
Apache Hudi:说出来你可能不信,你的ETL任务慢如狗
共 9571字,需浏览 20分钟
·
2020-08-24 18:36
点击上方蓝色字体,选择“设为星标”





1.简介
Update/Delete记录:Hudi使用细粒度的文件/记录级别索引来支持Update/Delete记录,同时还提供写操作的事务保证。查询会处理最后一个提交的快照,并基于此输出结果。
变更流:Hudi对获取数据变更提供了一流的支持:可以从给定的时间点获取给定表中已updated/inserted/deleted的所有记录的增量流,并解锁新的查询姿势(类别)。
2. 基本概念
写时复制(copy on write):仅使用列式文件(parquet)存储数据。在写入/更新数据时,直接同步合并原文件,生成新版本的基文件(需要重写整个列数据文件,即使只有一个字节的新数据被提交)。此存储类型下,写入数据非常昂贵,而读取的成本没有增加,所以适合频繁读的工作负载,因为数据集的最新版本在列式文件中始终可用,以进行高效的查询。
读时合并(merge on read):使用列式(parquet)与行式(avro)文件组合,进行数据存储。在更新记录时,更新到增量文件中(avro),然后进行异步(或同步)的compaction,创建列式文件(parquet)的新版本。此存储类型适合频繁写的工作负载,因为新记录是以appending 的模式写入增量文件中。但是在读取数据集时,需要将增量文件与旧文件进行合并,生成列式文件。
读优化视图(Read Optimized view):直接query 基文件(数据集的最新快照),也就是列式文件(如parquet)。相较于非Hudi列式数据集,有相同的列式查询性能
增量视图(Incremental View):仅query新写入数据集的文件,也就是指定一个commit/compaction,query此之后的新数据。
实时视图(Real-time View):query最新基文件与增量文件。此视图通过将最新的基文件(parquet)与增量文件(avro)进行动态合并,然后进行query。可以提供近实时的数据(会有几分钟的延迟)

