
写给前端工程师的Linux实战教程
笔者使用的是 AliYun 服务器 ECS,镜像选择的是 Ubuntu,Ubuntu的详细版本信息是:Ubuntu 18.04.4 LTS (GNU/Linux 4.15.0-91-generic x86_64),如何购买云服务器不在本文讨论范围内,如果只是学习,那你完全可以使用 virtualbox 安装 Ubuntu。
# 连接服务器
$ ssh <username>@<hostname>
# 更新系统源
$ apt update
# 升级系统源
$ apt upgrade
必备环境及应用
Git
# 安装 git
$ apt install git
命令行配置
# 1、初始化设置
$ git config --global user.name 'youngjuning'
$ git config --global user.email 'youngjuning@aliyun.com'
# 2、将 `color.ui` 设置为 `auto` 可以让命令的输出拥有更高的可读性。
$ git config --global color.ui auto
# 3、git 记住用户名和密码
$ git config --global credential.helper store
# 4、core.autocrlf
$ git config --global core.autocrlf input
Linux或Mac系统使用LF作为行结束符,因此你不想 Git 在签出文件时进行自动的转换;当一个以
CRLF为行结束符的文件不小心被引入时你肯定想进行修正,把core.autocrlf设置成input来告诉 Git 在提交时把CRLF转换成LF,签出时不转换:这样会在 Windows 系统上的签出文件中保留CRLF,会在 Mac 和 Linux 系统上,包括仓库中保留LF。
Java
# 安装 jre、jdk
$ apt install openjdk-8-jre-headless openjdk-8-jdk-headless
Node
Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行时。我们使用 n 模块来维护 Node 的版本:
$ apt install nodejs npm build-essential
$ sudo npm install -g npm n
# 安装最新版
$ sudo n latest
## 其他命令##
# 安装指定版本
$ sudo n 10.16.0
# 安装最新的稳定版
$ sudo n lts
# 删除指定版本
$ n rm 12.10.0
# 除去当前版本以外的所有缓存版本
$ n prune
oh-my-zsh
修改
~/.zshrc之后都需要执行source ~/.zshrc命令使之立即生效
echo $SHLL可以查看当前 Shell
apt install zshgit clone https://github.com/robbyrussell/oh-my-zsh.git ~/.oh-my-zsh`cp ~/.oh-my-zsh/templates/zshrc.zsh-template ~/.zshrc nano ~/.zshrc找到 ZSH_THEME="robbyrussell",把robbyrussell替换为ys修改默认Shell: chsh -s /bin/zsh命令高亮 git clone https://github.com/zsh-users/zsh-syntax-highlighting.git "$HOME/.zsh-syntax-highlighting" --depth 1echo "source $HOME/.zsh-syntax-highlighting/zsh-syntax-highlighting.zsh" >> "$HOME/.zshrc"重新打开命令行 echo "export EDITOR=nano" >> ~/.zshrc
vim
建议使用:https://github.com/amix/vimrc
$ git clone --depth=1 https://github.com/amix/vimrc.git ~/.vim_runtime
$ sh ~/.vim_runtime/install_awesome_vimrc.sh
$ echo "set number" >> ~/.vimrc
$ echo "set showcmd" >> ~/.vimrc
$ source ~/.vimrc
目录
