
ICCV 2023:CLIP 驱动的器官分割和肿瘤检测通用模型
目录
-
前言 -
概述 -
Text branch -
Vision branch -
Masked back-propagation -
实验 -
总结 -
参考
前言
这次要介绍的文章属于 CLIP 在医学图像上的一个应用,思路上不算是创新。CLIP(Contrastive Language-Image Pre-training)是一种多模态模型,这意味着它可以同时处理文本和图像数据。它的目标是将文本描述和图像内容关联起来,使得模型能够理解文本描述与图像之间的语义关系。它通过学习大量的文本和图像来获得对于语义理解的通用知识,这种通用知识可以在各种具体任务中进行微调,使得模型可以适应不同领域的任务。CLIP 使用对比学习的方法来训练模型。它要求模型将相关的文本描述和图像匹配在一起,而将不相关的文本描述和图像分开。这样,模型可以学习如何捕捉文本和图像之间的语义相似性。
在这篇解读中,后文出现的 CLIP embedding 指的是由 CLIP 模型生成的表示文本和图像之间语义关系的特征向量。这些嵌入向量是 CLIP 模型的核心输出之一。它们编码了文本描述和图像内容之间的关联信息,使得模型能够理解文本与图像之间的语义相似性。CLIP 嵌入向量是在大规模数据上进行预训练的,因此它们可以用于各种不同的任务,而不需要从头开始训练一个新的模型。这种通用性使得 CLIP 嵌入在多个领域都有广泛的应用潜力。
对于下游任务,CLIP 会重新利用预训练获得的能力,即预测某个图像和某段文本是否为一对的能力。具体来说,对一个分类数据集,我们将所有 class 的名字分别作为 text,让 CLIP 预测输入图像与哪个最有可能是一对。当然,text 也可以进一步加上 prompt,例如下图(2)的 “A photo of [class]”。显然这个过程是一种 zero-shot 迁移。
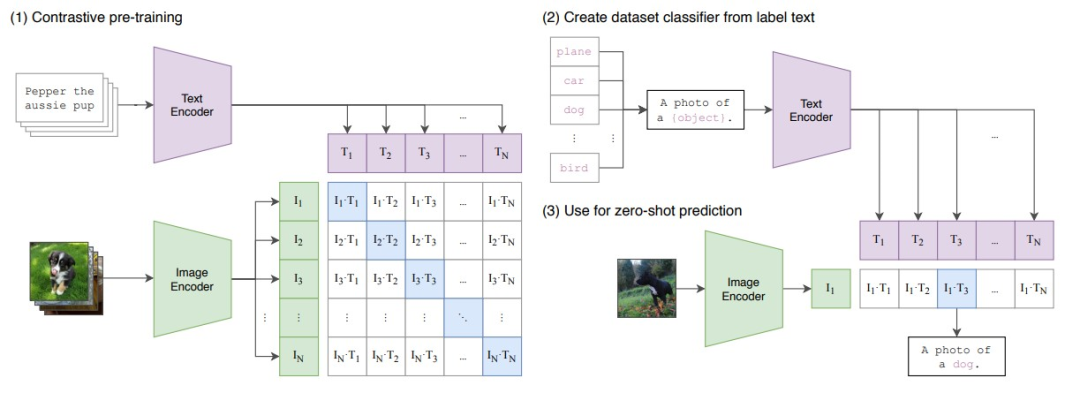
关于 CLIP 更多的细节,本篇解读就不做更多介绍了。
我们回到这篇文章中,目前,在医学图像领域中公共数据集越来越多。然而,由于每个数据集的规模较小且都是部分标记问题,以及对不同类型肿瘤的有限探究,由此产生的模型通常仅限于分割特定器官/肿瘤,并忽略了解剖结构的语义,也不能扩展到新领域。为了解决这些问题,这篇论文提出了基于 CLIP 学习的文本嵌入的通用模型,将其融入分割模型中。这种基于 CLIP 的标签编码捕捉了解剖关系,使模型能够学习结构化特征嵌入并分割 25 个器官和 6 种肿瘤。所提出的模型是从 14 个数据集的组合中开发而来,使用了共计 3,410 个 CT 扫描进行训练,然后在来自 3 个额外数据集的 6,162 个外部 CT 扫描上进行评估。
概述
