
领域驱动设计(DDD)能给前端带来什么
感谢大家还没取关我,毕竟这么久没更新 最近在建设投资体系,这跟知识体系一样是个系统工程,大家感兴趣的话后续可以聊下这个话题。然后读书系列会继续进行下去~
最近在建设投资体系,这跟知识体系一样是个系统工程,大家感兴趣的话后续可以聊下这个话题。然后读书系列会继续进行下去~
为什么需要DDD
在回答这个问题之前,我们先看下大部分软件都会经历的发展过程:频繁的变更带来软件质量的下降
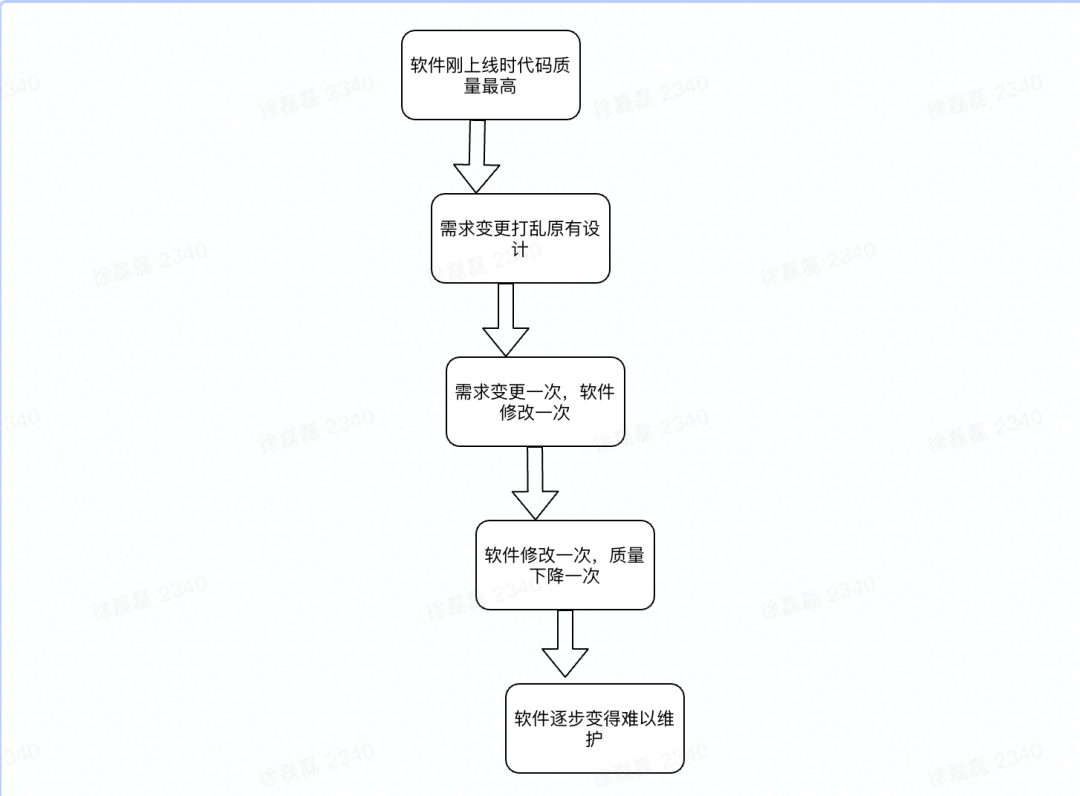
而这又是软件发展的规律导致的:
软件是对真实世界的模拟,真实世界往往十分复杂
人在认识真实世界的时候总有一个从简单到复杂的过程
因此需求的变更是一种必然,并且总是由简单到复杂演变
软件初期的业务逻辑非常清晰明了,慢慢变得越来越复杂
可以看到需求的不断变更和迭代导致了项目变得越来越复杂,那么问题来了,项目复杂性提高的根本原因是需求变更引起的吗?