/bin:包含了会被所有用户使用的可执行程序boot:包含与 Linux 启动密切相关的文件dev:包含外设。它里面的子目录,每一个对应一个外设etc:包含系统的配置文件home:用户的私人目录lib:包含被程序所调用的库文件,例如.so结尾的文件media:可移动的外设(USB盘,SD卡,DVD,光盘,等等)插入电脑时mnt:用于临时挂载一些装置opt:可选的应用软件包,用于安装多数第三方软件和插件root:超级用户 root 的家目录sbin:用于包含系统级的重要可执行程序srv:包含一些网络服务启动之后所需要取用的数据tmp:普通用户和程序存放临时文件的地方usr:Unix Software Resource,安装了大部分用户要调用的程序var:通常包含程序的数据,比如 log(日志)文件
常用命令
Linux命令搜索引擎:https://git.io/linux
reboot:重新启动正在运行的Linux操作系统halt:关闭系统shutdown:用来系统关机命令。shutdown指令可以关闭所有程序,并依用户的需要,进行重新开机或关机的动作。poweroff:直接运行即可关机history:用于显示历史命令whice:查找并显示给定命令的绝对路径pwd:显示当前工作目录。(Print Working Directory)source:在当前Shell环境中从指定文件读取和执行命令,让文件修改立即生效。updatedb:创建或更新locate命令所必需的数据库文件uname -a:显示全部Linux系统信息cat /proc/version:显示Linux信息cat /etc/lsb-release:查看发行版信息echo $SHELL:当前的shellservice <service> force-reload|reload|restart|start|status|stopsystemctl start|stop|restart|status|reload:enable:开机自动启动服务disable:开机不自动启动服务is-enabled:查看服务是否开机自动启动list-unit-files --type=service:查看各个级别下服务的启动和禁用情况
文件管理
文件目录操作
ls:显示目录内容列表-a:列出所有文件,包括以 "." 开头的隐含文件。-l:除每个文件名外,增加显示文件类型、权限、硬链接数、所有者名、组名、大小(byte)及时间信息(如未指明是其它时间即指修改时间),可以用ll代替du:显示每个文件和目录的磁盘使用空间(Disk Usage)-a或-all:显示目录中个别文件的大小。-h或--human-readable:以K,M,G为单位,提高信息的可读性。-s或--summarize:仅显示总计,只列出最后加总的值。cat -N:连接多个文件并打印到标准输出。(concatenate)less -Nn键:跳转到下一个匹配项 shift+n:跳转到上一个匹配项 空格键:前进一页(一个屏幕) b键:后退一页(一个屏幕) d键:前进半页(半个屏幕) u键:后退半页(半个屏幕) 回车键/e键/下箭头:前进一行 y键/上箭头:后退一行 q键:停止读取文件,中止 less 命令 =键:显示你在文件中的什么位置 /键:进入搜索模式 head:显示文件的开头部分tail:在屏幕上显示指定文件的末尾若干行-f:显示文件最新追加的内容。-s<秒数>:与-f选项连用,指定监视文件变化时间隔的秒数,默认1秒touch:创建新的空文件mkdir:用来创建目录-p或--parents:若所要建立目录的上层目录目前尚未建立,则会一并建立上层目录cp:将源文件或目录复制到目标文件或目录中-r或-R:递归处理,将指定目录下的所有文件与子目录一并处理,recursivemv:用来对文件或目录重新命名rm:用于删除给定的文件和目录-r或-R:递归处理,将指定目录下的所有文件与子目录一并处理,recursive-f:强制删除文件或目录ln:用来为文件创建链接-s,--symbolic:对源文件建立符号链接,而非硬链接硬链接缺陷:一般情况下,只能创建指向文件的硬链接,不能创建指向目录的 硬链接指的是使用了同一个 inode号,但是文件名不一样ls -i:显示inode号locate:比find好用的文件查找工具,需要配合updatedb使用find:在指定目录下查找文件find [何处] <何物> [做什么]「f」 普通文件 「l」 符号连接 「d」 目录 「c」 字符设备 「b」 块设备 「s」 套接字 「p」 Fifo -name <范本样式>:指定字符串作为寻找文件或目录的范本样式-size <文件大小>:查找符合指定的文件大小的文件-type <文件类型>:只寻找符合指定的文件类型的文件;-atime <24小时数>:查找在指定时间曾被存取过的文件或目录,单位以24小时计算;-exec <执行指令>:假设find指令的回传值为True,就执行该指令find . -name *.txt -exec chmod 600 {} \;可以换成
