列视觉任务上对
iFormer进行了基准测试,并展示了它在图像分类、COCO检测和 ADE20K 分割方面的出色表现。例如,iFormer-S在 ImageNet-1K 上达到了 83.4% 的 top-1 准确率,比DeiT-S高出 3.6%,在只有 1/4 的参数和 1/3 的FLOPs的情况下甚至略好于更大的模型Swin-B(83.3%)。
1简介
Transformer 席卷了自然语言处理 (NLP) 领域,在许多 NLP 任务(例如机器翻译和问答)中实现了惊人的高性能。这在很大程度上归功于其强大的Self-Attention机制对数据中的长期依赖关系进行建模的能力。它的成功促使研究人员研究它对计算机视觉领域的适应,而 Vision Transformer (ViT) 是先驱。该架构直接继承自 NLP,但应用于以原始图像块作为输入的图像分类。后来,许多 ViT 变体被开发出来,以提高性能或扩展到更广泛的视觉任务,例如目标检测和分割。
ViT 及其变体在视觉数据中具有很强的捕获低频的能力,主要包括场景或对象的全局形状和结构,但对于学习高频的能力不是很强,主要包括局部边缘和纹理。这可以直观地解释:Self-Attention是 ViTs 中用于在非重叠 patch tokens之间交换信息的主要操作,也是一种全局操作,相对于高频局部信息Self-Attention更能捕获数据中低频的全局信息。
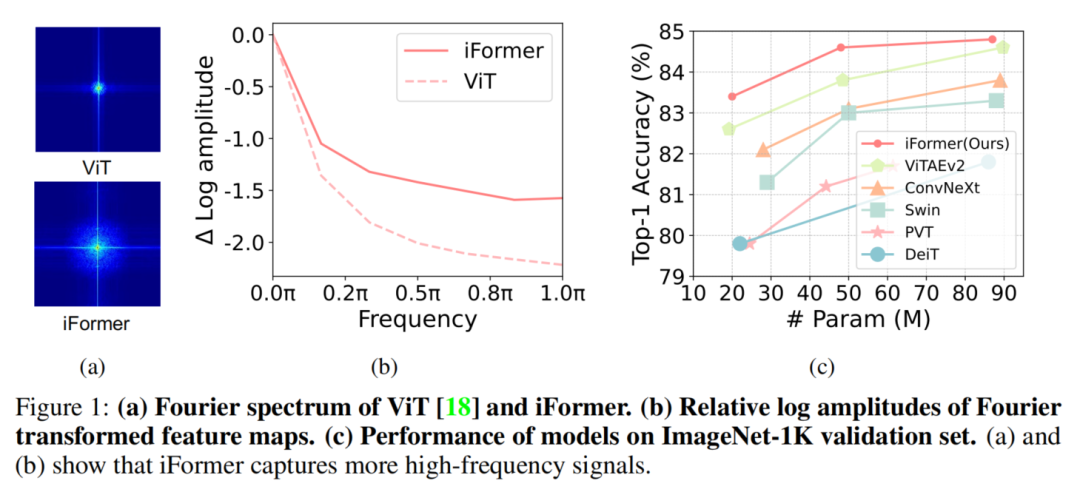
如图1(a)和1(b)所示,傅里叶频谱和傅里叶的相对对数幅度表明,ViT 倾向于捕捉低频信号,但很少捕捉高频信号。这一观察结果也表明 ViT 呈现了低通滤波器的特性。这种低频偏好会损害 ViT 的性能,因为:
在所有层中填充低频信息可能会恶化高频成分,例如局部纹理,并削弱 ViT的建模能力;高频信息也具有区分性,可以使许多任务受益,例如(细粒度)分类。
实际上,人类视觉系统以不同的频率提取视觉基本特征:低频提供有关视觉刺激的全局信息,而高频传达图像中的局部空间变化(例如,局部边缘/纹理)。因此,有必要开发一种新的 ViT 架构来捕获视觉数据中的高频信息和低频信息。
CNN 是一般视觉任务的最基本支柱。与 ViT 不同的是,它们通过感受野内的局部卷积来覆盖更多的局部信息,从而有效地提取高频表示。考虑到它们的互补优势,最近的研究已经整合了 CNN 和 ViT。一些方法以串行方式堆叠卷积层和注意力层,以将局部信息注入全局上下文。不幸的是,这种串行方式仅在一层中对一种类型的依赖关系进行建模,无论是全局的还是局部的,并且在局部建模期间丢弃了全局信息,反之亦然。其他工作采用并行注意力和卷积来同时学习输入的全局和局部依赖关系。然而,一部分通道用于处理局部信息,另一部分用于全局建模,这意味着如果处理每个分支中的所有通道,当前的并行结构具有信息冗余。
为了解决这个问题本文提出了一种简单高效的 Inception Transformer (iFormer),如图 2 所示,它将 CNN 在捕获高频方面的优点移植到 ViT。iFormer 的关键组件是一个 Inception token mixer,如图 3 所示。该 Inception mixer 旨在通过捕获数据中的高频和低频来增强 ViT 在频谱中的感知能力。
为此,Inception mixer 首先将输入特征沿通道维度进行拆分,然后将拆分后的分量分别馈入 high-frequency mixer 和 low-frequency mixer。这里的 high-frequency mixer 由最大池化操作和并行卷积操作组成,而 low-frequency mixer 由 ViTs 中的标准Self-Attention实现。通过这种方式,iFormer 可以有效地捕获相应通道上的特定频率信息,在图1(a)和1(b)中可以清楚地观察到在较宽的频率范围内iFormer可以学习到更全面的特征。
