
【NLP】Prompt-Tuning这么好用?
使用prompts去调节预训练模型处理文本分类任务在小样本上已经取得了比直接finetuning模型更好的效果,prompt-tuning的核心思想就是嵌入一小段文本,比如对于文本分类任务,将其转变成填空任务,还有就是构建个映射器(verbalizer)可以在label和word之间相互映射,verbalizer是人工精妙设计的且用梯度下降学习的。论文提到verbalizer可能缺少覆盖度且引入很高的偏差和方差,所以论文提出引入额外知识到verbalizer里,构建一个Knowledgable Prompt-tuning(KPT)去提升效果。Finetuning虽然效果很好,但是也需要充足的样本去重新训练网络,在模型tuning领域,有很多prompts的研究在预训练目标和下游任务构建了桥梁。论文给了个很好的例子:
句子x: What's the relation between speed and acceleration?
category: SCIENCE
模板: A [MASK] question: x
预估结果基于[MASK]所填word的概率,如果[MASK]填science概率比较高,那verbalizer的作用就是把science映射到真正的类别SCIENCE上。verbalizer就是构建vocabulary和label之间的桥梁。
现存很多工作都是人工制定verbalizer的,人工指定verbalizer就有很多问题,比如上述例子只把science映射成SCIENCE类,就很多限制,因为physics和maths同样可以映射到SCIENCE,因此这种人工one-one映射限制了模型的收敛,同时预估也会有问题,也容易在verbalizer中引入偏差。还有很多工作尝试缓解人工verbalizer的缺陷,用梯度下降寻找最好的verbalizer,然而这样的方法很难推断science和physics之间的联系。如果我们能把{science, physics}->SCIENCE这种信息直接注入到verbalizer,预估的效果就会显著提升,这就是KPT做的事。


KPT概述
KPT有3步
construction stage
用external KBs为每个label创建一系列的label words。值得注意的是扩展label words不仅仅是找同义词,而是从各种粒度视角。
refinement stage
用PLM本身去给扩展的label words降噪。对于zero-shot的效果,该文提出了contextualized calibration去删除一些先验概率较低的words。对于few-shot learning,该文又提出了一个可学习的权重用于verbalizer的降噪。
utilization stage
最后用个average loss function去优化expanded verbalizers,把对一系列label words的打分映射到真正标签的打分上。
整体框架如下图:
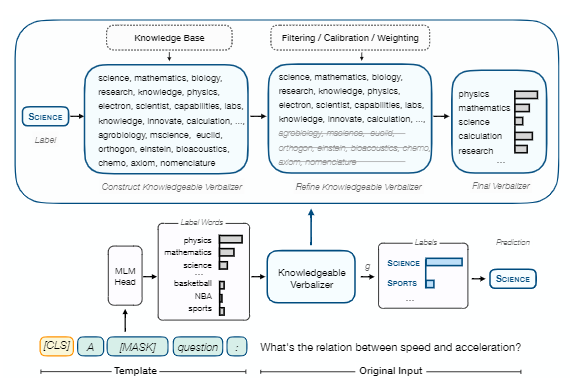
该文的重点就是构建一个优秀的融合各种外在知识的verbalizer。verbalizer就是把vocabulary中的少数词的概率,映射到label的概率,label words的集合是V,label空间是Y,Vy表示标签y的label words集合,是V的子集,最终预估y的概率就是下式,g就是把label words的概率转成label的概率:
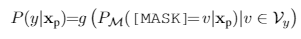
KPT Method
基于上下文预估masked的word并不是一个单选问题,是没有标准答案的,所以verbalizer必须有两个特性,广覆盖和少主观偏差。幸运的是external structured knowledge在主题分类和情感分类会同时满足这两个特性。对于主题分类而言,核心就是要从各个角度找到与topic相关的label words,论文选了个知识图谱作为外部信息(external KB),该图谱可以用来衡量label words和topic直接的相关性,用此选出与topic最相关的label words集合,如下表所示:

尽管用了个知识图谱构建了一个verbalizer,但是这个verbalizer是充满噪声的,因为PLM可能根本不认可,所以需要refinement的过程。对于zero-shot learning,有3个问题需要解决。首先就是OOV问题,PLM没见过KB推荐的词咋办呢?这些词可能有很多类目的信息,处理这个问题,可以简单的把没见过的词mask后预估应该填的词的平均概率,作为这个词的概率。第二个问题是处理一些长尾词汇,PLM预估长尾词汇的概率往往是不准确的。该文提出用contextualized calibration去删除一些先验概率较低的words,具体是我们可以计算label words的概率期望:
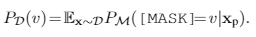
我们从训练集采样一批样本然后mask掉word v并近似计算其期望:
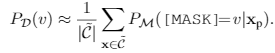
如果这个值小于一个阈值就删除。
第三个问题就是有些label words和其他相比,很难被预估个比较高的score,所以KB中的label words的概率需要被修正,用下公式:
对于Few-shot learning,处理起来就相对简单了,给每个label words使用一个可学习的wv,最终weight归一化后如下:
最后就是优化的目标了,一种是averge的方式,一种是加权,如下所示:
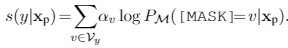
实验
实验效果如图所示:
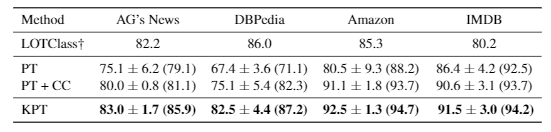
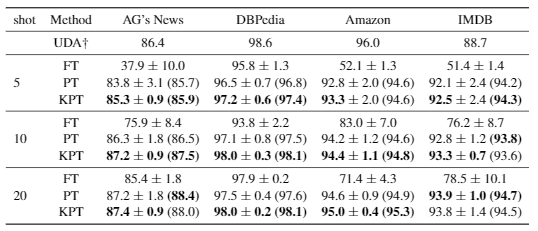
参考文献
1 KnowLedgeble Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification
https://arxiv.org/pdf/2108.02035.pdf
往期精彩回顾 本站qq群955171419,加入微信群请扫码: