
MySQL高频面试题,硬gang面试官
点击上方蓝色“小哈学Java”,选择“设为星标” 回复“资源”获取独家整理的学习资料!

MySQL 索引使用什么数据结构?为什么用 B+做索引?
使用B+树。
这个问题,可以在脑子里面先思考一下,如果让你来设计数据库的索引,你会怎么设计?
我们还是用Why?What?How?三步法来看这个问题。
为什么会需要索引?索引是什么?索引怎么用的?
再思考为什么需要B+树?B+树是什么?B+树怎么用?
答:大部分程序主要的功能都是对数据的处理,写入、查询、转化、输出。最形象的比喻就是树和内容和目录的关系,目录就是索引,我们根据目录能快速拿到想要内容的页码。
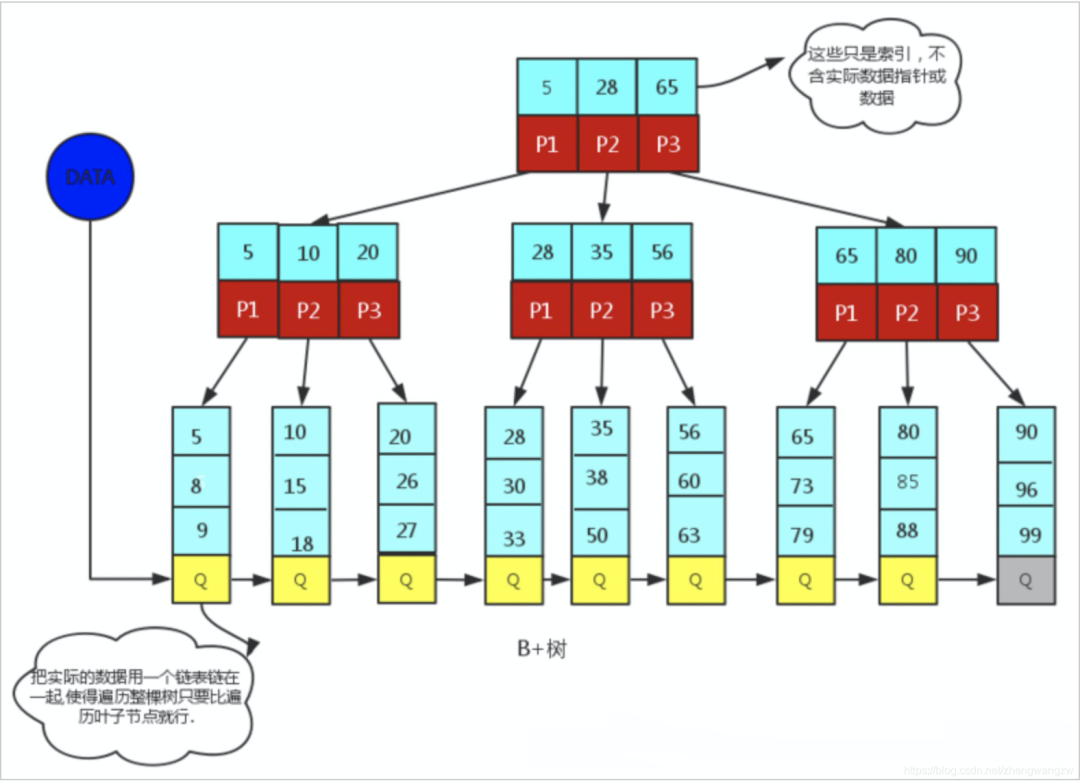
为什么是B+树,有这个几个理由:
如果是用AVL平衡二叉树,树高度太高,索引查询需要访问磁盘,每次访问以节点为单位进行磁盘I/O ,需要尽量减少数据读取的I/O操作,所以树高度一定不能太高,存储千万级别的数据,实践中 B+ 树的高度也就 4或者5。 B+树经常用来比较的是B树,B+树相比B树有个很大的特点是B+树所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的,对于范围查找,比如15~50,B树需要中序遍历二叉树,但是B+树直接在叶子节点顺序访问就可以了。
什么是最左匹配原则?