此外,作者还发现较低层通常需要更多的局部信息,而较高层需要更多的全局信息。这是因为,就像在人类视觉系统中一样,高频分量中的细节有助于低层捕捉视觉基本特征,并逐渐收集局部信息以对输入进行全局理解。受此启发,作者设计了一个frequency ramp structure。特别是,从低层到高层逐渐将更多的通道维度提供给low-frequency mixer,而将更少的通道维度提供给high-frequency mixer。
实验结果表明,iFormer 在图像分类、目标检测和分割等多个视觉任务上超越了最先进的 ViT 和 CNN。如图1(c)所示,对于不同的模型大小,iFormer 对 ImageNet-1K 上的流行框架进行了一致的改进,例如 DeiT、Swin 和 ConvNeXt。同时,iFormer 在 COCO 检测和 ADE20K 分割方面优于最近的框架。
2本文方法
2.1 回顾ViT
首先回顾一下 Vision Transformer。对于视觉任务,Transformers 首先将输入图像拆分为一系列Token,每个Patch Token投影到具有更精简层的隐藏表示向量中,表示为 或 ,其中 N 是Patch Token的数量,C 表示特征的维度。然后,所有Token与位置嵌入相结合,并馈送到包含Multi-Head Self-Attention(MSA) 和前馈网络 (FFN) 的 Transformer 层。
在 MSA 中,基于注意力的Mixer在所有Patch Token之间交换信息,因此它强烈关注聚合所有层的全局依赖关系。然而,全局信息的过度传播会加强低频表示。从图1(a)中的傅里叶谱的可视化可以看出,低频信息主导了 ViT 的表示。这实际上会损害 ViT 的性能,因为它可能会恶化高频成分,例如局部纹理,并削弱 ViT 的建模能力。在视觉数据中,高频信息也具有判别力,可以使许多任务受益。因此,为了解决这个问题提出了一个简单高效的 Inception Transformer,如图 2 所示,具有2个关键的创新,即 Inception mixer 和frequency ramp structure。
2.2 Inception token mixer
