
南京大学人工智能学院教授俞扬:我的牛年小结
↓↓↓点击关注,回复资料,10个G的惊喜
作者:南京大学俞扬教授
去年组里研究生新生入学的时候,有同学提到喜欢看我在知乎上的年终小结,突然想起牛年的小结没写( ° △ °|||) 因此还是觉得有必要总结一下,特别是我们碰到的种种困难,也许能给同学们一点鼓励。
我们这几年一直在发展可落地的强化学习技术。不仅是有“应用前景”,也不仅是在某个特定场景用起来,而要实现在很多决策类任务中解决问题,成为通用的智能决策工具。
当下通用落地的关键,我认为在于具备数据驱动的能力,能充分利用历史上不那么好的决策数据,学到更好的策略。因为基于数据的机器学习路径,已经在监督学习的普及应用中验证了落地的便利性。而经典强化学习研究的成果可以说都是基于仿真环境的,仿真的好坏成为制约策略质量的关键,实用性很差。
近几年发展的offline RL或叫batch RL的目标,就是要做数据驱动。然而现在offline RL音量最大的研究组的成果,应用背景考虑的是在实验室中的机器人控制之类的场景,而我们考虑的商业化场景,往往有更多和更严苛的要求,例如有各式各样的约束和第一次上线不成功就滚蛋的要求。因此对于技术路线的选择,也就出现了差异。大量offline RL工作走了model-free的方向,也就是绕开环境模型直接从数据中学策略,而这一方向完全不能满足我们的需求,光是各式各样的约束就没法往上加。只有好的环境模型才能满足需求,我们走的是把model学好的方向。
于是在看着许多model-free offline RL方法、以及Dyna-style model-based RL这一类仅少量的使用model的方法刷出benchmark新高的时候,我们琢磨着怎么把model学好、在full model中训练出能在真实任务上用起来的策略。已公开发表的工作有:
第一次证明了model学习的复合误差可以从平方级降低到线性,且不可再降低。
https://proceedings.neurips.cc/paper/2020/hash/b5c01503041b70d41d80e3dbe31bbd8c-Abstract.html
第一次突破“紧贴数据”保守原则的方法。
https://openreview.net/forum?id=lrdXc17jm6
总结起来,我们已经在数据驱动的强化学习上做了下图中的一些工作:
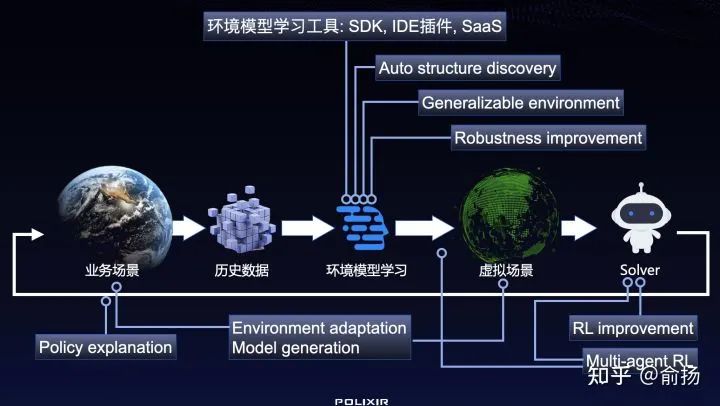
基础研究之外,我们花了很大力气把研究成果和应用经验积累到工具里(限于技术同学们都不爱写文档的事实,工具的帮助文档还在不断完善),我们年前还组织了一次强化学习应用比赛,其中一个目的也是为了收到关于工具使用情况的反馈。比赛和工具相关的信息可见「深度强化学习论坛」:
http://deeprl.neurondance.com/t/offlinerl
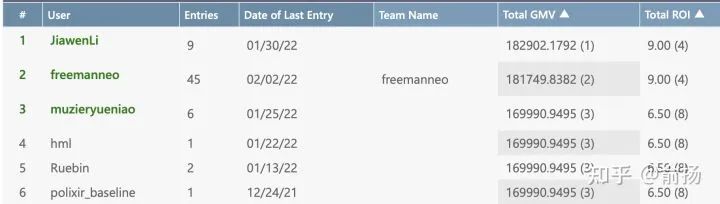
比赛任务源自真实业务,为商家发促销优惠券。历史数据是针对每个用户的“千人千面”优惠券发放的情况。而“千人千面”的策略必然要使用个人特征,不符合现在的大数据使用限制,因此比赛要求得到“千人一面”的发券策略,不能针对单个用户的特征下手,同时也要考虑商家的利益,在整体ROI(盈利率)>=6.5的约束下最大化GMV(总销额)。这里对整体盈利率的要求就是一种常见的决策约束,并且比赛可提交策略的次数有限(实际应用中很可能是1次)。另外说明的是比赛是不限技术类型的,但不提供在线试错。
最近刚有参赛同学在我们的baseline上做出了更好的成绩,也反馈了帮助工具改进的信息。预祝取得更好成绩!
今年RL会在更多的行业场景里用起来,让这种关于行动决策的AI技术在现实中转化为生产力。
三连在看,月入百万👇