-ok,ok 会让你确认操作
权限管理
sudo su:切换 root 身份,substitute douseradd -m:创建的新的系统用户自动创建用户的家目录passwd:用于让用户可以更改自己的密码`userdel -r:用于删除给定的用户以及与用户相关的文件
users:显示当前登录系统的所有用户usermod:用于修改用户的基本信息-l:对用户重命名。/home中的用户家目录名不改变,需要手动修改-g:修改用户所在群组-G:将用户添加到多个群组,多个群组用,分割-aG或-ag:不离开原来的群组进入新的群组groupadd:用于创建一个新的工作组groups:用来打印指定用户所属的工作组chown:用来变更文件或目录的拥有者或所属群组chown <username>[:gruop] <file|dir>-R:递归处理,将指定目录下的所有文件及子目录一并处理chgrp:用来变更文件或目录的所属群组chmod:用来变更文件或目录的权限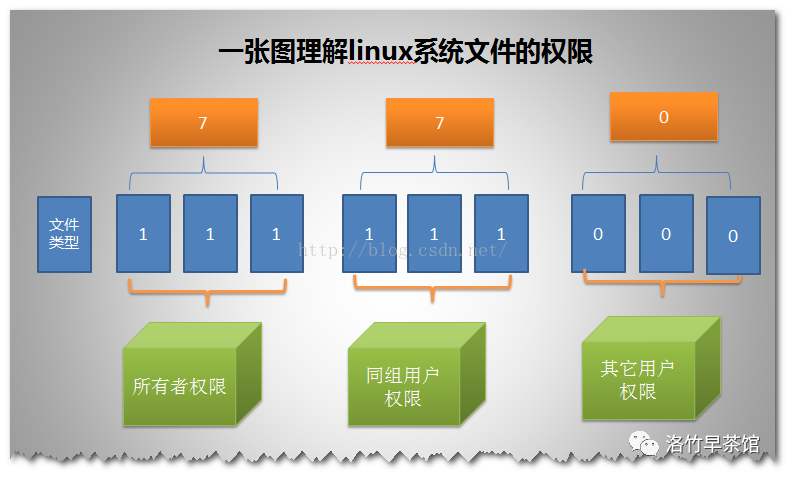
一共有10位,第「1」位代表文件类型,第「2-4」位表示所有者的读、写和执行权限,第「5-7」位表示同组用户的读、写和执行权限,第「8-10」位表示其他用户的读、写和执行权限。如果没有权限用
-占位。如果开启 SELinux,则第「11」位会多一个.。u:user 的缩写,是英语用户的意思。表示所有者 g:group的缩写,是英语群组的意思。表示群组用户 o:other的缩写,是英语其他的意思。表示其他用户 a:all的缩写,是英语所有的意思。表示所有用户 +:加号,表示添加权限 -:减号,表示去除权限 =:等号,表示分配权限 没有权限:0 执行权限:1 写权限:2 写执行权限:3 读权限:4 读执行权限:5 读写权限:6 读写执行权限:7 用数字来分配权限
用字母来分配权限
chmod u+rx file:文件 file 的所有者增加读和运行的权限chmod g+r file:文件 file 的群组其他用户增加读的权限chmod o-r file:文件 file 的其他用户移除读的权限chmod g+r o-r file:文件 file 的群组其他用户增加读的权限,其他用户移除读的权限chmod go-r file:文件 file 的群组其他用户和其他用户均移除读的权限chmod +x file:文件 file 的所有用户增加运行的权限chmod u=rwx,g=r,0=- file:文件 file 的所有者分配读,写和执行的权限;群组其他用户分配读的权限,不能写或执行;其他用户没有任何权限d:英语 directory 的缩写,表示「目录」l:英文 link 的缩写,表示「链接」-:文件文件类型 r:英语 read 的缩写,表示「读」w:英文 write 的缩写,表示「写」x:英语 execute 的缩写,表示「执行/运行」。可以运行这个文件.:SELinux 的安全标签,如果第11位有.,表示启用了 SELinux
正则表达式和数据操作
grep: 筛选数据
「grep」 (global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。用于过滤/搜索的特定字符。可使用正则表达式能多种命令配合使用,使用上十分灵活。
-i--ignore-case:忽略字符大小写的差别。-n--line-number:在显示符合范本样式的那一列之前,标示出该列的编号。-v--revert-match:反转查找。-R/-r--recursive:在所有子目录和子文件中查找,可以用rgrep替代-E--extended-regexp:将范本样式为延伸的普通表示法来使用,意味着使用能使用扩展正则表达式。可以用egrep代替grep -E ^p /etc/profilegrep -E [at] /etc/profilegrep -E [0-4] /etc/profilegrep -E [a-zA-Z] /etc/profile
规则表达式
^ # 锚定行的开始 如:'^grep'匹配所有以grep开头的行。
$ # 锚定行的结束 如:'grep$' 匹配所有以grep结尾的行。
. # 匹配一个非换行符的字符 如:'gr.p'匹配gr后接一个任意字符,然后是p。
* # 匹配零个或多个先前字符 如:'*grep'匹配所有一个或多个空格后紧跟grep的行。
.* # 一起用代表任意字符。
[] # 匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