根本原因其实是因为在需求变更过程中没有及时的进行解耦和扩展。

那么在需求变更的过程中如何进行解耦和扩展呢?DDD发挥作用的时候来了。
什么是DDD
DDD(领域驱动设计)的概念见维基百科:
https://zh.wikipedia.org/wiki/%E9%A0%98%E5%9F%9F%E9%A9%85%E5%8B%95%E8%A8%AD%E8%A8%88
可以看到领域驱动设计(domin-driven design)不同于传统的针对数据库表结构的设计,领域模型驱动设计自然是以提炼和转换业务需求中的领域知识为设计的起点。在提炼领域知识时,没有数据库的概念,亦没有服务的概念,一切围绕着业务需求而来,即:
现实世界有什么事物 -> 模型中就有什么对象
现实世界有什么行为 -> 模型中就有什么方法
现实世界有什么关系 -> 模型中就有什么关联
在DDD中按照什么样的原则进行领域建模呢?
单一职责原则(Single responsibility principle)即SRP:软件系统中每个元素只完成自己职责内的事,将其他的事交给别人去做。
上面这句话有没有什么哪里不清晰的?有,那就是“职责”两个字。职责该怎么理解?如何限定该元素的职责范围呢?这就引出了“限界上下文”的概念。
Eric Evans 用细胞来形容限界上下文,因为“细胞之所以能够存在,是因为细胞膜限定了什么在细胞内,什么在细胞外,并且确定了什么物质可以通过细胞膜。”这里,细胞代表上下文,而细胞膜代表了包裹上下文的边界。
我们需要根据业务相关性、耦合的强弱程度、分离的关注点对这些活动进行归类,找到不同类别之间存在的边界,这就是限界上下文的含义。上下文(Context)是业务目标,限界(Bounded)则是保护和隔离上下文的边界,避免业务目标的不单一而带来的混乱与概念的不一致。
如何DDD
DDD的大体流程如下:
建立统一语言
统一语言是提炼领域知识的产出物,获得统一语言就是需求分析的过程,也是团队中各个角色就系统目标、范围与具体功能达成一致的过程。
使用统一语言可以帮助我们将参与讨论的客户、领域专家与开发团队拉到同一个维度空间进行讨论,若没有达成这种一致性,那就是鸡同鸭讲,毫无沟通效率,相反还可能造成误解。因此,在沟通需求时,团队中的每个人都应使用统一语言进行交流。
一旦确定了统一语言,无论是与领域专家的讨论,还是最终的实现代码,都可以通过使用相同的术语,清晰准确地定义领域知识。重要的是,当我们建立了符合整个团队皆认同的一套统一语言后,就可以在此基础上寻找正确的领域概念,为建立领域模型提供重要参考。
举个例子,不同玩家对于英雄联盟(league of legends)的称呼不尽相同;国外玩家一般叫“League”,国内玩家有的称呼“撸啊撸”,有的称呼“LOL”等等。那么如果要开发相关产品,开发人员和客户首先需要统一对“英雄联盟”的语言模型。
事件风暴(Event Storming)
事件风暴会议是一种基于工作坊的实践方法,它可以快速发现业务领域中正在发生的事件,指导领域建模及程序开发。它是Alberto Brandolini发明的一种领域驱动设计实践方法,被广泛应用于业务流程建模和需求工程,基本思想是将软件开发人员和领域专家聚集在一起,相互学习,类似头脑风暴。
会议一般以探讨领域事件开始,从前向后梳理,以确保所有的领域事件都能被覆盖。
什么是领域事件呢?
