
【Java并发编程】面试必备之线程池
Python实战社群
Java实战社群
长按识别下方二维码,按需求添加
扫码关注添加客服
进Python社群▲
扫码关注添加客服
进Java社群▲
什么是线程池
是一种基于池化思想管理线程的工具。池化技术:池化技术简单点来说,就是提前保存大量的资源,以备不时之需。比如我们的对象池,数据库连接池等。
线程池好处
我们为什么要使用线程池,直接new thread start不好吗?
「降低资源消耗」: 通过重复利用已创建的线程来降低线程创建和销毁所造成的消耗。 「提高响应速度:」 任务到达时,可以立即执行,不需要等到线程创建再来执行任务。 「提高线程的可管理性:」 线程是稀缺资源,如果无限制创建,不仅会消耗系统资源,还会因为线程的不合理分布导致资源调度失衡,降低系统的稳定性。使用线程池可以进行统一的分配、调优和监控。
线程池的执行流程
我们先来看看线程池的一个执行流程图,此图来自文末参考1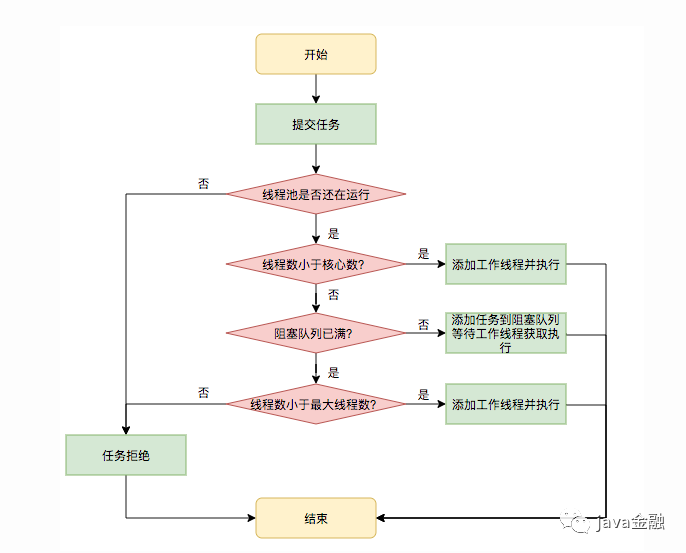
通过上述图我们可以得出线程池执行任务可以有以下几种情况:
如果当前的运行线程小于 coreSize,则创建新线程来执行任务。如果当前运行的线程等于 coreSize或多余coreSize(动态修改了coreSize才会出现这种情况),把任务放到阻塞队列中。如果队列已满无法将新加入的任务放进去的话,则需要创建新的线程来执行任务。 如果新创建线程已经达到了最大线程数,任务将会被拒绝。
怎么用线程池
在java jdk的Executors有提供创建不同线程池的方法(一般不推荐这种做法)阿里巴巴的开发手册也明确强制规定不让通过Executors来创建的,在一些公司的开发规范里面应该也会有这么一条吧。
newFixedThreadPool newSingleThreadExecutor newCachedThreadPool newScheduledThreadPool newWorkStealingPool (jdk1.8新增的) 我们可以使用ThreadPoolExecutor来创建线程池
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
我们可以看出创建线程池有七个参数,而上述我们通过Executors工具类来创建的线程池就一两个参数,其他参数它都帮我们默认写死了,我们只有真正理解了这几个参数才能更好的去使用线程池。下面我们来看看这七个参数(线程池参数)。
corePoolSize
核心线程数(线程池的基本大小)当我们提交一个任务到线程池时就会创建一个线程来执行任务.当我们需要执行的任务数大于核心线程数了就不再创建, 如果我们调用了 prestartAllCoreThreads()方法线程池就会为我们提前创建好所有的基本线程。
maximumPoolSize
最大线程数:线程池允许创建的最大线程数。如果队列已经满了,且已创建的线程数小于最大线程数,则线程池就会创建新的线程来执行任务。这里有个小知识点,如果我们的队列是用的无界队列,这个参数是不会起作用的,因为我们的任务会一直往队列中加,队列永远不会满(内存允许的情况)。
keepAliveTime
空闲线程最大生存时间。当前线程数大于核心线程数时,结束多余的空闲线程等待新任务的最长时间。默认情况下,只有当线程池中的线程数大于 corePoolSize时,keepAliveTime才会起作用,直到线程池中的线程数不大于corePoolSize,即当线程池中的线程数大于corePoolSize时,如果一个线程空闲的时间达到keepAliveTime,则会终止,直到线程池中的线程数不超过corePoolSize。但是如果调用了allowCoreThreadTimeOut(boolean)方法,在线程池中的线程数不大于corePoolSize时,keepAliveTime参数也会起作用,直到线程池中的线程数为0;比如当前线程池中最大线程数(maximumPoolSize)为50,核心线程数(corePoolSize)为10,当前正在跑任务的线程数为30.然后是不是空出了20个线程没活干,所以这20个线程就要被消毁,有点卸磨杀驴的感觉。如果剩下的30个线程干完活了也休息了keepAliveTime这么久,然后这30个线程里面也要被销毁20个,就保留个核心线程。如果设置了allowCoreThreadTimeOut等于true核心线程也会被销毁。就跟我们做外包项目一样,甲方项目完成了就得去另外一个甲方,如果短时间内都没有甲方接纳你的话,你就要被辞退了,只会留下几个核心人员维护下项目,如果甲方项目维护的话用自己的人的话,所有的外包人会都会被辞退。
unit
线程存活时间的的单位。可选的单位有 days、hours等。