本文提出了一个Inception mixer 将 CNN 提取高频表示的强大能力移植到 Transformer 中。其详细架构如图 3 所示。Inception mixer 不是直接将图像标记输入到 MSA Mixer中,而是首先沿通道维度分割输入特征,然后将分割后的分量分别输入到高 high-frequency mixer 和 low-frequency mixer中。这里的high-frequency mixer由一个最大池化操作和一个并行卷积操作组成,而low-frequency mixer由一个Self-Attention实现。
从技术上讲,给定输入特征图 ,沿通道维度将 X 分解为 和 ,其中 。然后,将 和 分配给high-frequency mixer 和 low-frequency mixer。
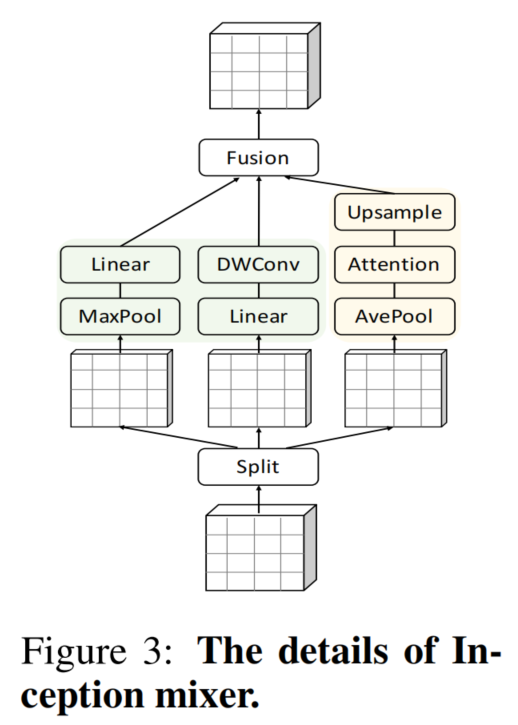
1、High-frequency mixer
考虑到最大滤波器的敏锐敏感性和卷积运算的细节感知,提出了一种并行结构来学习高频分量。沿通道将输入 分为 和。如图 3 所示, 嵌入了一个最大池化和一个线性层, 被馈送到一个线性和一个深度卷积层:
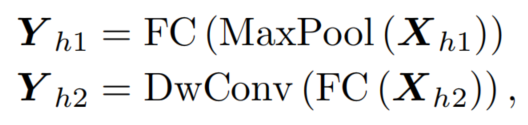
其中 和 表示 high-frequency mixer 的输出。
最后,high-frequency mixer 和 low-frequency mixer 的输出沿通道维度concat:
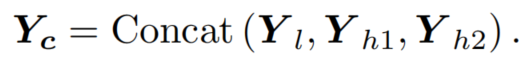
上采样操作为每个要插值的位置选择最近点的值,而不考虑任何其他点,这会导致相邻Token之间过度平滑。因此作者设计了一个融合模块来克服这个问题,即使用深度卷积来交换Patch之间的信息,同时保持一个跨通道线性层,该层像以前的 Transformer 一样在每个位置工作。最终输出可以表示为