[^] # 匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。
\(..\) # 标记匹配字符,如'\(love\)',love被标记为1。
\< # 锚定单词的开始,如:'\<grep'匹配包含以grep开头的单词的行。
\> # 锚定单词的结束,如'grep\>'匹配包含以grep结尾的单词的行。
x\{m\} # 重复字符x,m次,如:'0\{5\}'匹配包含5个o的行。
x\{m,\} # 重复字符x,至少m次,如:'o\{5,\}'匹配至少有5个o的行。
x\{m,n\} # 重复字符x,至少m次,不多于n次,如:'o\{5,10\}'匹配5--10个o的行。
\w # 匹配文字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以G后跟零个或多个文字或数字字符,然后是p。
\W # \w的反置形式,匹配一个或多个非单词字符,如点号句号等。
\b # 单词锁定符,如: '\bgrep\b'只匹配grep。
sort 文件排序
对文本文件中所有行进行排序。
-o,--output=FILE:将结果写入FILE而不是标准输出。sort -o name.txt name_sorted.txt-r,--reverse:将结果倒序排列。-R:--random-sort随机排序,但分组相同的行。-n,--numeric-sort:根据数字排序。
主要用途
将所有输入文件的内容排序后并输出。 当没有文件或文件为 -时,读取标准输入。
wc 文件统计
统计文件的行数、字数、字节数
「wc命令」 统计指定文件中的字节数、字数、行数,并将统计结果显示输出。利用wc指令我们可以计算文件的Byte数、字数或是列数,若不指定文件名称,或是所给予的文件名为“-”,则wc指令会从标准输入设备读取数据。wc同时也给出所指定文件的总统计数。
-c:统计字节数,或--bytes或--chars:只显示Bytes数-l:统计行数,或--lines:只显示列数-m:统计字符数。这个标志不能与-c标志一起使用-w:统计字数,或--words:只显示字数。一个字被定义为由空白、跳格或换行字符分隔的字符串-L:打印最长行的长度
uniq: 删除文件中的重复内容
显示或忽略重复的行。uniq 命令有点”呆“,只能将连续的重复行变为一行
-c,--count:在每行开头增加重复次数-d,--repeated:只显示重复行的值
主要用途
将输入文件(或标准输入)中邻近的重复行写入到输出文件(或标准输出)中。 当没有选项时,邻近的重复行将合并为一个。
cut: 剪切文件的一部分内容
连接文件并打印到标准输出设备上
-c:仅显示行中指定范围的字符,cut -c 2-4 file-d:指定字段的分隔符,默认的字段分隔符为“TAB”。-f:显示指定字段的内容。cut -d , -f 1,3 notes.csv;cut -d , -f 2- notes.csv
输出重定向
黑洞文件
/dev/null,此文件具有唯一的属性,它总是空的。它能使发送到/dev/null的任何数据作废
> 重定向到文件
如果此文件不存在,则新建一个文件 如果此文件已经存在,那就会把文件内容覆盖掉,而且不会征求用户同意
>> 重定向到文件末尾
>>的作用与>是类似的,不过它不会像>那么危险。它会将重定向的内容写入到文件末尾,起到追加的作用。如果文件不存在,则创建文件
2> 、2>>重定向到标准错误输出
$ cat not_exist_file.csv > results.txt 2> errors.log
2>&1 组合符合
将标准错误输出重定向到与标准输出相同的地方 覆盖: cat not_exist_file_csv > results.txt 2>&1末尾追加: cat not_exist_file_csv >> results.txt 2>&1
stdin、stdout、stderr
从键盘向终端输入数据,这是标准输入,也就是 stdin 终端接收键盘输入的命令,会产生两种输出 标准输出:stdout。指终端输出的信息(不包括错误信息) 标准错误输出:stderr。指终端输出的错误信息
输入重定向
< 从文件中读取
cat notes.csvcat命令接受的输入是 notes.csv 这个文件名那么它要先打开 notes.csv 文件 然后打印出文件内容 cat < notes.csvcat命令接受的输入直接是 notes.csv 这个文件的内容cat命令只负责将其内容打印打开文件并将文件内容传递给 cat命令的工作则交给终端完成
<< 从键盘读取
<<符号的作用是将键盘的输入重定向为某个命令的输入sort -n << END
| 管道符号
将一个命令的输出作为另一个命令的输入