首先说明一点:
最左前缀匹配原则:在MySQL建立联合索引时会遵守最左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。
打个比方,我们有张student 表,我们根据学院编号+班级建立了一个联合索引 index_magor_class(magor,class), 这个索引由二个字段组成。
索引的底层是一颗B+树,那么联合索引的底层也就是一颗B+树,只不过联合索引的B+树节点中存储的是逗号分隔的多个值。
举例:创建一个 index_magor_class(magor,class) 的联合索引,那么它的索引树就是下图的样子。
它是先根据magor排序,再根据class排序,如果索引后面还有字段,继续以此类推。
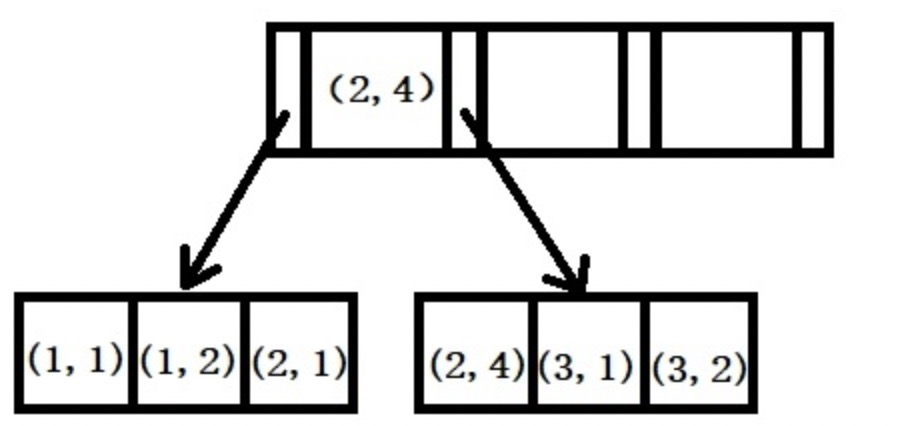
我们查询的where 条件如果只传入了班级,是走不到联合索引的,但是如果只传了学院编号,是可能会走到联合索引的。(为什么说可能,MYSQL的执行计划和查询的实际执行过程并不完全吻合,比如你数据库数据量很少,可能直接全量遍历速度更快,就不走索引了)
在建表的时候如何设计索引的?有没有做过索引优化 ?
1、利用覆盖索引来进行查询操作,来避免回表操作。
说明:如果一本书需要知道第11章是什么标题,会翻开第11章对应的那一页吗?目录浏览一下就好,这个目录就是起到覆盖索引的作用。
什么意思,比如你主键索引是学号,你写select 语句的时候,直接select 学号 from table 就可以了,不用select 其他字段,一般除非非常有必要,尽量按需select 字段,少用或不用 select, 不然还需要回表。
这里我解释一下回表,比如我们表主键索引是学号,另外我们还根据手机号也建了索引,如果我们where 条件是手机号,分二种情况:
正例:IDB能够建立索引的种类分为【主键索引、唯一索引、普通索引】,而覆盖索引是一种查询的一种效果,用explain的结果,extra列会出现:using index.
如果我们select 获取的字段是学号,直接在手机号的索引表就能获取到数据,不需要回表; 如果我们select 的时候还有其他字段,我们查询的时候流程是这样的,先根据手机号查到学号,再根据学号去主键索引表查询数据,这个过程叫回表。
