
厉害了,用 Node.js 实现一个简易 Git!
手把手教你理解轮子之git
大厂技术 高级前端 Node进阶
点击上方 程序员成长指北,关注公众号
回复1,加入高级Node交流群
当年他陈刀仔,能用20块赢到 3700万,今天我卢.....
Sry,串台了
当年他linus 能用两个星期写完Git, 今天我叶某人.... (好吧,当场给linus跪下)

前言
本文试图理解git的原理,重写部分git命令,从最底层的几个命令开始,听起来很离谱,做起来也很离谱,但是真正去做了,发现,诶,好像没有那么离谱。
俗话说得好(我也不知道哪里来的俗话,maybe 我自己说的),理解一个东西最好的方法就是实现它。git作为我们每天都需要去打交道的一个东西,了解它和熟悉怎么去使用它也是我们每个人的必要技能。
现状分析
来,我们克服一下恐惧,我们为什么会觉得这个东西很复杂,因为它真的很复杂,光是上层命令,就有各种各样的用法,就算笔者也不敢说真的能够精通,关键是他的文档 居然够写一本书【Pro Git】[1],还有王法吗,还有法律吗?
不过再仔细想想,我们需要了解这么多的特性吗,我们每天日常使用的也就是几个命令,我们是不是只需要了解他的底层机制和那几个命令就行了?好像没那么可怕了?OK,我们进入正题。
对于本文,其实你并不需要了解太多的东西,一点点的Git基本知识,一点点基本语言知识,一点点的shell知识,OK,条件具备了,我们可以开始愉快的玩耍了。
首先我们例举一下,我们需要用到的本地命令有些啥
git addgit commitgit checkoutgit rmgit initgit loggit refloggit show-refgit mergegit rebasegit cat-filegit hash-objectgit ls-treegit tag
嗯,差不多,单纯本地的仓库 我们要用到的命令是不是就这些,我们将在主要内容分享完之后,再回到这里来理解这些命令。
GIT底层结构
不知道大家有没有好奇过这些东西,这些玩意都是啥?我们如何靠这个目录下的文件来管理我们各种各样奇奇怪怪的提交,而且还能回溯呢?
GIT目录
先来看一下目录结构:
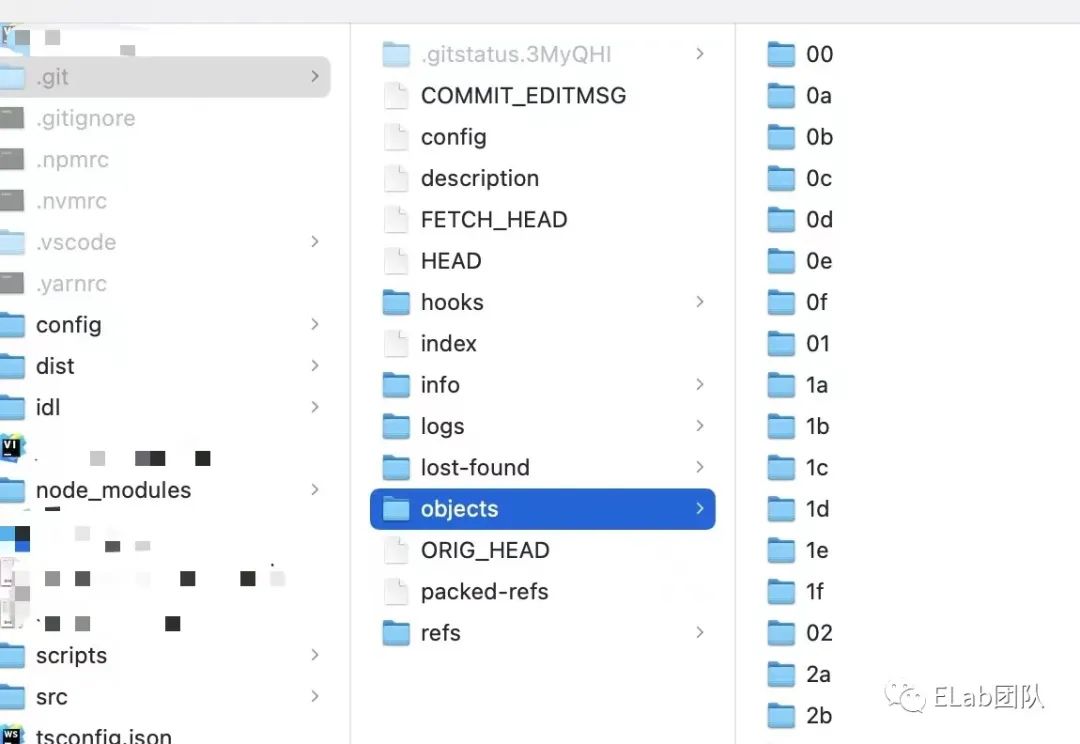
├── COMMIT_EDITMSG // 上一次提交的 msg
├── FETCH_HEAD // 远端的所有分支头指针 hash
├── HEAD // 当前头指针
├── ORIG_HEAD //
├── config // 记录一些配置和远端映射
├── description // 仓库描述
├── hooks // commit lint规则 husky植入
│ ├── applypatch-msg
│ ├── applypatch-msg.sample
│ ├── commit-msg
│ ├── commit-msg.sample
│ ├── fsmonitor-watchman.sample
│ ├── post-applypatch
│ ├── post-checkout
│ ├── post-commit
│ ├── post-merge
│ ├── post-receive
│ ├── post-rewrite
│ ├── post-update
│ ├── post-update.sample
│ ├── pre-applypatch
│ ├── pre-applypatch.sample
│ ├── pre-auto-gc
│ ├── pre-commit
│ ├── pre-commit.sample
│ ├── pre-merge-commit
│ ├── pre-merge-commit.sample
