
深度学习难分样本挖掘(Hard Mining)
数据派THU
共 2248字,需浏览 5分钟
·
2022-04-16 22:29

来源:深度学习这件小事 本文约1600字,建议阅读8分钟
本文带你将难分样本抽取出来,通过训练,使得正负样本数量均衡。
正样本:我们想要正确分类出的类别所对应的样本,例如,我们需要对一张图片分类,确定是否属于猫,那么在训练的时候,猫的图片就是正样本。
负样本:根据上面的例子,不是猫的其他所有的图片都是负样本
难分正样本(hard positives):错分成负样本的正样本,也可以是训练过程中损失最高的正样本
难分负样本(hard negatives):错分成正样本的负样本,也可以是训练过程中损失最高的负样本
易分正样本(easy positive):容易正确分类的正样本,该类的概率最高。也可以是训练过程中损失最低的正样本
易分负样本(easy negatives):容易正确分类的负样本,该类的概率最高。也可以是训练过程中损失最低的负样本。
二、核心思想
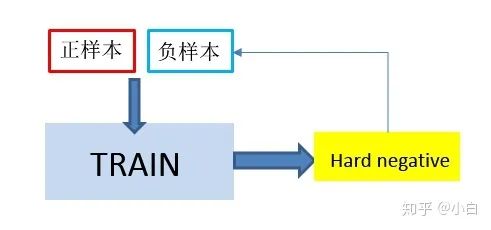
离线:
在线:
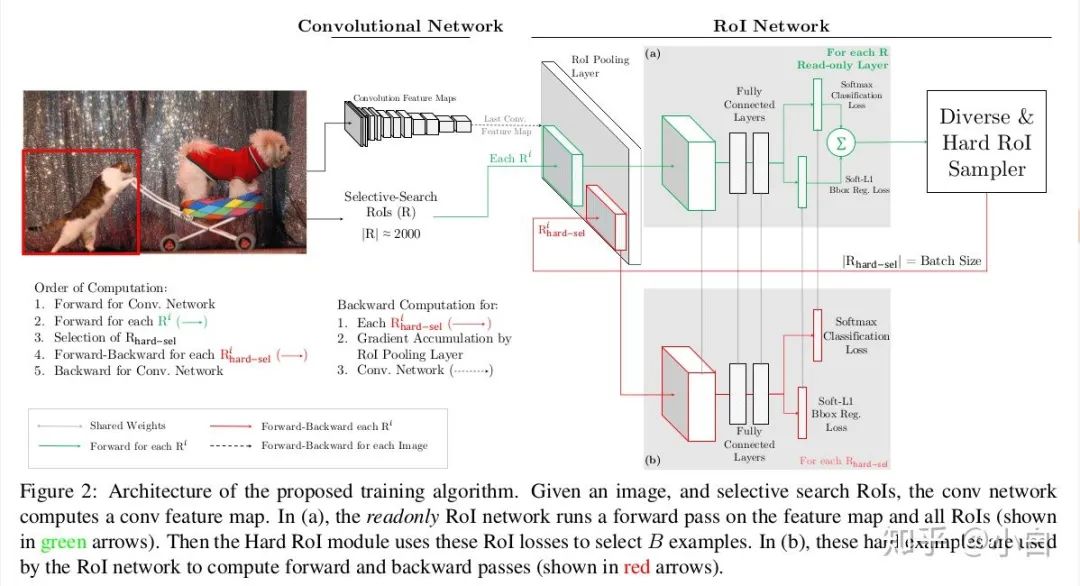
四、扩展idea
评论