传说中的 ”管道符号“: ||符号既然被称为”管道符“,其作用就是”建立命令管道“管道也算是重定向流的一种 cut -d , -f 1 notes.csv | sort > sorted_names.txtdu -h | sort -n | headsudo grep log -Ir /var/log | cut -d : -f 1 | sort | uniq-I:排除二进制文件-r:用于递归遍历
进程和系统监测
w:显示目前登入系统的用户信息uptime:查看Linux系统负载信息能够打印系统总共运行了多长时间和系统的平均负载。uptime命令可以显示的信息显示依次为:现在时间、系统已经运行了多长时间、目前有多少登陆用户、系统在过去的1分钟、5分钟和15分钟内的平均负载。
tload:显示系统负载状况以图形化的方式输出当前系统的平均负载到指定的终端。假设不给予终端机编号,则会在执行tload指令的终端机显示负载情形
who:显示目前登录系统的用户信息显示目前登录系统的用户信息。执行who命令可得知目前有那些用户登入系统,单独执行who命令会列出登入帐号,使用的终端机,登入时间以及从何处登入或正在使用哪个X显示器。
ps:报告当前系统的进程状态 process status用于报告当前系统的进程状态。可以搭配
kill指令随时中断、删除不必要的程序。ps命令是最基本同时也是非常强大的进程查看命令,使用该命令可以确定有哪些进程正在运行和运行的状态、进程是否结束、进程有没有僵死、哪些进程占用了过多的资源等等,总之大部分信息都是可以通过执行该命令得到的。-ef:列出所有用户在所有终端的所有进程,可以配合管道方便查看ps -ef | less-efH:按照乔木状列出进程-u:列出此用户运行的进程-aux:通过CPU和内存使用来过滤进程ps -axjf,pstree:以树形结构显示进程ps -aux --sort -pcpu | less:根据CPU使用率降序排列ps -aux --sort -pmem | less:根据内存使用率降序排列UID:运行进程的用户 PID:进程号,process identifier,每个进程有唯一的进程号 PPID:程序的父进程号,parent process ID TTY:进程运行所在的终端 TIME:进程运行的时间 CMD:产生这个进程的程序名 输出 实践 top:显示或管理执行中的程序q键:退出 h键:显示帮助文档 B键:加粗某些信息 f/F键:在进程列表中添加或删除某些列 u键:依照用户来过滤显示 k键:结束某个进程 s键:改变刷新页面的时间,默认地页面每个3秒刷新一次 kill:根据进程号结束一个进程-9:强制结束进程killall:根据进程名结束所有进程,可以结合find
glances
$ apt install glances -y
htop
$ apt install htop -y
管理前后台进程
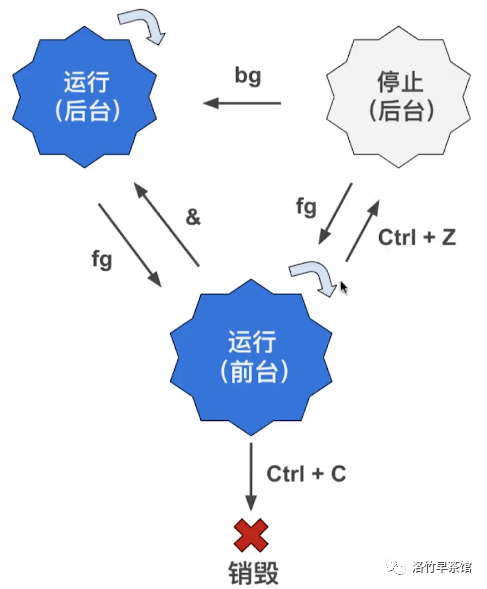
& 符号:后台运行进程
cp file.txt file-copy.txt &find / -name "*log" > output_find 2>&1 &
nohup: 使进程与终端分离
无论是否将 nohup 命令的输出重定向到终端,输出都将附加到当前目录的 nohup.out 文件中。hangup,挂起
如果当前目录的 nohup.out 文件不可写,输出重定向到$HOME/nohup.out文件中。如果没有文件能创建或打开以用于追加,那么 command 参数指定的命令不可调用。如果标准错误是一个终端,那么把指定的命令写给标准错误的所有输出作为标准输出重定向到相同的文件描述符。
Ctrl + Z、bg 进程转为后台运行
jobs:显示后台进程状态
fg:使进程转为前台运行
文件的解压和压缩
tar:Linux下的归档使用工具,用来打包和备份x:extract 的缩写,表示”提取,取出“ c:create 的缩写,表示创建 v:verbose 的缩写,表示冗余。会显示操作细节 f:file 的缩写,表示文件,指定归档文件 -cvf:创建一个 tar 归档,tar -cvf a.tar a/-tf:显示归档里的内容,并不解开归-xvf:解开归档-zcvf:归档,然后用 gzip 来压缩归档-zxvf:解gzip压缩,然后解开归档-jcvf:归档,然后用 bzip2 来压缩归档-jxvf:解bzip2压缩,然后解开归档zcat、zmore、zlessbzcat、bzmore、bzlessunzip、unrar:apt install zip
定时和延时执行
date:显示或设置系统时间与日期