│ ├── pre-push
│ ├── pre-push.sample
│ ├── pre-rebase
│ ├── pre-rebase.sample
│ ├── pre-receive
│ ├── pre-receive.sample
│ ├── prepare-commit-msg
│ ├── prepare-commit-msg.sample
│ ├── push-to-checkout
│ ├── push-to-checkout.sample
│ ├── sendemail-validate
│ ├── update
│ └── update.sample
├── index // 暂存区
├── info
│ ├── exclude
│ └── refs
├── logs // 顾名思义,记录我们的git log
│ ├── HEAD
│ └── refs
├── objects // git 存储的我们的文件
│
├── lost-found //一些悬空的文件
│ ├── commit
│ └── other
├── packed-refs 打包好的指针头
└── refs // 所有的hash
├── heads
├── remotes
└── tags
对这些仓库分析完,突然发现,我们是不是只需要这一个目录下的东西,就可以将一个repo的所有源信息拷贝。
记住我们刚刚所讲的东西,这个目录的一些结构,这对理解我们后面的命令和底层存储帮助很大,我们将在后面部分深入介绍。

GIT Hash
首先git中的对象,我们一共有4种type,分别是 commit / tree / blob / tag。
我们先需要摸清楚git算hash的规则,我们一共有四种对象type,这四个type一定是要附带到我们sha1加密后的hash里面的,还有一些文本附加信息,整体的规则如下。
"{type} {content.length}\0{content}"
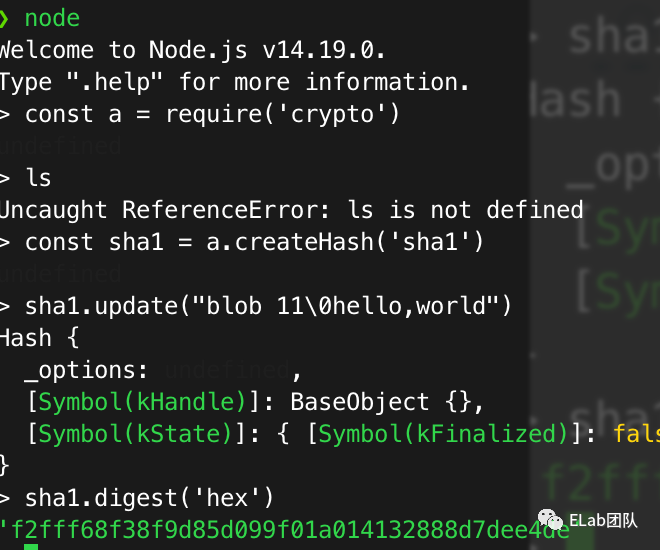
OK,那我们来尝试下生成hash值,看看我们生成的,和git 生成的 是否一致。
echo -n "hello,world" | git hash-object --stdin
const crypto = require('crypto'),
const sha1 = crypto.createHash('sha1');
sha1.update("blob 11\0hello,world");
console.log(sha1.digest('hex'));

git 本质是一种类kv数据库的文件系统,通过sha1算法生成的hash作为key,对应到我们的git的几类对象,然后再去树状的寻址,最底层存储的是我们的文件内容。
讲到这了,衍生一下关于git使用sha1的目的以及前几年google碰撞sha1算法导致的 sha1算法不安全的问题,git使用sha1进行hash的目的,更多的是为了验证文件完整性 防损坏等目的,同时linus本人以及stackoverflow上对这个问题也有一些讨论和回复,大家可以移步观看。
stackoverflow的讨论[2] linus针对google sha1碰撞的邮件[3]
生成hash的算法我们介绍完事了,那接下来就是根据hash去找东西了,前文提到了,git一共存在四种对象,我们分别对四种对象以及内容寻址进行介绍。
GIT 对象
blob
这是最底层的对象,记录的是文件内容,对,仅仅是文件内容,通过我们上面计算hash的方式可以看出来,不管文件名怎么变化,我们所对应的那块内容没有改变,hash值就不会改变,找到的永远会是那个blob。


