写论文查文献,我可算找到一个高效的办法

源 / 顶级程序员 文/ 小象君
“四月了,毕业论文写完了吗?”

论文关乎毕业,拿奖金、评职称、争取资金、争取项目,可谓是每个读书人的必经之路。
小象君在大学时候,经常看到这样的状况
写论文前:小意思!
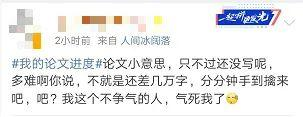

学员昵称:良
遇到的问题:
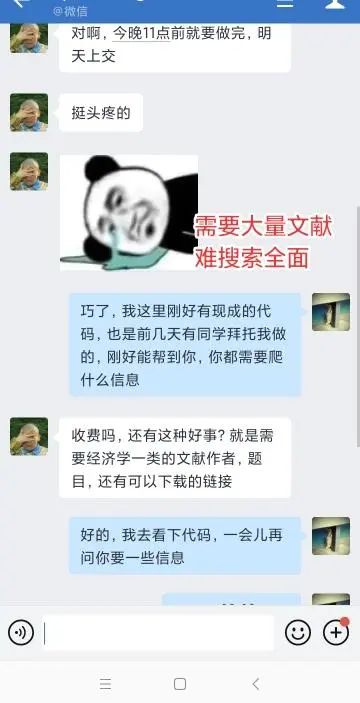

学习实录


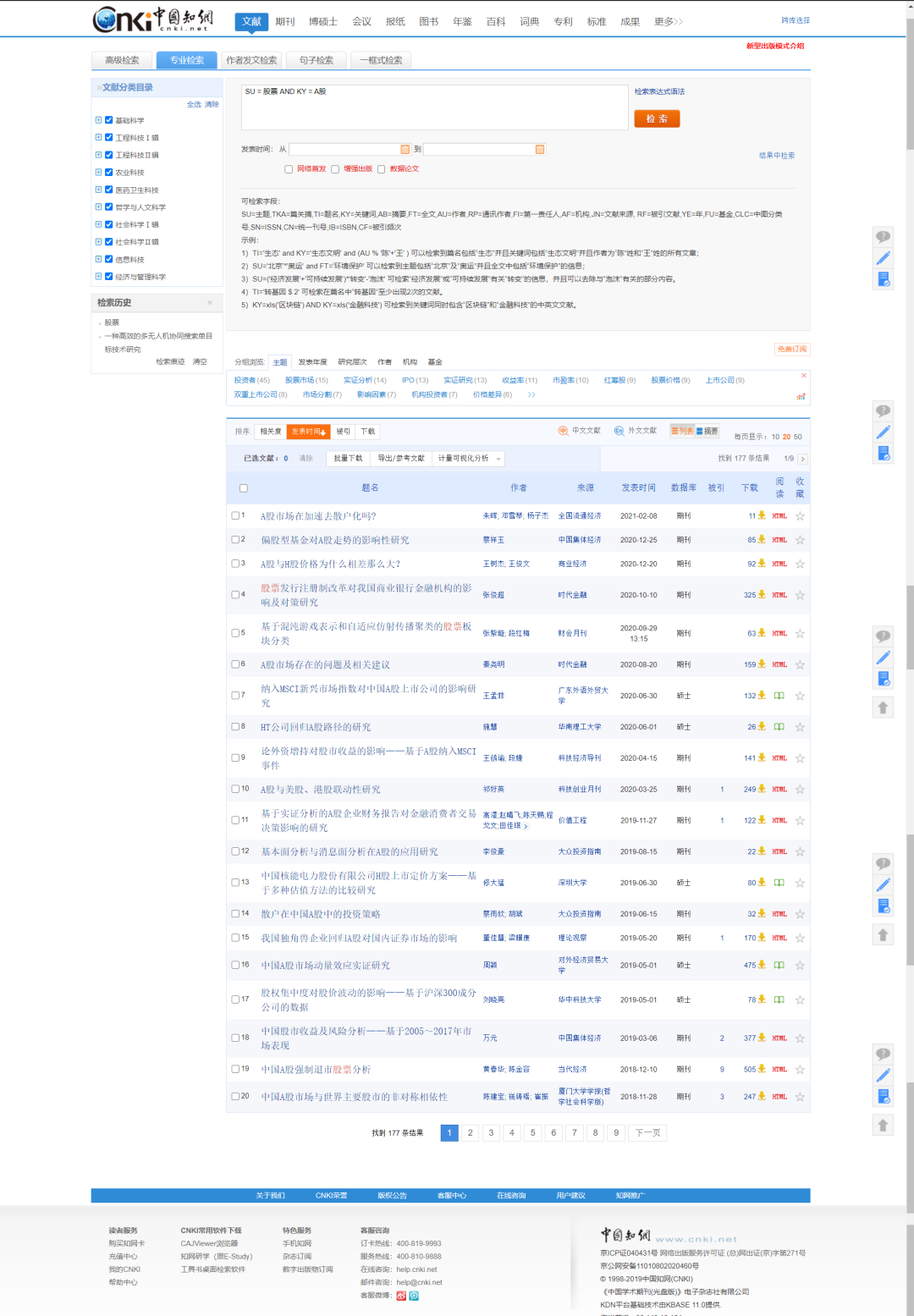

我们来看下结果
同学寄语
一键三连「分享」、「点赞」和「在看」
技术干货与你天天见~
评论
 下载APP
下载APP
源 / 顶级程序员 文/ 小象君
“四月了,毕业论文写完了吗?”
论文关乎毕业,拿奖金、评职称、争取资金、争取项目,可谓是每个读书人的必经之路。
小象君在大学时候,经常看到这样的状况
写论文前:小意思!
学员昵称:良
遇到的问题:
学习实录
我们来看下结果
同学寄语
一键三连「分享」、「点赞」和「在看」
技术干货与你天天见~