用于腹部影像的公开可用数据集主要关注不同的器官和肿瘤,例如,用于 4 个器官分割的 AbdomenCT-1K 数据集,用于 16 个器官分割的 WORD 数据集,以及用于 104 个解剖结构分割的 TotalSegmentor 数据集(我们不需要关注这些数据集,这里只是举个例子)。由于这些数据集的标签分类不一致,当在这些数据集的组合上训练人工智能模型时,会出现部分标签问题。对于部分标签问题,我们举一个例子,比如对于一张图像切片,同时有肝脏和脾两个类别,但是在一个肝脏分割小数据集上,只给了肝脏的标注。同时,我们需要组合这些个小数据集,所以导致了部分标签问题出现。
为了充分利用部分标签,已经研究了几种方法,旨在构建一个能够执行器官分割和肿瘤检测的单一模型。这些研究存在以下限制:(1)由于数据集组合规模较小,组合数据集的潜力不太明显。它们的性能与特定数据集模型相似,并未在官方 benchmark 上进行评估。(2)由于采用了一位有效标签,器官和肿瘤之间的语义关系被丢弃。论文中做了相关实验,使用 prompt 的性能要比使用 one-hot 编码(存在正交性)更好。正交性指的是在"one-hot"编码中,每个类别之间的表示是互相独立的,没有重叠或交互。具体来说:对于一个具有N个不同类别的分类问题,使用 one-hot 编码后,每个类别都由一个长度为 N 的向量表示,其中只有一个元素的值为 1(代表当前类别),而其余元素的值都为 0。这确保了每个类别的表示都是正交的,不受其他类别的影响。正交性使得模型可以明确地区分不同的类别,因为每个类别的表示不会与其他类别的表示发生干扰。这在许多分类任务中是有用的,例如图像分类或自然语言处理中的词汇分类。然而,正交性也具有一些限制,特别是在涉及到一些复杂的关系和语义信息的任务中。在某些情况下,one-hot 编码可能无法捕捉类别之间的相关性或语义关系,因为它将每个类别都视为彼此独立的。这在某些机器学习任务中可能会限制模型的性能。

如下图是这篇文章提出的基于 CLIP 的通用模型,用于腹部器官分割和肿瘤检测。为了解决标签不一致和正交性问题,将 CLIP 嵌入与分割模型整合在一起,从而实现了一个灵活而强大的分割器。该模型可以有效地从部分标签的数据集中学习,并取得了高性能。
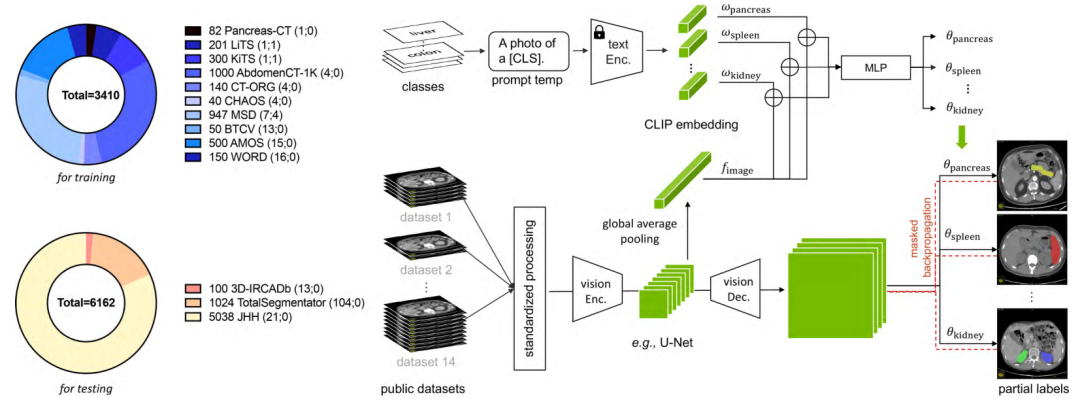
Text branch
如概述图中的上半部分,某一类的 CLIP embedding,它是由 CLIP 中预训练的文本编码器和一个医学 prompt(例如,“[CLS] 的计算机断层扫描”,其中 [CLS] 是具体的类名)生成的。首先将 CLIP embedding 和全局图像特征(fimage)连接在一起,然后输入到一个 MLP,即基于文本的控制器(已经有其他工作这么做了),以生成参数(θk),即 θk = MLP(wk ⊕ f),其中 ⊕ 表示连接。尽管 CLIP embedding 明显优于一位有效标签,但医学提示模板的选择至关重要。
最终在 Text branch 中,我们会得到 k 个生成参数 θ,分别和所有要分割的类别对应,形成 k 个分支,解决标签正交性的问题。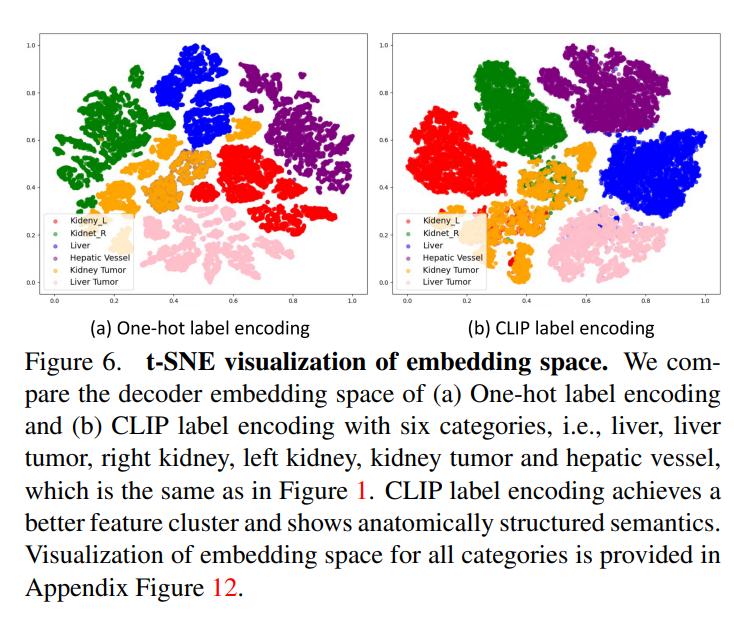