这也是为什么 git是用来管理代码以及各种类型的文本的一种好方式,而不是用来管理word/pdf (误)。
在纯文本类型文件管理中,git只需要保存diff就行了,而如果我们代码中全是二进制文件,那简直是回溯噩梦,可能真实资源就两个pdf,一个word文件,但是版本太多,一个git仓库大小几个g也不是不可能。
OK,这里可能有些同学要问了,那我如果真的需要存储很多频繁变动的二进制文件,比如多媒体资源/ psd啥的, 那我需要怎么搞?好的,家人们,上链接。Git LFS(Large file storage)[4]一句话介绍,把我们的大文件变成文件指针存储在对象中,再去lfs拉取对应文件。
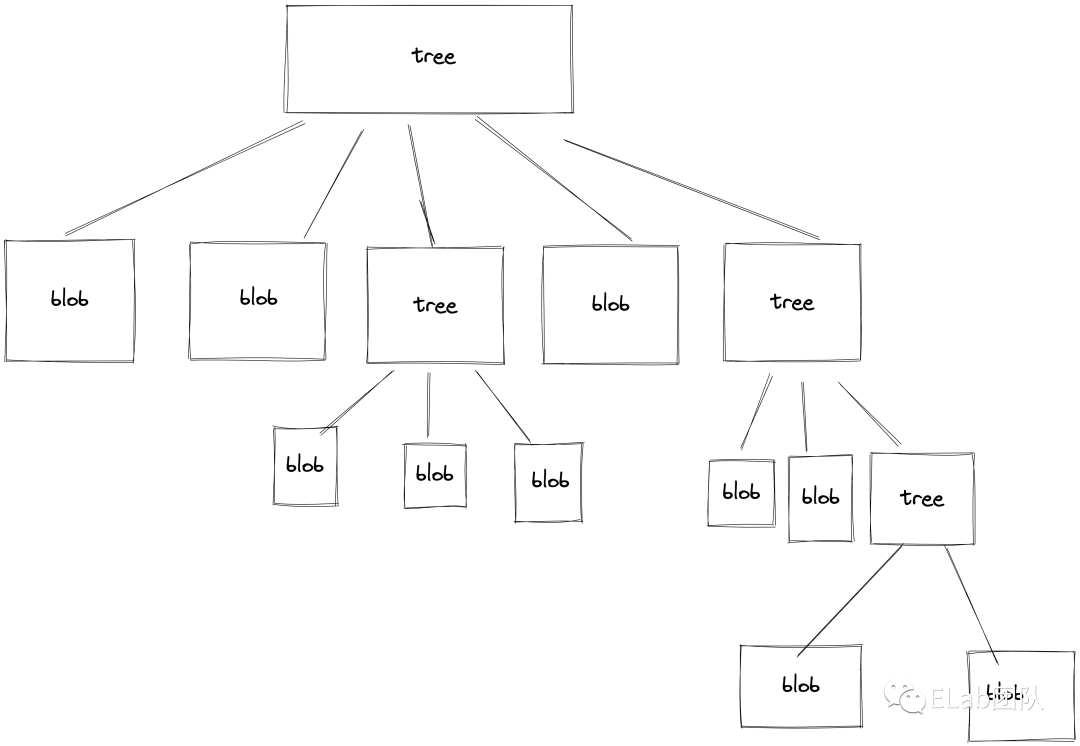
tree
刚刚我们说了,blob对象是纯粹的内容,有些不对劲,我们内容需要索引,我怎么去找到他?这一节的标题叫做 tree,对,他就是以树状结构来进行组织的,随便点开一个objects下面的文件cat-file看看。
可以看出来,我们整个对象的组织形式就是一棵多叉树。通过树级层级一层一层寻址,最后找到我们的内容块。整体的组织形式就是下图。
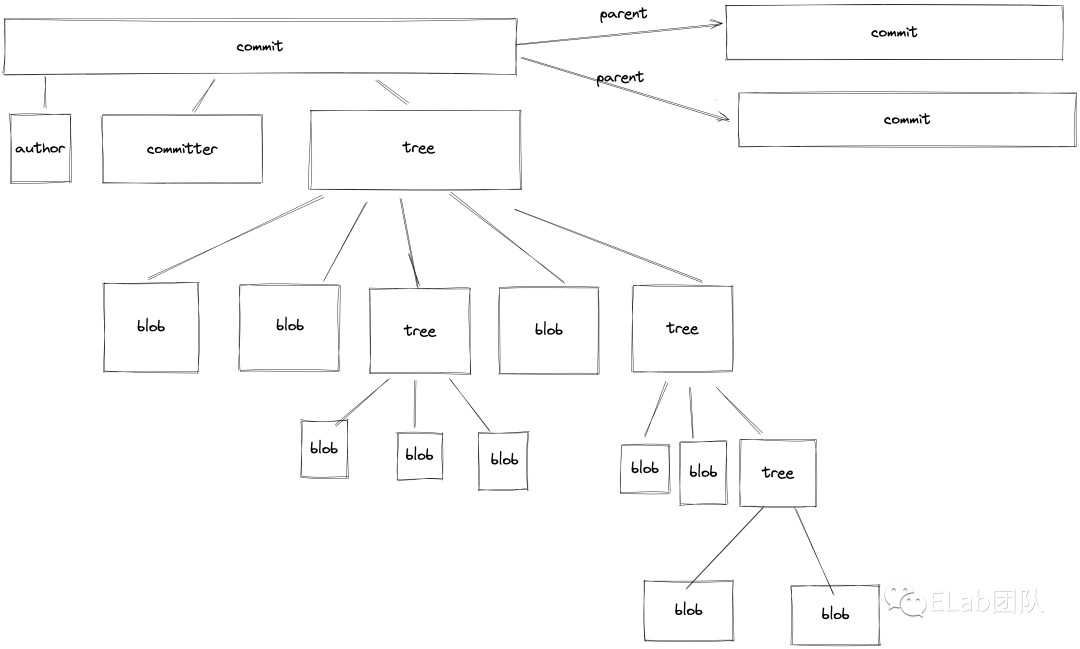
commit
现在还有另一个问题,不过我们其实上面的演示已经解释了一部分这个问题了, 一个commit对应的信息其中只有几种,
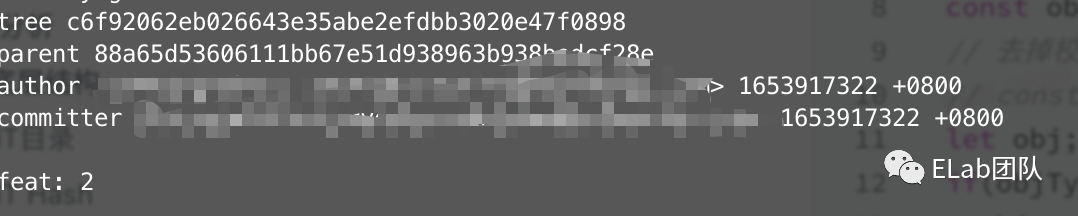
author与对应的时间点 commit的时候我们输入的描述 这个commit所指向的tree 这个commit的parent 即父节点
git是以类似单向链表的形式将我们的一个个提交组织起来的,同时,同时一个节点至多有2个父节点。到此,其实整个git内容存储的结构我们已经捋清楚了。
tag
最后简单介绍下,最后一种对象,tag是对某个commit的描述,其实也是一种commit。
小结
总结一下我们以上说的内容,我们可以得到git的一个设计思路,git记录的是一个a → b过程的链表,通过链表,我们可以逐步回溯到a,在此之下呢,采用了一种多叉树形结构对我们的hash值进行分层记录,最底层,通过我们的hash值进行索引,对应到一个个压缩后的二进制objects。这就是整个git的结构设计。还有一些 git对于查找效率的优化手段,压缩手段。
对以上内容了解了之后,关于我们的分支本质上,其实也是对应一个commit,只是多了一个ref指向这个commit而已,是不是对git整个清晰多了。
这里留给大家一个课后问题吧,git 的 gc怎么去实现的, 整个完整过程是啥样的,由于这些内容并不是本文的核心内容,就不在这里展开了。
实现
前期准备
回想一下前面讲的,我们需要的东西有些什么,sha1,这个可以用crypto, zlib,node中也带了这个,可以通过 require('zlib')拿到。
识别命令参数
首先,让node环境能够读我们的一些命令,来干各种各样的事情,通过process的解析,我们能够获得输入的参数
enum CommandEnum{
Add= 'add',
Init = 'init',
...
}
const chooseCommand = (command:CommandEnum) => {
switch(command){
case CommandEnum.Add:
return add();
case CommandEnum.Init:
return init();
...
default:
break;
}
console.log("暂不支持此命令")
}
chooseCommand(process.argv[2] as CommandEnum);
init