2、业务上具有唯一特性的字段,即使是组合字段,也建议建成唯一索引。说明:不要以为唯一索引影响了insert速度,这个速度损耗可以忽略,但提高查找速度是明显的;另外,即使在应用层做了非常完善的校验和控制,只要没有唯一索引,根据墨菲定律,必然有脏数据产生。
3、超过三个表禁止join。需要join的字段,数据类型保持绝对一致;多表关联查询时,保证被关联的字段需要有索引。说明:即使双表join也要注意表索引、SQL性能。
4、在varchar字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据实际文本区分度决定索引长度。说明:索引的长度与区分度是一对矛盾体,一般对字符串类型数据,长度为20的索引,区分度会高达90%以上,可以使用count(distinct left(列名, 索引长度))/count(*)的区分度来确定。
5、页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。说明:索引文件具有B-Tree的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
6、SQL性能优化的目标:至少要达到 range 级别,要求是ref级别,如果可以是const最好。说明:
1)const 单表中最多只有一个匹配行(主键或者唯一索引),在优化阶段即可读取到数据。 2)ref 指的是使用普通的索引。(normal index) 3)range 对索引进行范围检索。反例:explain表的结果,type=index,索引物理文件全扫描,速度非常慢,这个index级别比较range还低,与全表扫描是小巫见大巫。
7、建组合索引的时候,区分度最高的在最左边。正例:如果where a=? and b=? ,a列的几乎接近于唯一值,那么只需要单建idx_a索引即可。说明:存在非等号和等号混合判断条件时,在建索引时,请把等号条件的列前置。如:where c>? and d=? 那么即使c的区分度更高,也必须把d放在索引的最前列,即建立组合索引idx_d_c。
8、防止因字段类型不同造成的隐式转换,导致索引失效。
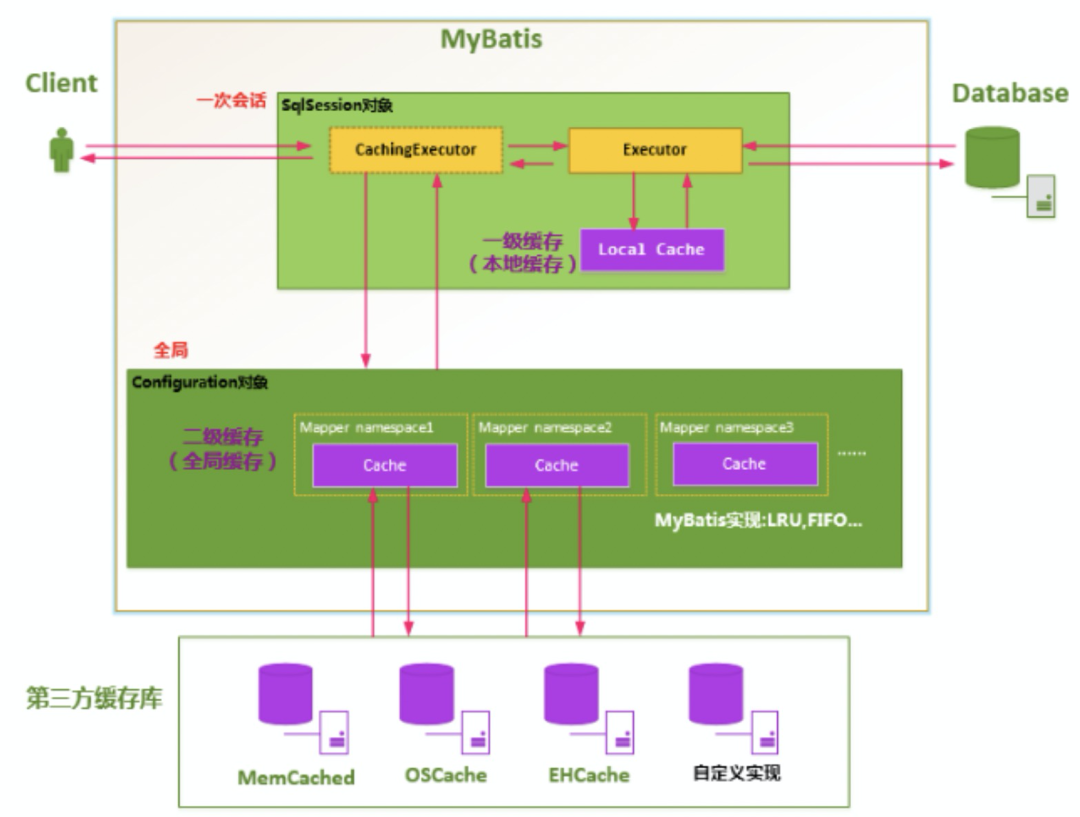
MyBatis用过吗? 一二级缓存清楚吗?