workQueue
任务队列。可以选择以下这些队列
threadFactory
用户设置创建线程的工厂,我们可以通过这个工厂来创建有业务意义的线程名字。我们可以对比下自定义的线程工厂和默认的线程工厂创建的名字。
| 默认产生线程的名字 | 自定义线程工厂产生名字 |
|---|---|
| pool-5-thread-1 | testPool-1-thread-1 |
阿里开发手册也有明确说到,需要指定有意义的线程名字。
RejectedExecutionHandler
线程池拒绝策略。当队列和线程池都满了说明线程池已经处于饱和状态。必须要采取一定的策略来处理新提交的任务。jdk默认提供了四种拒绝策略: 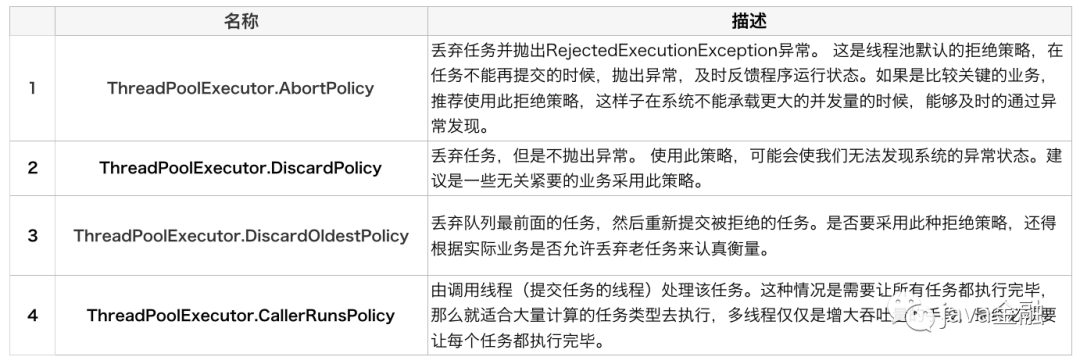 其实我们也可以自定义任务拒绝策略(实现下
其实我们也可以自定义任务拒绝策略(实现下RejectedExecutionHandler接口),比如说如果任务拒绝了我们可以记录下日志,或者重试等,根据自己的业务需求来实现。dubbo任务拒绝策略
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
String msg = String.format("Thread pool is EXHAUSTED!" +
" Thread Name: %s, Pool Size: %d (active: %d, core: %d, max: %d, largest: %d), Task: %d (completed: "
+ "%d)," +
" Executor status:(isShutdown:%s, isTerminated:%s, isTerminating:%s), in %s://%s:%d!",
threadName, e.getPoolSize(), e.getActiveCount(), e.getCorePoolSize(), e.getMaximumPoolSize(),
e.getLargestPoolSize(),
e.getTaskCount(), e.getCompletedTaskCount(), e.isShutdown(), e.isTerminated(), e.isTerminating(),
url.getProtocol(), url.getIp(), url.getPort());
logger.warn(msg);
dumpJStack();
dispatchThreadPoolExhaustedEvent(msg);
throw new RejectedExecutionException(msg);
}
我们可以看出dubbo的拒绝策略主要记录了详细的级别为warm的日志、输出当前线程堆栈详情、继续抛出拒绝任务异常。
线程池参数如何设置?
线程池既然有这么多参数那么我们如何去根据自己的业务实际情况来去合理的设置每个参数?
一般我们如果任务为耗时 IO型比如读取数据库、文件读写以及网略通信的的话这些任务不会占据很多cpu的资源但是会比较耗时:线程数设置为2倍CPU数以上,充分的来利用CPU资源。一般我们如果任务为CPU密集型的话比如大量计算、解压、压缩等这些操作都会占据大量的cpu。所以针对于这种情况的话一般设置线程数为:1倍cpu+1。为啥要加1,很多说法是备份线程。 如果既有IO密集型任务,又有 CPU密集型任务,这种该怎么设置线程大小?这种的话最好分开用线程池处理,IO密集的用IO密集型线程池处理,CPU密集型的用cpu密集型处理。以上都只是理算情况下的估算而已,真正的合理参数还是需要看看实际生产运行的效果来合理的调整的。
监控线程池
线程池工作是否饱和?线程的情况如何?总共执行了多少个任务?现在线程池的运行情况如何?队列里面是否有堆积任务?面对上面这些问题,线程池也有提供一些方法可以让我们来查看上面这些指标。 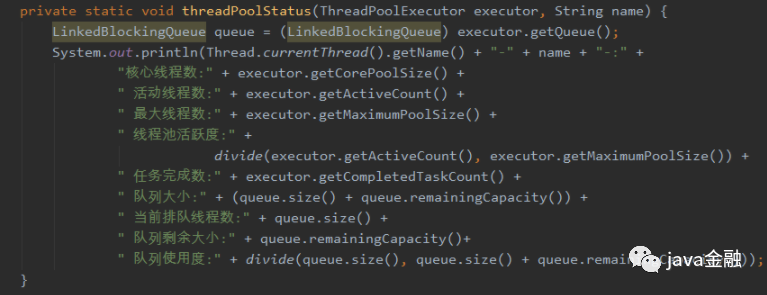 有了这些参数我们是不是调整线程池的参数就更加方便了。或者根据线程池的活跃程度我们自动来调节(动态调整下篇再来说)线程池的参数。
有了这些参数我们是不是调整线程池的参数就更加方便了。或者根据线程池的活跃程度我们自动来调节(动态调整下篇再来说)线程池的参数。
关于线程池的几个问题
线程池是否区分核心线程和非核心线程? 如何保证核心线程不被销毁? 线程池的线程是如何做到复用的?以上几个小问题我们去看看线程池的源码,这几个问题应该就不成问题了,我们下篇见。 巨人肩膀摘苹果 https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html 《java并发编程实战》


近期精彩内容推荐:


评论