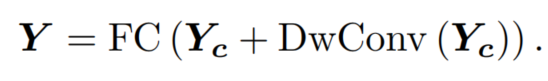
与原版 Transformer 一样,iFormer 配备了前馈网络 (FFN),不同的是它还结合了上述Inception Token mixer(ITM);LayerNorm(LN) 在 ITM 和 FFN 之前应用。因此,Inception Transformer Block 定义为
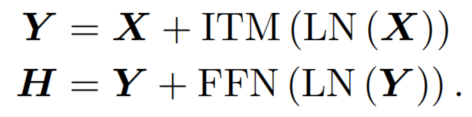
2、Low-frequency mixer
iFormer使用 vanilla multi-head self-attention 在low-frequency mixer的所有Token之间传递信息。尽管注意力学习全局表示的能力很强,但特征图的大分辨率会在较低层带来巨大的计算成本。因此,简单地利用平均池化层在注意力操作之前减少 的空间尺度,并在注意力操作之后使用上采样层来恢复原始空间维度。这种设计大大减少了计算开销,并使注意力操作集中在嵌入全局信息上。这个分支可以定义为
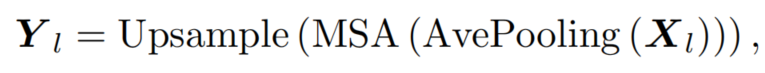
其中 是low-frequency mixer的输出。请注意,池化层和上采样层的kernel-size和stride仅在前2个stage设置为 2。
2.3 Frequency ramp structure
在一般的视觉框架中,Low-level Layer在捕获高频细节方面发挥更多作用,而High-level Layer在建模低频全局信息方面发挥更多作用,即 ResNet 的分层表示。与人类一样,通过捕获高频分量中的细节,较低层可以捕获视觉基本特征,同时也逐渐收集局部信息以实现对输入的全局理解。受到启发,设计了一种Frequency ramp structure,该结构将更多通道维度分配给low-frequency mixer,更少的通道维度分配给high-frequency mixer。
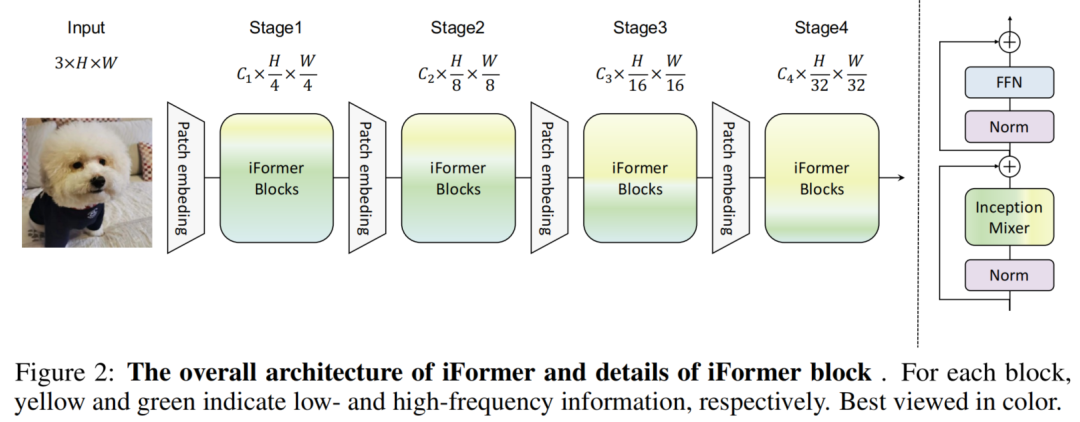