一级缓存
Mybatis的一级缓存是指SQLSession,一级缓存的作用域是SQlSession, Mabits默认开启一级缓存。在同一个SqlSession中,执行相同的SQL查询时;第一次会去查询数据库,并写在缓存中,第二次会直接从缓存中取。当执行SQL时候两次查询中间发生了增删改的操作,则SQLSession的缓存会被清空。每次查询会先去缓存中找,如果找不到,再去数据库查询,然后把结果写到缓存中。Mybatis的内部缓存使用一个HashMap,key为hashcode+statementId+sql语句。Value为查询出来的结果集映射成的java对象。SqlSession执行insert、update、delete等操作commit后会清空该SQLSession缓存。二级缓存
二级缓存是 mapper级别的,Mybatis默认是没有开启二级缓存的。第一次调用mapper下的SQL去查询用户的信息,查询到的信息会存放在该mapper对应的二级缓存区域。第二次调用namespace下的mapper映射文件中,相同的sql去查询用户信息,会去对应的二级缓存内取结果。
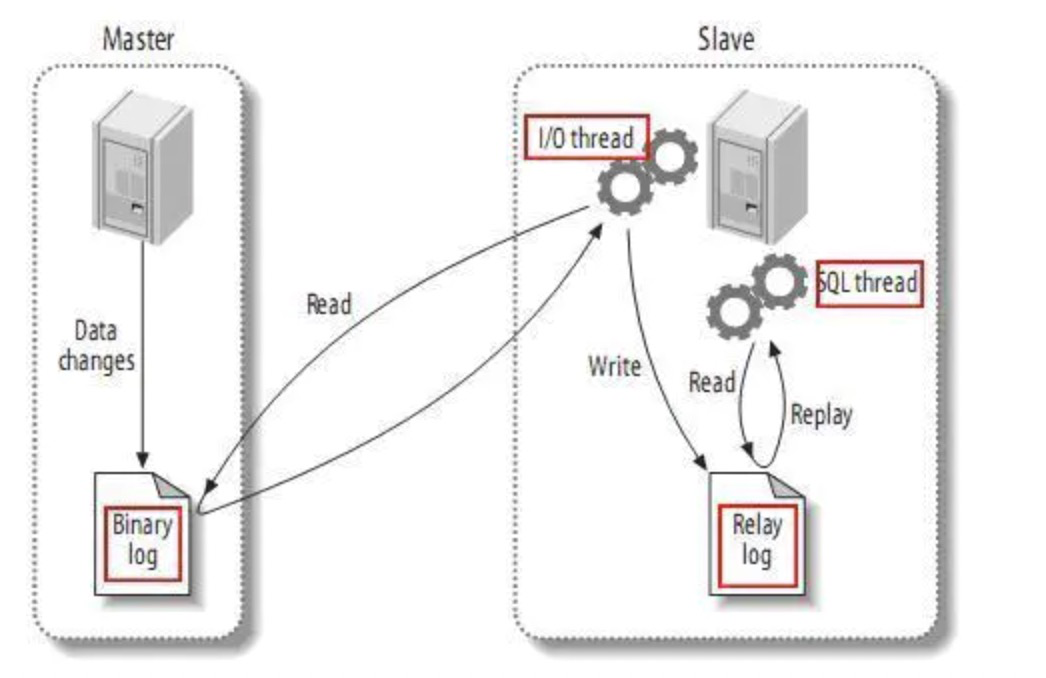
MySQL 主从同步怎么做的?binlog清楚吗?
Master 数据库只要发生变化,立马记录到Binary log 日志文件中
Slave数据库启动一个I/O thread连接Master数据库,请求Master变化的二进制日志
Slave I/O获取到的二进制日志,保存到自己的Relay log 日志文件中。
Slave 有一个 SQL thread定时检查Realy log是否变化,变化那么就更新数据
MySQL 有没有做分库分表?怎么设计的?
Why?:
当一张表的数据达到几千万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了。分表的目的就在于此,减小数据库的负担,缩短查询时间。
mysql中有一种机制是表锁定和行锁定,是为了保证数据的完整性。表锁定表示你们都不能对这张表进行操作,必须等我对表操作完才行。行锁定也一样,别的sql必须等我对这条数据操作完了,才能对这条数据进行操作。
When?(什么时候需要分表?):
单表行数超过500万行或者单表容量超过2GB,才推荐进行分库分表。说明:如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。
反例:某业务三年总数据量才2万行,却分成1024张表,问:你为什么这么设计?答:分1024张表,不是标配吗?
How?(分库分表有几种策略):
垂直拆分 or 水平拆分
拆分中间件,详细可以参考:
Sharding-sphere,前身是sharding-jdbc;当当的分库分表中间件 TDDL:jar,Taobao Distribute Data Layer; Mycat:中间件。
注:工具的利弊,请自行调研,官网和社区优先。
按照userId纬度拆分,安琪拉见过的常见的有,根据 userId % 64 取模拆0~63编号的64张表, 固定位拆,取userId 指定二位,例如倒数2,3位组成00~99 一共100张表的,百库表表。 hash: userId hash一下,然后 % 表数; Range: 另外还有按照userId 指定范围拆的,0-1千万一张表,这种用的比较少,容易产生热点。 把不同业务域的表拆成不同库,例如订单相关表、用户信息相关表、营销相关表分开在不同库; 把大字段独立存储到一张表中 把不常用的字段单独拿出来存储到一张表
用userId做的分库分表,现在需要用电话号码查询怎么办?
和回表逻辑一样,单独建一个电话号码索引表,存放电话号码和userId,查询时先根据电话号码查询userId,然后再根据userId查询数据。
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)