领域事件是领域模型中非常重要的一部分,用来表示领域中发生的事件。一个领域事件将导致进一步的业务操作,在实现业务解耦的同时,还有助于形成完整的业务闭环。
领域事件可以是业务流程的一个步骤,比如投保业务缴费完成后,触发投保单转保单的动作;也可能是定时批处理过程中发生的事件,比如批处理生成季缴保费通知单,触发发送缴费邮件通知操作;或者一个事件发生后触发的后续动作,比如密码连续输错三次,触发锁定账户的动作。
进行领域建模,将各个模型分配到各个限界上下文中,构建上下文地图。
领域建模时,我们会根据场景分析过程中产生的领域对象,比如命令、事件等之间关系,找出产生命令的实体,分析实体之间的依赖关系组成聚合,为聚合划定限界上下文,建立领域模型以及模型之间的依赖。
上面我们大体了解了DDD的作用,概念和一般的流程,虽然前端和后端的DDD不尽相同,但是我们仍然可以将这种思想应用于我们的项目中。
DDD能给前端项目带来什么
通过领域模型 (feature)组织项目结构,降低耦合度
很多通过react脚手架生成的项目组织结构是这样的:
-componentscomponent1component2-actions.ts...allActions-reducers.ts...allReducers
首先从功能角度对项目进行拆分。将业务逻辑拆分成高内聚松耦合的模块。从而对 feature 进行新增,重构,删除,重命名等变得简单 ,不会影响到其他的feature,使项目可扩展和可维护。 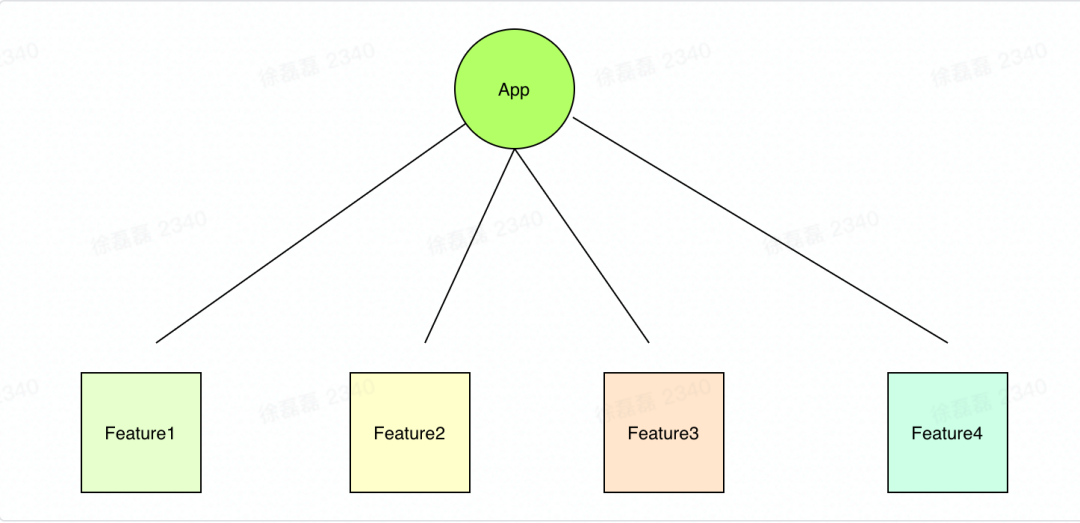
再从技术角度进行拆分,可以看到componet, routing,reducer 都来自等多个功能模块
技术上的代码按照功能的方式组织在feature下面,而不是单纯通过技术角度进行区分。 通常是由一个文件来管理所有的路由,随着项目的迭代,这个路由文件也会变得复杂。那么可以把路由分散在feature中,由每个feature 来管理自己的路由。
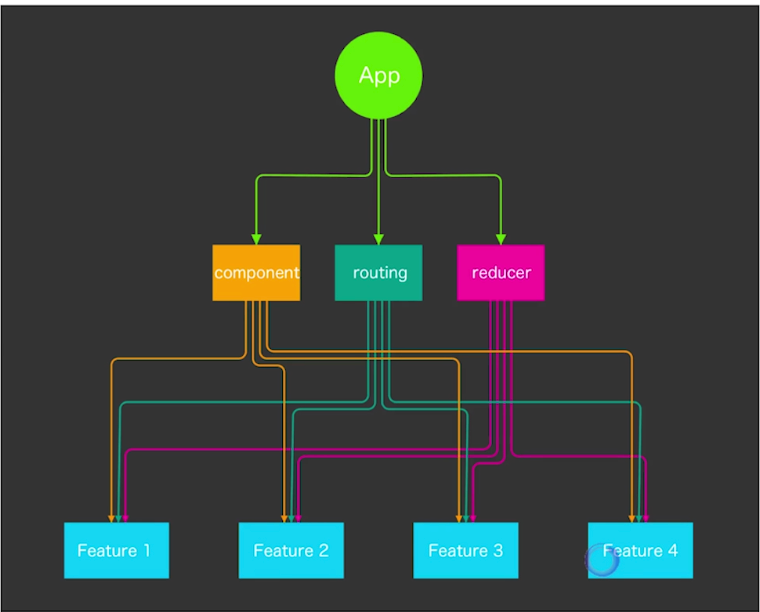
如何组织 componet,action,reducer
按feature组织组件,action 和 reducer 组件和样式文件在同一级 Redux放在单独的文件
每个feature下面分为 redux文件夹 和 组件文件