date +"%H":11date +"%H:%M:%S":11:15:51date +"%Y-%m-%d":2020-03-29date +"%Y-%m-%d %H:%M:%S":2020-03-29 11:15:51修改系统时间: date 10121430
at:在指定时间执行一个任务
「at命令」 用于在指定时间执行命令。at允许使用一套相当复杂的指定时间的方法。它能够接受在当天的hh:mm(小时:分钟)式的时间指定。假如该时间已过去,那么就放在第二天执行。当然也能够使用midnight(深夜),noon(中午),teatime(饮茶时间,一般是下午4点)等比较模糊的词语来指定时间。用户还能够采用12小时计时制,即在时间后面加上AM(上午)或PM(下午)来说明是上午还是下午。也能够指定命令执行的具体日期,指定格式为month day(月 日)或 mm/dd/yy(月/日/年)或dd.mm.yy(日.月.年)。指定的日期必须跟在指定时间的后面。
上面介绍的都是绝对计时法,其实还能够使用相对计时法,这对于安排不久就要执行的命令是很有好处的。指定格式为:now + count time-units,now就是当前时间,time-units 是时间单位,这里能够是minutes(分钟)、hours(小时)、days(天)、weeks(星期)。count是时间的数量,究竟是几天,还是几小时,等等。更有一种计时方法就是直接使用today(今天)、tomorrow(明天)来指定完成命令的时间。
at 22:10,会提示让输入命令,以<EOT>结束输入at 22:10 tomorrow:明天 22:10 执行at 22:10 03/30/2020:在 2020年3月20号22:10执行at now +10 minutes:10分钟之后执行
atq:列出当前用户的at任务列表
q是英语 queue 的首字母,表示“队列”
「atq命令」 显示系统中待执行的任务列表,也就是列出当前用户的at任务列表。
atrm:删除待执行任务队列中的指定任务
「atrm命令」 用于删除待执行任务队列中的指定任务。
sleep:将目前动作延迟一段时间
touch file.txt;sleep 10;rm file.txt
&&、||、;
&&:&&号前的命令执行成功,才会执行后面的命令||:||号前的命令执行失败,才会执行后面的命令;:不论分号前的命令执行成功与否,都执行分号后的命令
crontab 提交和管理用户的需要周期性执行的任务
「crontab命令」 被用来提交和管理用户的需要周期性执行的任务,与windows下的计划任务类似,当安装完成操作系统后,默认会安装此服务工具,并且会自动启动crond进程,crond进程每分钟会定期检查是否有要执行的任务,如果有要执行的任务,则自动执行该任务。
-e:编辑该用户的计时器设置;-l:列出该用户的计时器设置;-r:删除该用户的计时器设置;-u <用户名称>:指定要设定计时器的用户名称。
m h dom mon dow command
顺序口诀:分 时 日 月 周
m:minute 的缩写,表示”分钟“(0~59)
h:hour 的缩写,表示“小时”(0~23)
dom:day of month 的缩写,表示“一个月的哪一天”(0~31)
mon:month 的缩写,表示”月份“(1~12)
dow:day of week 的缩写,表示“星期几”(0~6,星期日是0)
command:英语“命令”的意思,表示需要定时执行的命令
「特殊字符:」
星号(*):代表所有可能的值,例如month字段如果是星号,则表示在满足其它字段的制约条件后每月都执行该命令操作。 逗号(,):可以用逗号隔开的值指定一个列表范围,例如,“1,2,5,7,8,9” 中杠(-):可以用整数之间的中杠表示一个整数范围,例如“2-6”表示“2,3,4,5,6” 正斜线(/):可以用正斜线指定时间的间隔频率,例如“0-23/2”表示每两小时执行一次。同时正斜线可以和星号一起使用,例如*/10,如果用在minute字段,表示每十分钟执行一次。
实例
一定要换行,不换行不会生效的 重启 cron 服务:
systemctl cron.service restart
「每1分钟执行一次command」
* * * * * command
「每小时的第3和第15分钟执行」
3,15 * * * * command
「在上午8点到11点的第3和第15分钟执行」
3,15 8-11 * * * command
「每隔两天的上午8点到11点的第3和第15分钟执行」
3,15 8-11 */2 * * command
「每个星期一的上午8点到11点的第3和第15分钟执行」
3,15 8-11 * * 1 command
「每晚的21:30重启smb」
30 21 * * * /etc/init.d/smb restart