okk,我们现在进行下一步,万事开头难,先开个头吧。使用我们的命令,初始化一个git仓库。
const init = ()=>{
fs.mkdirSync('.git');
fs.mkdirSync('.git/refs')
fs.mkdirSync('.git/objects')
fs.writeFileSync('.git/HEAD','ref: refs/heads/master')
fs.writeFileSync('.git/config',`
[core]
repositoryformatversion = 0
filemode = true
bare = false
logallrefupdates = true
ignorecase = true
precomposeunicode = true
`);
fs.writeFileSync('.git/description','');
}
写入和读取
初始化完成了,我们有了一个存储库,接着就是把大象装进冰箱。
刚刚我们在分享的过程中,不断的用到两个命令 git hash-object 和 git cat-file,这两个命令,在我们日常工作中,其实不太会用到,他们两干嘛使的呢。Git 中存在两个命令的概念,一个是底层命令(Plumbing) ,另一个就是我们日常会使用到的上层命令(Porcelain) , 高层命令是基于底层命令的封装,让我们使用起来更为方便。
引入一些npm包,定义一些结构体
import fs from 'fs';
import zlib from 'zlib';
import crypto from 'crypto';
export enum GitObjectType{
Commit = 'commit',
Tree = 'tree',
Blob = 'blob',
Tag = 'tag'
}
来实现一个简单的读取blob对象的方法,比较简陋,还不支持对content进行解析,我们将在后续完善。
export const readObject = (sha1='f8eb512de72634ca12328d85f70b696414473914')=>{
const data = fs.readFileSync(`.git/objects/${sha1.substring(0,2)}/${sha1.substring(2)}`);
const a = zlib.inflateSync(data).toString('utf8');
const typeIndex = a.indexOf(' ');
const lengthIndex = a.indexOf(`\0`);
const objType = a.substring(0,typeIndex);
const length = a.substring(typeIndex +1,lengthIndex);
const content = a.substring(lengthIndex+1);
// console.log(a);
return {objType,length,content};
}
ok, 有了读之后,我们还需要往里写。
export const createObject = (obj:GitObject)=>{
const data = obj.serialize();
const sha1 = crypto.createHash('sha1');
sha1.update(data);
const name = sha1.digest("hex");
const zipData = zlib.deflateSync(data);
console.log(name);
const dirName = `.git/objects/${name.substring(0,2)}`