1.近实时摄取
2. 近实时分析
3. 增量处理管道
4. DFS上数据分发
1、编译
cd incubator-hudi-hoodie-0.4.7mvn clean install -DskipITs -DskipTests -Dhadoop.version=2.6.0-cdh5.13.0 -Dhive.version=1.1.0-cdh5.13.0
2、快速开始
1、新建项目
<properties><scala.version>2.11scala.version><spark.version>2.4.0spark.version><parquet.version>1.10.1parquet.version><parquet-format-structures.version>1.10.1-palantir.3-2-gda7f810parquet-format-structures.version><hudi.version>0.4.7hudi.version>properties><repositories><repository><id>clouderaid><url>https://repository.cloudera.com/artifactory/cloudera-repos/url>repository>repositories><dependencies><dependency><groupId>org.apache.sparkgroupId><artifactId>spark-core_${scala.version}artifactId><version>${spark.version}version>dependency><dependency><groupId>org.apache.sparkgroupId><artifactId>spark-sql_${scala.version}artifactId><version>${spark.version}version><exclusions><exclusion><artifactId>parquet-columnartifactId><groupId>org.apache.parquetgroupId>exclusion>exclusions>dependency><dependency><groupId>org.apache.sparkgroupId><artifactId>spark-hive_${scala.version}artifactId><version>${spark.version}version>dependency><dependency><groupId>com.databricksgroupId><artifactId>spark-avro_${scala.version}artifactId><version>4.0.0version>dependency><dependency><groupId>com.uber.hoodiegroupId><artifactId>hoodie-commonartifactId><version>${hudi.version}version>dependency><dependency><groupId>com.uber.hoodiegroupId><artifactId>hoodie-hadoop-mrartifactId><version>${hudi.version}version>dependency><dependency><groupId>com.uber.hoodiegroupId><artifactId>hoodie-sparkartifactId><version>${hudi.version}version>dependency><dependency><groupId>com.uber.hoodiegroupId><artifactId>hoodie-hiveartifactId><version>${hudi.version}version>dependency><dependency><groupId>com.uber.hoodiegroupId><artifactId>hoodie-clientartifactId><version>${hudi.version}version>dependency><dependency><groupId>org.apache.avrogroupId><artifactId>avroartifactId><version>1.7.7version>dependency><dependency><groupId>org.apache.parquetgroupId><artifactId>parquet-avroartifactId><version>${parquet.version}version><exclusions><exclusion><artifactId>parquet-columnartifactId><groupId>org.apache.parquetgroupId>exclusion>exclusions>dependency><dependency><groupId>org.apache.parquetgroupId><artifactId>parquet-hadoopartifactId><version>${parquet.version}version><exclusions><exclusion><artifactId>parquet-columnartifactId><groupId>org.apache.parquetgroupId>exclusion>exclusions>dependency><dependency><groupId>org.apache.sparkgroupId><artifactId>spark-streaming_${scala.version}artifactId><version>${spark.version}version>dependency><dependency><groupId>org.apache.sparkgroupId><artifactId>spark-streaming-kafka-0-10_${scala.version}artifactId><version>${spark.version}version>dependency><dependency><groupId>org.apache.sparkgroupId><artifactId>spark-sql-kafka-0-10_${scala.version}artifactId><version>${spark.version}version>dependency><dependency><groupId>com.alibabagroupId><artifactId>fastjsonartifactId><version>1.2.62version>dependency><dependency><groupId>org.apache.hivegroupId><artifactId>hive-jdbcartifactId><version>1.1.0-cdh5.13.0version>dependency>dependencies>
2、插入数据
{"id":1,"name": "aaa","age": 10}{"id":2,"name": "bbb","age": 11}{"id":3,"name": "ccc","age": 12}{"id":4,"name": "ddd","age": 13}{"id":5,"name": "eee","age": 14}{"id":6,"name": "fff","age": 15}
val spark = SparkSession.builder.master("local").appName("Demo2").config("spark.serializer", "org.apache.spark.serializer.KryoSerializer").enableHiveSupport().getOrCreate
读取刚才保存的json文件:
val jsonData = spark.read.json("file:///Users/apple/Documents/project/study/hudi-study/source_data/insert.json")
import com.uber.hoodie.config.HoodieWriteConfig._val tableName = "test_data"val basePath = "file:///Users/apple/Documents/project/study/hudi-study/hudi_data/" + tableNamejsonData.write.format("com.uber.hoodie").option("hoodie.upsert.shuffle.parallelism", "1").option(PRECOMBINE_FIELD_OPT_KEY, "id").option(RECORDKEY_FIELD_OPT_KEY, "id").option(KEYGENERATOR_CLASS_OPT_KEY, "com.mbp.study.DayKeyGenerator").option(TABLE_NAME, tableName).mode(SaveMode.Overwrite).save(basePath)
3、查询数据
val jsonDataDf = spark.read.format("com.uber.hoodie").load(basePath + "/*/*")jsonDataDf.show(false)
4、更新数据
{"id":1,"name": "aaa","age": 20,"address": "a1"}{"id":2,"name": "bbb","age": 21,"address": "a1"}{"id":3,"name": "ccc","age": 22,"address": "a1"}
val updateJsonf = spark.read.json("/Users/apple/Documents/project/study/hudi-study/source_data/update.json")updateJsonf.write.format("com.uber.hoodie").option("hoodie.insert.shuffle.parallelism", "2").option("hoodie.upsert.shuffle.parallelism", "2").option(PRECOMBINE_FIELD_OPT_KEY, "id").option(RECORDKEY_FIELD_OPT_KEY, "id").option(TABLE_NAME, tableName).mode(SaveMode.Append).save(basePath)
5、增量查询
val commits = spark.sql("select distinct(_hoodie_commit_time) as commitTime from hudi_ro_table order by commitTime").map(k => k.getString(0)).take(50)val beginTime = commits(commits.length - 2) // commit time we are interested in// 增量查询数据val incViewDF = spark.read.format("org.apache.hudi").option(VIEW_TYPE_OPT_KEY, VIEW_TYPE_INCREMENTAL_OPT_VAL).option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).load(basePath);incViewDF.registerTempTable("hudi_incr_table")spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_incr_table where fare > 20.0").show()
6、特定时间点查询
val beginTime = "000" // Represents all commits > this time.val endTime = commits(commits.length - 2) // commit time we are interested in// 增量查询数据val incViewDF = spark.read.format("org.apache.hudi").option(VIEW_TYPE_OPT_KEY, VIEW_TYPE_INCREMENTAL_OPT_VAL).option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).option(END_INSTANTTIME_OPT_KEY, endTime).load(basePath);incViewDF.registerTempTable("hudi_incr_table")spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_incr_table where fare > 20.0").show()
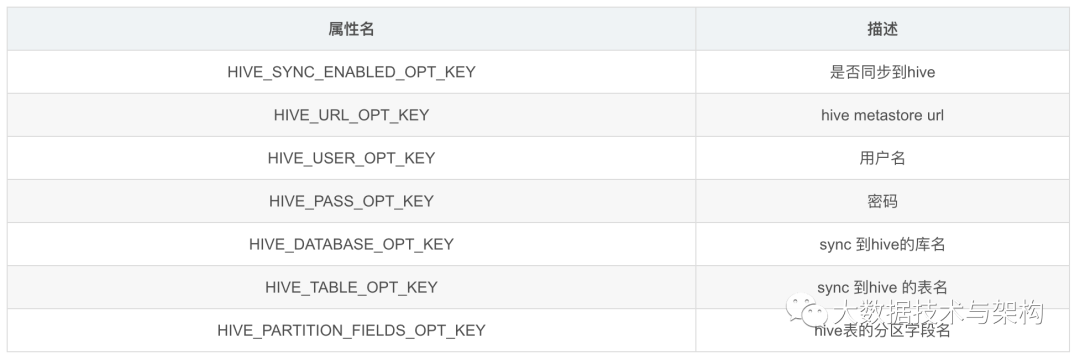
7、同步到Hive
1、写数据的时候设置同步hive
jsonData.write.format("com.uber.hoodie").option("hoodie.upsert.shuffle.parallelism", "1").option(HIVE_PARTITION_FIELDS_OPT_KEY, "etl_tx_dt").option(HIVE_URL_OPT_KEY, "jdbc:hive2://xxx.xxx.xxx.xxx:10000").option(HIVE_USER_OPT_KEY, "hive").option(HIVE_PASS_OPT_KEY, "123").option(HIVE_DATABASE_OPT_KEY, "test").option(HIVE_SYNC_ENABLED_OPT_KEY, true).option(HIVE_TABLE_OPT_KEY, tableName).option(PRECOMBINE_FIELD_OPT_KEY, "id").option(RECORDKEY_FIELD_OPT_KEY, "id").option(TABLE_NAME, tableName).mode(SaveMode.Append).save(basePath)
hoodie-hadoop-mr-0.4.7.jarhoodie-common-0.4.7.jar


版权声明:
文章不错?点个【在看】吧! ?