redux文件夹下面的 action.js 只是充当loader的作用,负责将各个action引入,而没有具体的逻辑。reducer 同理
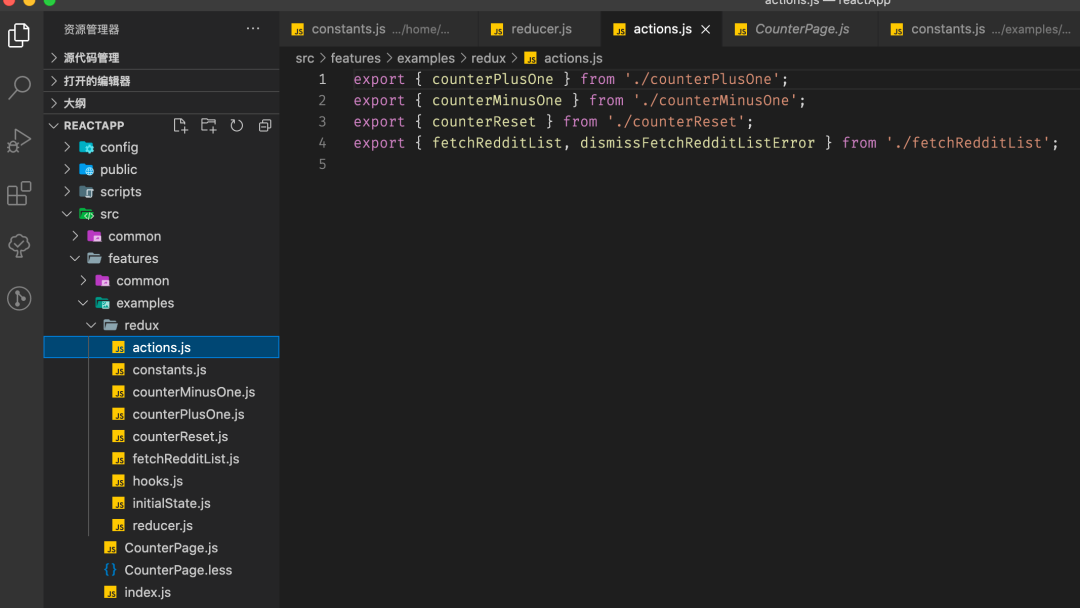
项目的根节点还需要一个 root loader 来加载 feature 下的资源

如何组织 router
每个feature都有自己专属的路由配置 顶层路由(页面级别的路由)通过JSON配置1,然后解析JSON到React Router
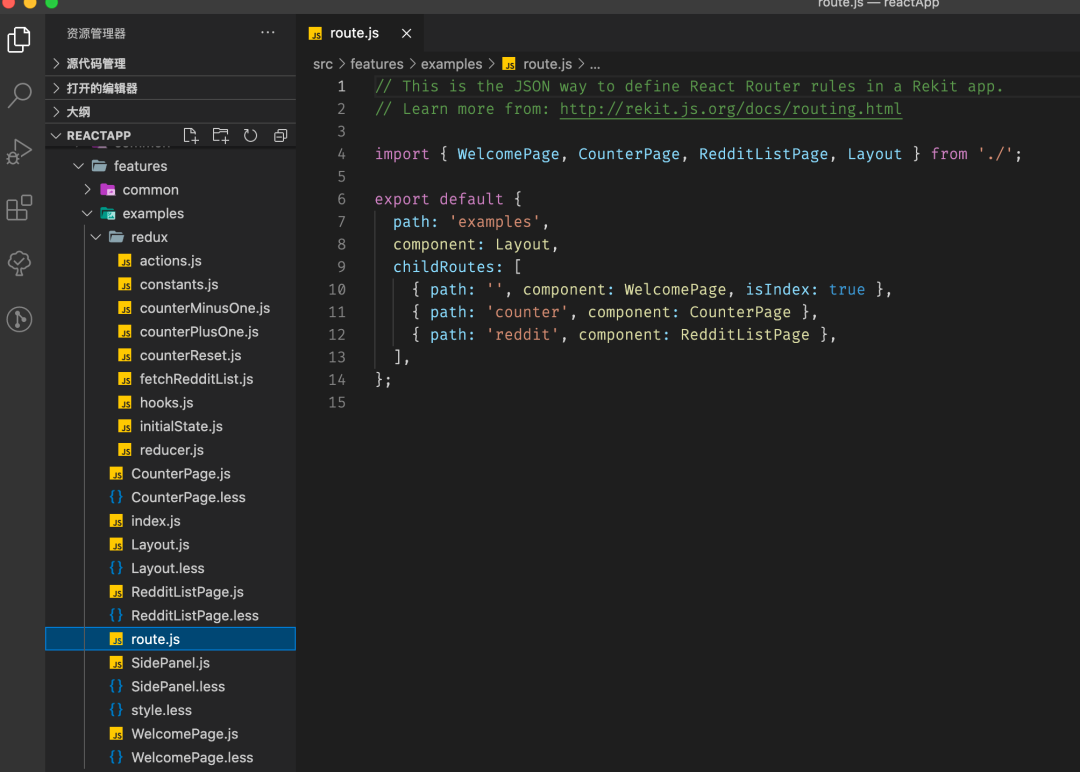

import { App } from '../features/home';import { PageNotFound } from '../features/common';import homeRoute from '../features/home/route';import commonRoute from '../features/common/route';import examplesRoute from '../features/examples/route';const childRoutes = [homeRoute,commonRoute,examplesRoute,];const routes = [{path: '/',componet: App,childRoutes: [... childRoutes,{ path:'*', name: 'Page not found', component: PageNotFound },].filter( r => r.componet || (r.childRoutes && r.childRoutes.length > 0))}]export default routes
import React from 'react';import { Switch, Route } from 'react-router-dom';import { ConnectedRouter } from 'connected-react-router';import routeConfig from './common/routeConfig';function renderRouteConfig(routes, path) {const children = [] // children component listconst renderRoute = (item, routeContextPath) => {let newContextPath;if (/^\//.test(item.path)) {newContextPath = item.path;} else {newContextPath = `${routeContextPath}/${item.path}`;}newContextPath = newContextPath.replace(/\/+/g, '/');if (item.component && item.childRoutes) {const childRoutes = renderRouteConfigV3(item.childRoutes, newContextPath);children.push(<Routekey={newContextPath}render={props => <item.component {...props}>{childRoutes}</item.component>}path={newContextPath}/>,);} else if (item.component) {children.push(<Route key={newContextPath} component={item.component} path={newContextPath} exact />,);} else if (item.childRoutes) {item.childRoutes.forEach(r => renderRoute(r, newContextPath));}};routes.forEach(item => renderRoute(item,path))return <Switch>children</Switch>}function Root() {const children = renderRouteConfig(routeConfig, '/');return (<ConnectedRouter>{children}</ConnectedRouter>);}