fs.existsSync(dirName) && fs.mkdirSync(dirName);
fs.writeFileSync(`.git/objects/${name.substring(0,2)}/${name.substring(2)}`,zipData)
return name;
}
琢磨透了读和写的方法,我们的cat-file命令和hash-object命令实际上实现起来就很简单了,只需要调用现有的方法就行了。
先是cat-file 对hash 名的一个寻址,同时解压缩对应的objects,支持四个参数,分别返回不同的结果。我们直接读对象就完事了嗷。
export const catFile = ()=>{
const type = process.argv[3];
const sha1 = process.argv[4];
const res = readObject(sha1);
if(type ==='-t'){
console.log(res.type);
}
if(type==='-s'){
console.log(res.length);
}
if(type === '-e'){
console.log(!!res?.type)
}
if(type === '-p'){
console.log(res.content)
}
}
接着是hash-object,这个也简单的实现下,就是返回对应路径的hash值就行了
export const hashObject = ()=>{
const path = process.argv[3];
const data = fs.readFileSync(path);
const sha1 = crypto.createHash('sha1');
sha1.update(data);
const name = sha1.digest("hex");
console.log(name);
}
现在我们基本结构已经搭起来了,需要的是commit 和tree将文件串联起来,调用我们的cat-file试试,现在应该对commit和blob的解析是正确的, 但是tree的content的解析似乎有些问题,我们后面来看这个问题,但是commit对象的content和 blob的content不太一样。
内容解析完善
刚刚我们粗略的实现了一下读对象,能把内容块读出来了。接着我们来完善他,以便更好的服务于我们的四种对象,先改写下我们的readObject。
readObject
export const readObject = (sha1: string)=>{
const data = fs.readFileSync(`.git/objects/${sha1.substring(0,2)}/${sha1.substring(2)}`);
const buf = zlib.inflateSync(data)
const a = buf.toString('utf8');
const typeIndex = a.indexOf(' ');
const lengthIndex = a.indexOf(`\0`);
// console.log(a);
const objType = a.substring(0,typeIndex);
// 去掉校验, 其实这里需要记录长度和真实长度对比是否有错
// const length = a.substring(typeIndex +1,lengthIndex);
let obj;
if(objType===GitObjectType.Blob){
obj = new GitBlob(a.substring(lengthIndex+1));