具体来说,如图 2 所示,Backbone有4个阶段,具有不同的通道和空间维度。对于每个Block定义了一个通道比以更好地平衡高频和低频分量,即 Ch/C 和 Cl/C,其中 Ch/C + Cl/C = 1。在建议的Frequency ramp structure中,Ch /C由浅到深逐渐减小,而Cl/C逐渐增大。因此,通过灵活的频率斜坡结构,iFormer 可以有效地权衡所有层的高频和低频分量。
2.4 模型架构
在这项工作中,iFormer 的三个变体用于在计算配置下进行公平比较,即 iFormer-S、iFormer-B 和 iFormer-L。表 7 显示了它们的详细配置。继 Swin[] 之后,iFormer 采用 4 级架构,具有H/4×W/4、H/8×W/8、H/16×W/16、H/32×W/32输入尺寸,其中H和W是输入图像的宽度和高度。在每个 iFormer Block 中,Ch/C 和 Cl/C 用于平衡高频和低频分量。如表 7 所示,Ch/C 从浅层到深层逐渐减小,而 Cl/C 逐渐增加。iFormer Block 使用深度卷积和最大池化作为high-frequency mixer。这里将深度卷积和最大池化的kernel-size设置为 3×3。

3实验
3.1 消融实验
1、Inception token mixer
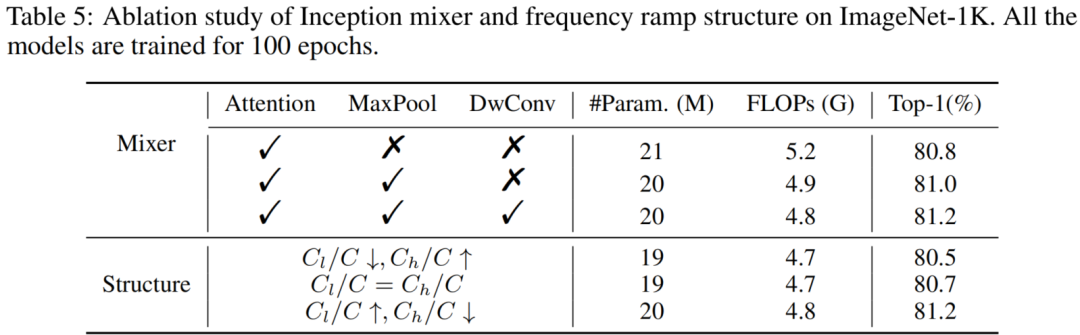
为了评估Inception mixer中组件的效果,越来越多地从完整模型中删除每个分支,然后在表 5 中报告结果,其中 √ 和 × 表示是否启用了相应的分支。可以观察到,将注意力与卷积和最大池化相结合可以比仅注意力混合器获得更好的准确度,同时使用更少的计算复杂度,这暗示了 Inception Token Mixer 的有效性。

为了进一步探索这个方案,图 4 可视化了 Inception mixer 中 Attention、MaxPool 和 DwConv 分支的傅里叶谱。可以看到Attention mixer在低频上有更高的浓度;使用high-frequency mixer,即卷积和最大池可以促使模型学习高频信息。
总体而言,这些结果证明了 Inception mixer 在扩展 Transformer 在频谱中的感知能力方面的有效性。
2、Frequency ramp structure
在表5中可以清楚地看到,具有 Cl/C↑、Ch/C↓ 的模型优于其他两个模型,这与之前的研究一致。因此,这表明了Frequency ramp structure的合理性及其在学习辨别视觉表征方面的潜力。
3、可视化
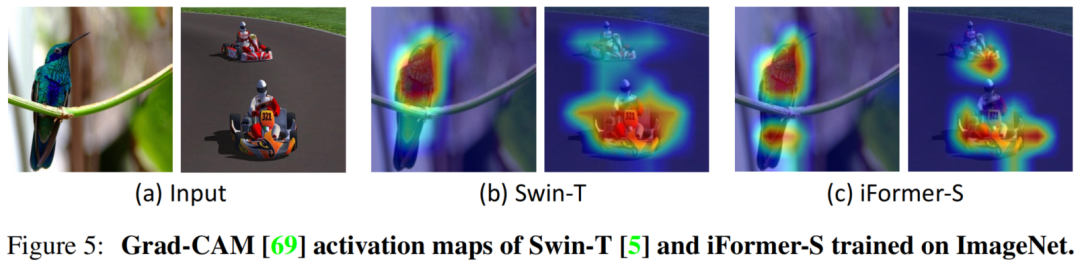
在图 5 中可视化了 iFormer-S 和 Swin-T 模型在 ImageNet-1K 上训练的 Grad-CAM 激活图。可以看出,与Swin相比,iFormer能够更准确、更完整地定位物体。例如,在蜂鸟图像中,iFormer 会跳过树枝并准确地关注包括尾巴在内的整只鸟。
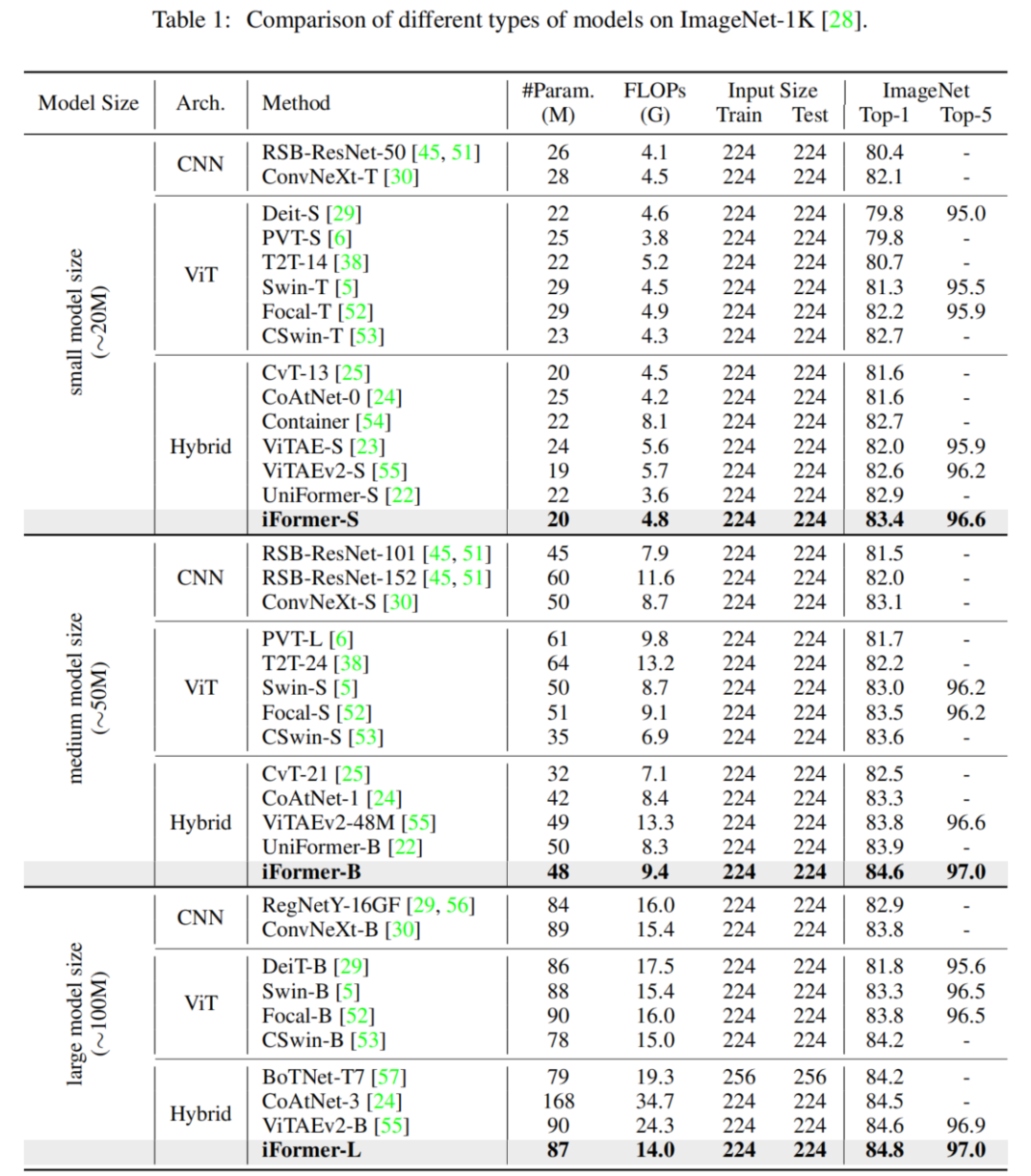
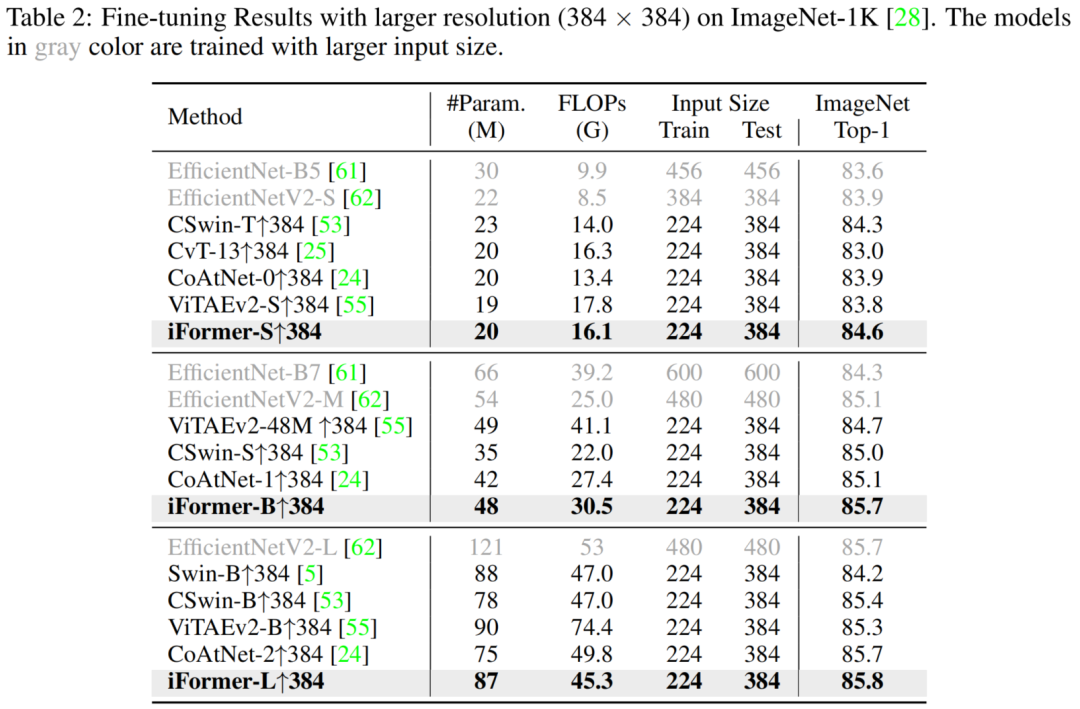
3.2 图像分类
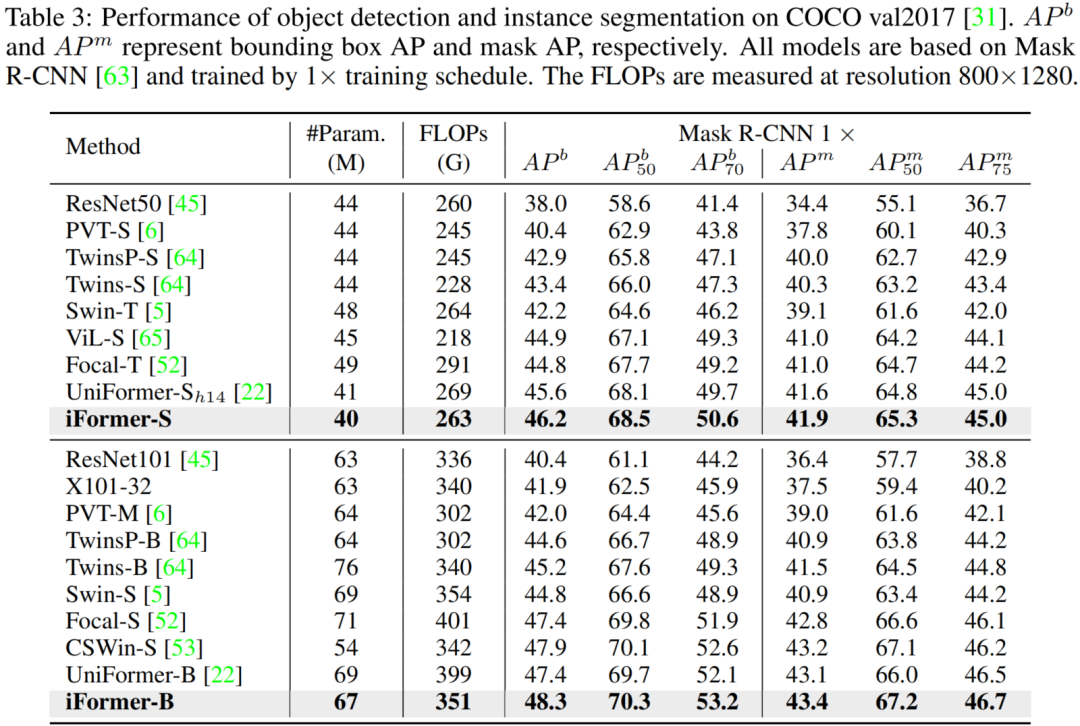
3.3 目标检测与实例分割
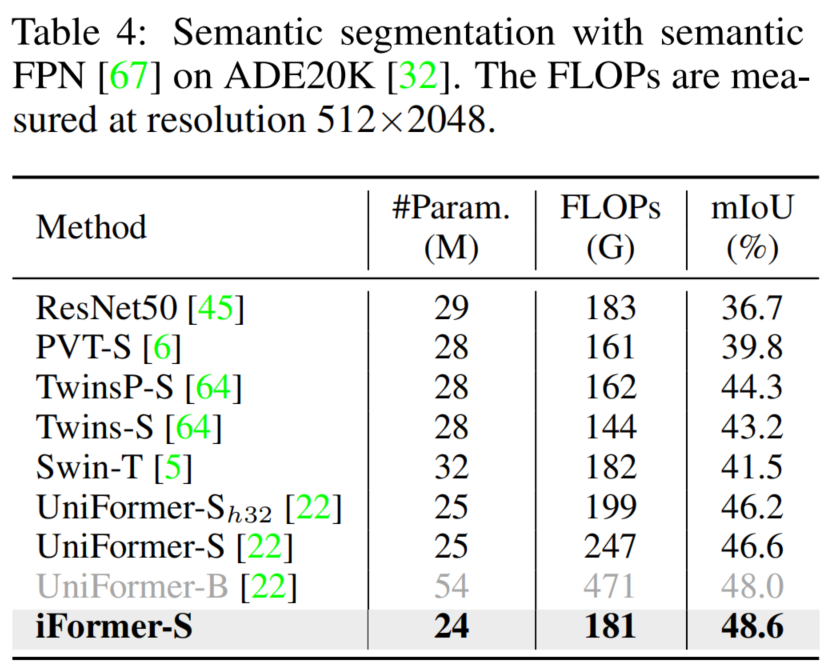
3.4 语义分割
4参考
[1].Inception Transformer
5推荐阅读
即插即用 | SIoU 实现50.3 AP+7.6ms检测速度精度、速度完美超越YoloV5、YoloX
Sparse RCNN再升级 | ResNet50在不需要NMS和二分匹配的情况下达到48.1AP
即插即用 | RandomMix 集百家之长实现超越Mixup的数据增强方法!
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
