
他们用AI挖开了一座古人留下的宝藏


 陈力
陈力


后来虽然也出现了“技术派”,用计算机来自动识别图片里的文字,但由于准确率堪忧,没有普遍使用。大家都是各做各的,所以并没有形成统一的平台和开放给所有人的通用工具。









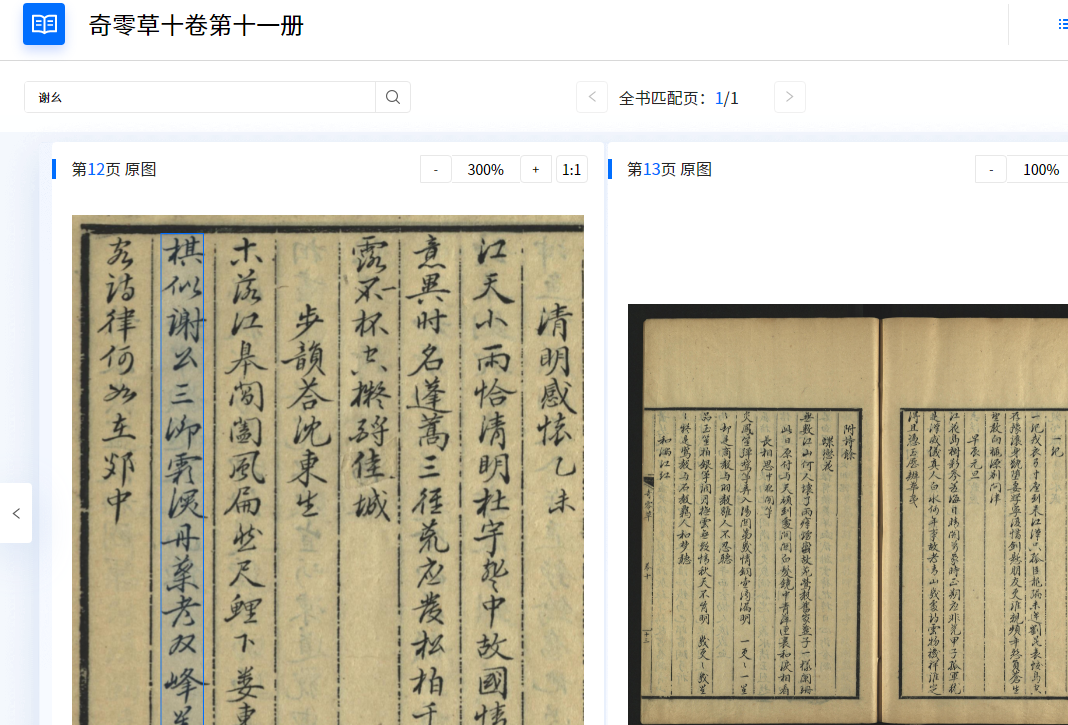

未来,它可以迎回更多流失在海外的古籍,科技和古籍也可以碰撞出更多的火花,让更多原本只放在书架上的古籍活起来,流动起来,为人所用。

最后再介绍一下我自己吧,我是谢幺,科技科普作者一枚,日常是把各路技术讲得通俗有趣。想跟我做朋友,可以加我的个人微信:xieyaopro。不想走丢的话,请关注【浅黑科技】!(别忘了加星标哦)
评论