「每月1、10、22日的4 : 45重启smb」
45 4 1,10,22 * * /etc/init.d/smb restart
「每周六、周日的1:10重启smb」
10 1 * * 6,0 /etc/init.d/smb restart
「每天18 : 00至23 : 00之间每隔30分钟重启smb」
*/30 18-23 * * * /etc/init.d/smb restart
「每星期六的晚上11:00 pm重启smb」
0 23 * * 6 /etc/init.d/smb restart
「每一小时重启smb」
* */1 * * * /etc/init.d/smb restart
「晚上11点到早上7点之间,每隔一小时重启smb」
* 23-7/1 * * * /etc/init.d/smb restart
「每月的4号与每周一到周三的11点重启smb」
0 11 4 * mon-wed /etc/init.d/smb restart
「一月一号的4点重启smb」
0 4 1 jan * /etc/init.d/smb restart
「每小时执行/etc/cron.hourly目录内的脚本」
01 * * * * root run-parts /etc/cron.hourly
SSH
全局 SSH 客户端的配置: /etc/ssh/ssh_config用户 SSH 客户端的配置: ~/.ssh/config如果 ~/.ssh不存在,执行ssh localhostnano config进行编辑SSH 服务端的配置: /etc/ssh/sshd_config
服务端 config 文件的常用配置参数
Port:sshd 服务端口号(默认是22) PermitRootLogin:是否允许以 root 用户身份登录(默认是可以) PasswordAuthentication:是否允许密码验证登录(默认是可以) PubkeyAuthentication:是否允许公钥验证登录(默认是可以) PermitEmptyPasswords:是否允许空密码登录(不安全。默认不可以)
客户端 config 文件的配置
$ nano ~/.ssh/config
Host aliyun
HostName 47.98.152.68
Port 22
User root
$ ssh aliyun
配置免密码登录
在客户机中生成密钥对(公钥和私钥)
ssh-keygen -t rsa -C "youngjuning@aliyun.com"id_rsa:私钥 id_rsa.pub:公钥 在
~/.ssh/目录下,会新生成两个文件ssh-copy-id:把本地的 ssh 公钥文件安装到远程主机对应的账户下$ ssh-copy-id -i ~/.ssh/id_rsa.pub root@47.98.152.68「ssh-copy-id命令」 可以把本地主机的公钥复制到远程主机的
authorized_keys文件上,ssh-copy-id命令也会给远程主机的用户主目录(home)和~/.ssh, 和~/.ssh/authorized_keys设置合适的权限。-i:指定公钥文件
「设置免密码后仍想使用密码登录:」
$ ssh -o PreferredAuthentications=password -o PubkeyAuthentication=no root@47.98.152.68
「测试Github是否正确配置免密码登录:」
ssh -T git@github.com
Linux 网络
wget:Linux系统下载文件工具
「wget命令」 用来从指定的URL下载文件。wget非常稳定,它在带宽很窄的情况下和不稳定网络中有很强的适应性,如果是由于网络的原因下载失败,wget会不断的尝试,直到整个文件下载完毕。如果是服务器打断下载过程,它会再次联到服务器上从停止的地方继续下载。这对从那些限定了链接时间的服务器上下载大文件非常有用。
wget支持HTTP,HTTPS和FTP协议,可以使用HTTP代理。所谓的自动下载是指,wget可以在用户退出系统的之后在后台执行。这意味这你可以登录系统,启动一个wget下载任务,然后退出系统,wget将在后台执行直到任务完成,相对于其它大部分浏览器在下载大量数据时需要用户一直的参与,这省去了极大的麻烦。
用于从网络上下载资源,没有指定目录,下载资源回默认为当前目录。wget虽然功能强大,但是使用起来还是比较简单:
「支持断点下传功能」 这一点,也是网络蚂蚁和FlashGet当年最大的卖点,现在,Wget也可以使用此功能,那些网络不是太好的用户可以放心了; 「同时支持FTP和HTTP下载方式」 尽管现在大部分软件可以使用HTTP方式下载,但是,有些时候,仍然需要使用FTP方式下载软件; 「支持代理服务器」 对安全强度很高的系统而言,一般不会将自己的系统直接暴露在互联网上,所以,支持代理是下载软件必须有的功能; 「设置方便简单」 可能,习惯图形界面的用户已经不是太习惯命令行了,但是,命令行在设置上其实有更多的优点,最少,鼠标可以少点很多次,也不要担心是否错点鼠标; 「程序小,完全免费」 程序小可以考虑不计,因为现在的硬盘实在太大了;完全免费就不得不考虑了,即使网络上有很多所谓的免费软件,但是,这些软件的广告却不是我们喜欢的。
scp:加密的方式在本地主机和远程主机之间复制文件
「scp命令」 用于在Linux下进行远程拷贝文件的命令,和它类似的命令有cp,不过cp只是在本机进行拷贝不能跨服务器,而且scp传输是加密的。可能会稍微影响一下速度。当你服务器硬盘变为只读read only system时,用scp可以帮你把文件移出来。另外,scp还非常不占资源,不会提高多少系统负荷,在这一点上,rsync就远远不及它了。虽然 rsync比scp会快一点,但当小文件众多的情况下,rsync会导致硬盘I/O非常高,而scp基本不影响系统正常使用。
$ scp file.txt root@192.168.2.195
netstat -ntulp | grep 9001
查看端口占用情况
rsync:远程数据同步工具
「rsync命令」 是一个远程数据同步工具,可通过LAN/WAN快速同步多台主机间的文件。rsync使用所谓的“rsync算法”来使本地和远程两个主机之间的文件达到同步,这个算法只传送两个文件的不同部分,而不是每次都整份传送,因此速度相当快。rsync是一个功能非常强大的工具,其命令也有很多功能特色选项,我们下面就对它的选项一一进行分析说明。
默认地,rsync 在同步时并不会删除目标目录的文件。例如,你的源目录(被同步目录)中删除了一个文件,但是用 rsync 同步时,它并不会删除同步目录中的相同文件。 rsync -arv --delete可以删除
「用 rsync 备份到同一台电脑的其他目录:」
$ rsync -arv Images/ backups
-a:保留文件的所有信息,包括权限,修改日期,等等。a 是 archive 的缩写,是「归档」的意思-r:递归调用。表示子目录的所有文件也都包括。r 是 recursive 的缩写,是「递归」的意思-v:冗余模式。输出详细操作信息。v 是 verbose 的缩写,是「冗余的」意思
「用 rsync 备份到同步本地文件到服务器:」
$ rsync -arvz --progress --delete ~/Desktop/blog root@47.98.152.68:/home/yangjunning/
备份到七牛云
安装命令行工具(qshell)
进入家目录: cd ~下载压缩包: wget http://devtools.qiniu.com/qshell-linux-x86-v2.4.1.zip解压压缩包: unzip ~/qshell-linux-x86-v2.4.1.zip任何位置运行: mv ~/qshell-linux-x86-v2.4.1 /usr/local/bin/qshell权限: chmod +x /usr/local/bin/qshell删除压缩包: rm -rf ~/qshell-linux-x86-v2.4.1.zip
密钥设置
需要鉴权的命令都需要依赖七牛账号下的 AccessKey 和 SecretKey。所以这类命令运行之前,需要使用 account 命令来设置下 AccessKey ,SecretKey 。
$ qshell account -- ak sk name
注意:
ak、sk在七牛云「控制台」 -> 「个人中心」 - > 「密钥管理」内。
可以连续使用 qshell account 添加账号ak, sk, name信息,qshell会保存这些账号的信息, 可以使用qshell user命令列举账号信息,在各个账号之间切换, 删除账号等
账户管理
使用qshell user子命令可以用来管理记录的多账户信息。
qshell user ls可以列举账户下所有的账户信息qshell user cu可以用来切换账户qshell user cu不携带的话会切换到最近的上个账户;比如我在A账户做完操作后,使用qshell user cu B到了B 账户,那么使用qshell user cu可以切回到A账户
qupload2
同步数据到七牛空间, 带同步进度信息,和数据上传完整性检查(命令式),详情请查看文档
$ qshell qupload2 --src-dir=/var/lib/docker/volumes --bucket=my-docker-volumes