
盘点一个Python网络爬虫的问题(抓知乎)
回复“资源”即可获赠Python学习资料
大家好,我是皮皮。
一、前言
前几天在Python钻石交流群【此类生物】问了一个Python网络爬虫的问题,提问截图如下:
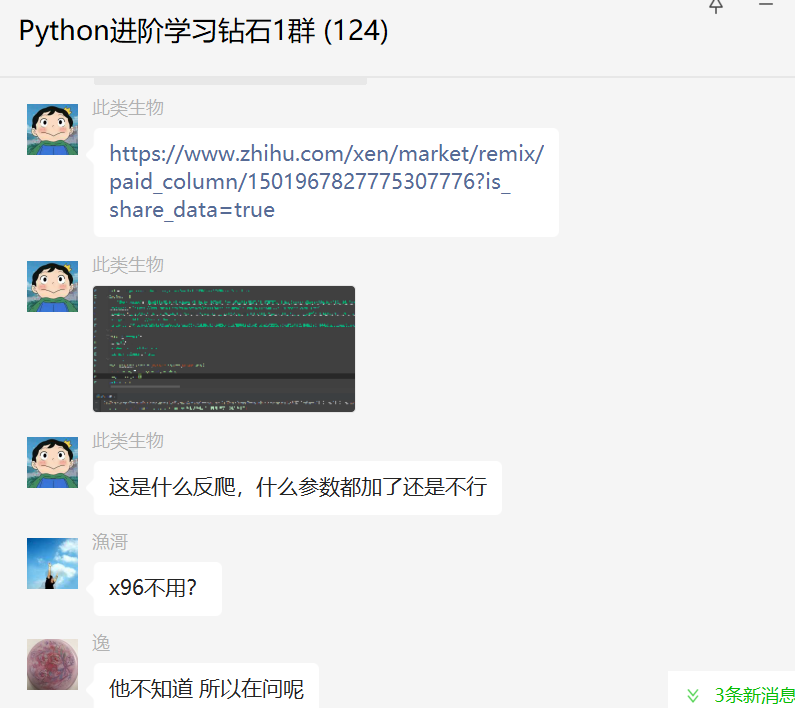
其实这个就是在抓知乎,知乎上是有反爬的,而且是那种JS加密的,属于有点难度的了。
二、实现过程
他需要爬这个小说所有章节名,id号。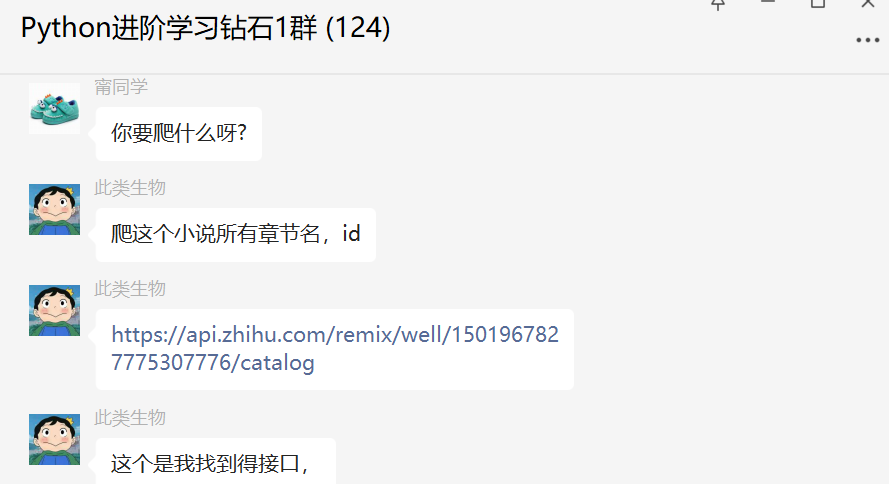
这里【甯同学】给了一个代码,后来发现是粉丝自己在请求的时候参数不全,导致没拿到数据。
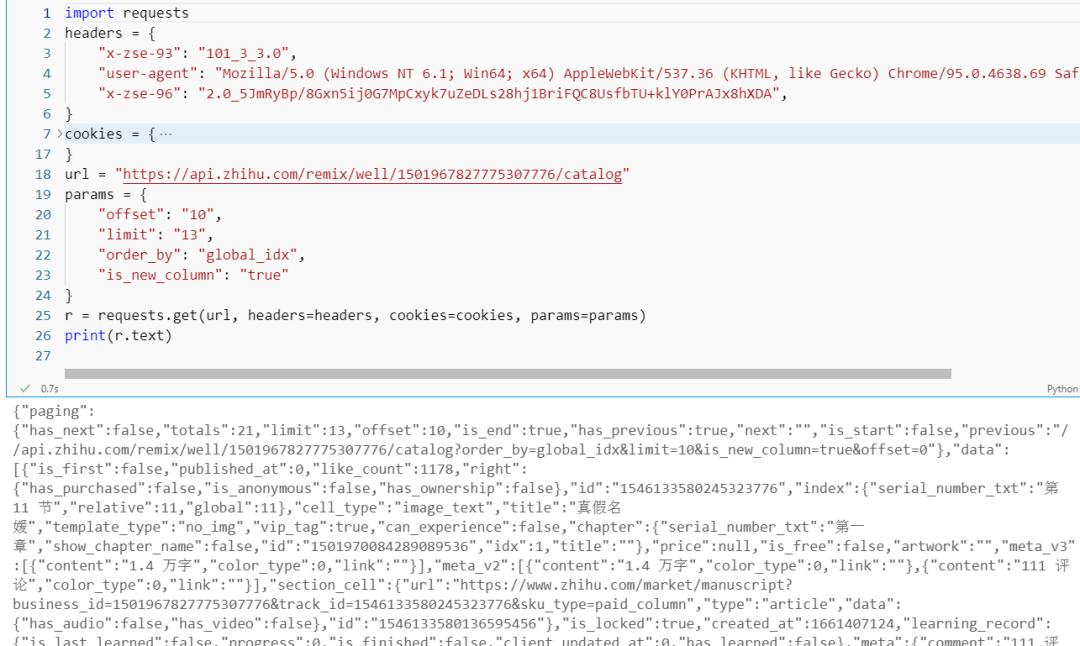
知乎的请求参数中确实是有一个参数是加密的了。
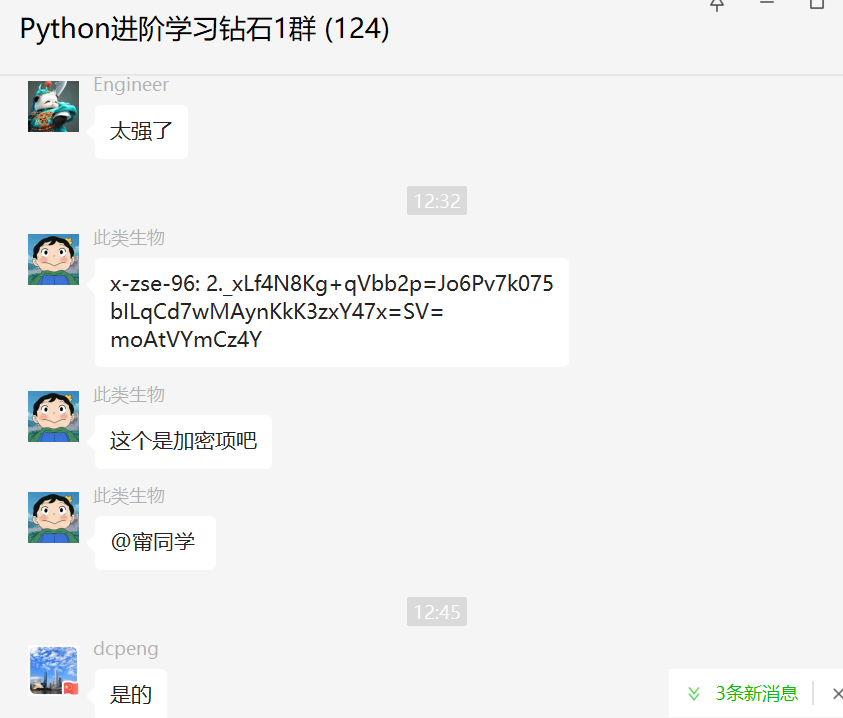
关于知乎抓取,一般我推荐使用八爪鱼,另外就是使用补环境的方法,把加密的JS文件单独放本地,然后去发起请求。这个代码网上倒是挺多的,应该还是可以用的。
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python网络爬虫的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【此类生物】提问,感谢【漁滒】、【甯同学】给出的思路和代码解析,感谢【逸 】、【dcpeng】、【产后修复】、【Engineer】等人参与学习交流。
大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的微信:pdcfighting),应粉丝要求,我创建了一些高质量的Python付费学习交流群,欢迎大家加入我的Python学习交流群!

有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
评论