进一步展示了嵌入空间的 t-SNE 可视化,分别对比了 one-hot 编码和 CLIP 编码,如上图所示。可以看到,CLIP 编码的解码器嵌入展现出更好的特征聚类和解剖结构。例如,通用模型中的右肾和左肾特征在嵌入空间中更接近(肝和肝肿瘤也是接近的,这样就避免了 one-hot 的正交性),这与下图中显示的 CLIP embedding 之间的余弦相似度高度匹配。这验证了 CLIP 基础的编码可以帮助模型捕捉解剖关系并学习结构化的特征嵌入。

Vision branch
首先对图像进行预处理,使用等间距和标准化强度比例,以减小不同数据集之间的域差异(减小 domain gap),后由视觉编码器进行处理。令 F 表示由视觉编码器提取的图像特征。为了处理 F,使用了三个连续的卷积层,卷积核为 1×1×1,即文本驱动的解码器。前两层具有 8 个通道,最后一层具有 1 个通道。k 类的预测计算为 Pk = Sigmoid (((F ∗ θk1) ∗ θk2) ∗ θk3),其中 θk = {θk1,θk2,θk3} 在文本分支中计算,* 表示卷积。对于每个类别 k,我们生成表示每个类别的前景的预测 Pk ∈ ,以一对多的方式进行计算(即使用 Sigmoid 而不是 Softmax,因为每个像素可以同时属于多个类别)。
Masked back-propagation
为了解决标签不一致性问题,这篇文章提出了掩码反向传播技术。使用 BCE 损失函数进行监督。屏蔽了不包含在对应类别的损失项,并且只对准确的监督进行反向传播以更新整个框架。掩码反向传播解决了部分标签问题中的标签不一致性。具体来说,部分标签的数据集将一些其他器官标记为背景,导致现有的训练方案失效。
实验
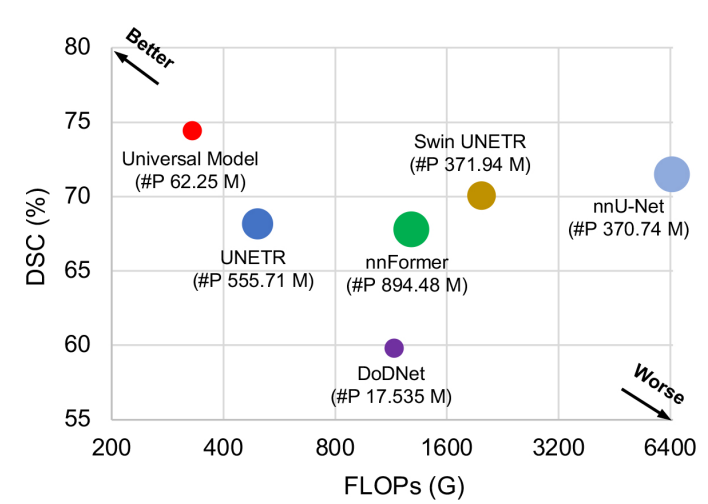
在 MSD 数据集上的比较如下表,可以发现,通用模型的性能,已经超过了 nnUNet:

一些肿瘤检测 cases 的可视化如下图:

文章中还验证了通用模型的 FLOPS,因为通用模型只是利用了 CLIP 的 text encoder,backbone 是不受限制的,所以参数量可以很低。文中使用 CLIP 的预训练文本编码器 ViTB/32 作为文本分支。可以提取并存储文本特征,以减少在训练和推理阶段由文本编码器带来的开销,因为 CLIP embedding 仅依赖于固定的字典。
总结
总的来说,这篇文章介绍了一种使用 CLIP embedding 的通用模型,用于医学图像分割和肿瘤检测。该模型在多个方面展示了出色的性能,解决了医学图像分割任务中的一些挑战,特别是在捕捉解剖结构和处理标签不一致性和正交性方面取得了显著进展。文章强调了 CLIP embedding 相对于传统的独热编码和其他预训练嵌入的优势,尤其是在医学图像分割任务中。CLIP embedding 能够更好地捕捉图像和文本之间的关系。
参考
-
https://arxiv.org/pdf/2301.00785.pdf -
https://github.com/ljwztc/CLIP-Driven-Universal-Model