
SpringBoot之旅-数据访问
JAVA烂猪皮
共 11001字,需浏览 23分钟
·
2023-08-01 10:10
<!--JDBC --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId></dependency><!--mysql 驱动--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><scope>runtime</scope></dependency>
@Autowiredprivate DataSource dataSource;@Testpublic void test() throws SQLException {System.out.println(dataSource.getClass());Connection connection = dataSource.getConnection();System.out.println(connection);connection.close();}
spring:datasource:schema:- classpath:department.sql
@AutowiredJdbcTemplate jdbcTemplate;@Testpublic void jdbcTest(){List<Map<String, Object>> mapList = jdbcTemplate.queryForList("select * from user ");System.out.println(mapList.get(0));}
<!-- https://mvnrepository.com/artifact/com.alibaba/druid --><dependency><groupId>com.alibaba</groupId><artifactId>druid</artifactId><version>1.1.16</version></dependency>
type: com.alibaba.druid.pool.DruidDataSource# 数据源其他配置initialSize: 5minIdle: 5maxActive: 20maxWait: 60000timeBetweenEvictionRunsMillis: 60000minEvictableIdleTimeMillis: 300000validationQuery: SELECT 1 FROM DUALtestWhileIdle: truetestOnBorrow: falsetestOnReturn: falsepoolPreparedStatements: true# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙filters: stat,wall,log4jmaxPoolPreparedStatementPerConnectionSize: 20useGlobalDataSourceStat: trueconnectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
@Configurationpublic class DruidConfig {@ConfigurationProperties(prefix = "spring.datasource")@Beanpublic DataSource druid(){return new DruidDataSource();}}

<!-- https://mvnrepository.com/artifact/log4j/log4j --><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency>
//配置Druid的监控//1、配置一个管理后台的Servlet@Beanpublic ServletRegistrationBean statViewServlet(){ServletRegistrationBean bean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*");Map<String,String> initParams = new HashMap<>();initParams.put("loginUsername","admin");initParams.put("loginPassword","123456");initParams.put("allow","");//默认就是允许所有访问initParams.put("deny","192.168.15.21");bean.setInitParameters(initParams);return bean;}//2、配置一个web监控的filter@Beanpublic FilterRegistrationBean webStatFilter(){FilterRegistrationBean bean = new FilterRegistrationBean();bean.setFilter(new WebStatFilter());Map<String,String> initParams = new HashMap<>();initParams.put("exclusions","*.js,*.css,/druid/*");bean.setInitParameters(initParams);bean.setUrlPatterns(Arrays.asList("/*"));return bean;}
<dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>1.3.1</version></dependency>
@Mapperpublic interface DepartmentMapper {@Select("select * from department where id=#{id}")Department getDeptById(Integer id);@Delete("delete from department where id=#{id}")int deleteDeptById(Integer id);@Options(useGeneratedKeys = true,keyProperty = "id")@Insert("insert into department(departmentName) values(#{departmentName})")int insertDept(Department department);@Update("update department set departmentName=#{departmentName} where id=#{id}")int updateDept(Department department);}
@AutowiredUserMapper userMapper;@AutowiredDepartmentMapper departmentMapper;@Testpublic void mybatisTest(){Department deptById = departmentMapper.getDeptById(1);System.out.println(deptById);}
@Mapperpublic interface UserMapper {User queryUserById(Integer id);}
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE configurationPUBLIC "-//mybatis.org//DTD Config 3.0//EN""http://mybatis.org/dtd/mybatis-3-config.dtd"><configuration></configuration>
mybatis:config-location: classpath:mybatis/SqlMapConfig.xmlmapper-locations: classpath:mybatis/mapper/*.xml
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd"><mapper namespace="com.yuanqinnan.mapper.UserMapper"><select id="queryUserById" parameterType="int" resultType="com.yuanqinnan.model.User">SELECT * FROM `user`where id=#{id}</select></mapper>
@Testpublic void mybatisTest(){Department deptById = departmentMapper.getDeptById(1);System.out.println(deptById);User userById = userMapper.queryUserById(1);System.out.println(userById);}
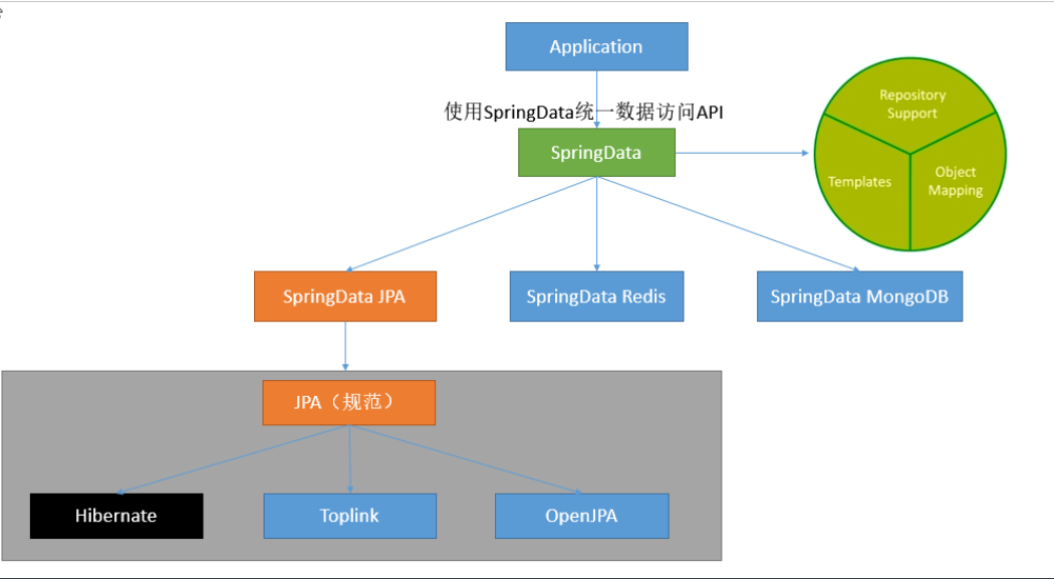
<!-- springdata jpa依赖 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency>
//使用JPA注解配置映射关系@Entity //告诉JPA这是一个实体类(和数据表映射的类)@Table(name = "order") //@Table来指定和哪个数据表对应;order;@Datapublic class Order {@Id //这是一个主键@GeneratedValue(strategy = GenerationType.IDENTITY)//自增主键private Integer id;@Column(name = "user_Id")private Integer userId;//这是和数据表对应的一个列@Column(name="number",length = 32)private String number;// 订单创建时间,省略默认列名就是属性名private Date createtime;// 备注private String note;}
@Repositorypublic interface OrderRepository extends JpaRepository<Order, Integer> {}
@AutowiredOrderRepository orderRepository;@Testpublic void jpaTest(){List<Order> all = orderRepository.findAll();System.out.println(all);}
剩下的就不会给大家一展出来了,以上资料按照一下操作即可获得
——将文章进行转发和评论,关注公众号【Java烤猪皮】,关注后继续后台回复领取口令“ 666 ”即可免费领文章取中所提供的资料。

腾讯、阿里、滴滴后台试题汇集总结 — (含答案)
面试:史上最全多线程序面试题!
最新阿里内推Java后端试题
JVM难学?那是因为你没有真正看完整这篇文章

关注作者微信公众号 — 《JAVA烤猪皮》
了解了更多java后端架构知识以及最新面试宝典
看完本文记得给作者点赞+在看哦~~~大家的支持,是作者来源不断出文的动力~
评论