}
if(objType===GitObjectType.Commit){
obj = new GitCommit(a.substring(lengthIndex+1))
}
if(objType===GitObjectType.Tree){
obj = new GitTree(buf.slice(lengthIndex+1))
}
return obj;
}
Blob对象实现起来很简单 就不在这里说了。
Commit对象实现起来稍微复杂一点,我们需要解析commit对象中的一些键值对,将他们都记住,同时把commit内容单独存起来。一个commit对象存储的东西,在上面我们已经介绍过了,通过一个map将他存储。
Commit object
class GitCommit extends GitObject{
type = GitObjectType.Commit;
data = '';
length = 0;
content:any;
map;
constructor(data:string){
super();
if(data){
this.data=data;
this.length = data.length;
}
}
serialize = ()=>{
return `${this.type} ${this.length}\0${this.data}`;
}
deserialize= ()=>{
console.log(this.recursiveParse(this.data))
return this.data;
}
recursiveParse = (data:string,map?:any):any=>{
if(!map){
map = new Map();
}
const space = data.indexOf(' ');
const nl = data.indexOf(`\n`);
console.log(space,nl);
if(space<0 || nl<space){
map.set("content",data);
return map;
}
const key = data.substring(0,space);
let end =0;
while(true){
end = data.indexOf(`\n`,end+1)
if(data[end+1] !== ' ') break;
}
const value = data.substring(space+1,end);
if(key ==='parent'){
map.has('parent') ? map.set(key+'1',value) : map.set(key,value);
} else {
map.set(key,value)
}
const restData = data.substring(end+1);
return this.recursiveParse(restData,map);
}
}
Tree Object解析
Tree Object 相对来说是我们解析起来最为复杂的一个对象,他不像前两个一样,能够通过直接toString就能拿到正常的文本,我们直接去解析就行了。Tree Object本身其实就是一个二进制对象,关键吧,他还有个误导,差点给笔者都给带偏了,他cat-file解析出来的文件,其实并不是他原本文件长的样子....,他做了一个格式化,且修改了顺序。
class GitTree extends GitObject{
type = GitObjectType.Commit;
data:Buffer = Buffer.from('');
length = 0;
constructor(data:Buffer){
super();
if(data){
this.data=data;
this.length = data.length;
}
}
serialize = ()=>{
return `${this.type} ${this.length}\0${this.data}`;
}
parseTreeOneLine = (data:Buffer,start:number)=>{
const x = data.indexOf(' ',start);
if(x<0){
return start+21;
}
const mode = data.slice(start,x).toString('ascii');
// const type =
const y = data.indexOf(`\x00`,x)
if(y<0){return x+21};
const path = data.slice(x+1,y).toString('ascii');
const sha1 = data.slice(y+1,y+21).toString('hex');
console.log(mode,path,sha1);
return y+21;
}
deserialize= ()=>{
const buffer = this.data;
let pos = 0;
let max = buffer.length;
while(pos<max){
pos = this.parseTreeOneLine(buffer,pos);
}
return this.data;
}
}
我们的底层基础简单实现,其实到这里就完结了,大致流程能够串起来了。
分支和ref:
分支名和ref其实也是键值对,分支名作为文件名存储在ref目录下,文件内容则是一串sha1值,这串sha1值来自于commit 头结点的hash值,我们可以通过这个commit 对象回溯到当时的场景。
log与reflog
单纯的文本文件,记录一些commit对象以及时间点等。大家可以下来再去研究研究。
暂存区:
不过大家可能会有问题,不对啊,我们平时提交不是还有stage的概念吗,这一块东西呢?确实,少了这一块,不过这一块也是git底层相对麻烦的一部分(数据处理太多T_T),所以我并不打算在这篇分享中去实现他,有兴趣的同学可以参考这个链接 git index结构[5]。
后语
分享到这就差不多了,实现了部分的底层读写api,其他的api就不一一实现了,有兴趣可以下来实现。
课后作业:
git 的gc问题 底层命令来实现我们日常调用的上层命令效果 怎么去实现一个远程的git中心服务器,远程的命令怎么关联? 补充实现一个git
最后的最后,作为linus的脑残粉,linus的一句话,送给大家,talk is cheap, show me the code .
引用文档:
https://www.open-open.com/lib/view/open1328069609436.html
http://gitlet.maryrosecook.com/docs/gitlet.html
https://git-scm.com/docs/git-add/zh_HANS-CN
https://wyag.thb.lt/#org947aee7
Node 社群
我组建了一个氛围特别好的 Node.js 社群,里面有很多 Node.js小伙伴,如果你对Node.js学习感兴趣的话(后续有计划也可以),我们可以一起进行Node.js相关的交流、学习、共建。下方加 考拉 好友回复「Node」即可。
如果你觉得这篇内容对你有帮助,我想请你帮我2个小忙:
1. 点个「在看」,让更多人也能看到这篇文章 2. 订阅官方博客 www.inode.club 让我们一起成长 点赞和在看就是最大的支持