
手撸双链表,图解
共 8664字,需浏览 18分钟
·
2021-03-27 12:21
跟单链表不同,双链表的节点包含两个指针,一个指针指向上一个元素,一个指针指向下一个元素。
▌如下图
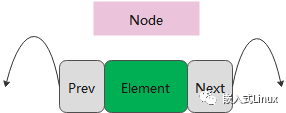
学习数据结构的时候,要像认识一个人一样,要了解这个人有什么特点,比如喜欢打球,喜欢喝酒之类的。学习数据结构也是一样,要了解数据结构的特点。
我们要学习双链表,需要搞明白链表这几个特点
创建链表
往链表插入数据
删除链表中的某个数据
删除整个链表
查找链表
反转链表
▌先看看如何创建一个链表
创建一个链表无非就是搞定链表头,没有头的链表就是死链表,有头就表示这个链表是存在的。当然了,可能会存在循环链表,只有位置,没有固定的头指针。
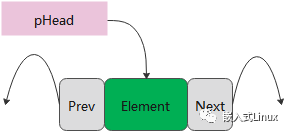
创建一个pHead,并且以后pHead头指针保持不动,就表示我们创建好了一个链表头指针。
typedef struct Node{
struct Node *prev;
struct Node *next;
int elements;
}pNode;
pNode * CreateHead(void)
{
pNode *head = NULL;
head = (pNode *)malloc(sizeof(struct Node));
head->next = NULL;
head->prev = NULL;
return head;
}
▌插入元素
插入元素的方式有多种,可以头插,可以尾插,也可以任意插,我只写了简单的插入方式-尾插。
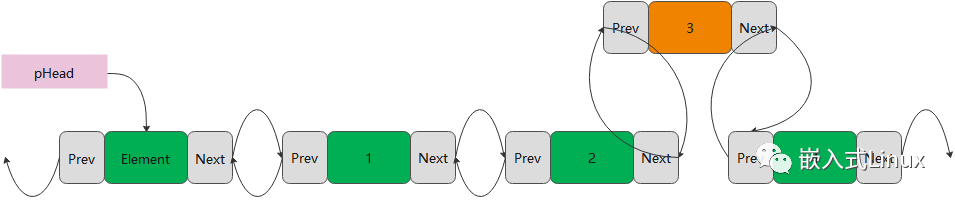
int InsertElement(pNode *head,int element)
{
if(head == NULL)
{
PRINTK_LINK("Head NULL\n");
return (-1);
}
pNode * pTemp = head;
while(pTemp->next != NULL)
{
pTemp = pTemp->next;
}
pNode * pElement = (pNode *)malloc(sizeof(struct Node));
pElement->elements = element;
pTemp->next = pElement;
pElement->prev = pTemp;
PRINTK_LINK("Element:%d\n",element);
return (0);
}
▌遍历一个链表
遍历链表是常规的操作,但是遍历链表的方法有很多种,可以从头开始遍历,可以从尾部开始,在涉及二分查找的时候可以从中间某个位置开始遍历。虽然方法很多,但是我只写了一种方法,就是从头开始遍历链表,因为是最简单的。
int TraverseLink(pNode *head)
{
if(head == NULL)
{
PRINTK_LINK("Head NULL\n");
return (-1);
}
pNode * pTemp = head;
while(pTemp->next != NULL)
{
pTemp = pTemp->next;
PRINTK_LINK("Element:%d\n",pTemp->elements);
}
return (0);
}
▌删除链表
删除整个链表是把链表的每个元素都删除,并且把头也删除,并且把头指针指向NULL。如果需要找到链表中的某个元素并删除,就需要先找到链表中的元素,删除掉,并且把前后的两个元素连在一起。
int DeleteLink(pNode *head)
{
if(head == NULL)
{
PRINTK_LINK("Head NULL\n");
return (-1);
}
pNode * pTemp = head;
while(pTemp->next != NULL)
{
pTemp = pTemp->next;
}
while(pTemp != NULL)
{
free(pTemp);pTemp = NULL;
pTemp = pTemp->prev;
}
return (0);
}
▌完整代码
#include "stdio.h"
#include "string.h"
#include "stdlib.h"
#define LOG_TAG "[LINK]: %s() line: %d "
#define PRINTK_LINK(fmt, args...) printf(LOG_TAG fmt, __FUNCTION__, __LINE__, ##args)
typedef struct Node{
struct Node *prev;
struct Node *next;
int elements;
}pNode;
pNode * CreateHead(void)
{
pNode *head = NULL;
head = (pNode *)malloc(sizeof(struct Node));
head->next = NULL;
head->prev = NULL;
return head;
}
int InsertElement(pNode *head,int element)
{
if(head == NULL)
{
PRINTK_LINK("Head NULL\n");
return (-1);
}
pNode * pTemp = head;
while(pTemp->next != NULL)
{
pTemp = pTemp->next;
}
pNode * pElement = (pNode *)malloc(sizeof(struct Node));
pElement->elements = element;
pTemp->next = pElement;
pElement->prev = pTemp;
PRINTK_LINK("Element:%d\n",element);
return (0);
}
int TraverseLink(pNode *head)
{
if(head == NULL)
{
PRINTK_LINK("Head NULL\n");
return (-1);
}
pNode * pTemp = head;
while(pTemp->next != NULL)
{
pTemp = pTemp->next;
PRINTK_LINK("Element:%d\n",pTemp->elements);
}
return (0);
}
int DeleteLink(pNode *head)
{
if(head == NULL)
{
PRINTK_LINK("Head NULL\n");
return (-1);
}
pNode * pTemp = head;
while(pTemp->next != NULL)
{
pTemp = pTemp->next;
}
while(pTemp != NULL)
{
free(pTemp);
pTemp = pTemp->prev;
}
return (0);
}
int main()
{
pNode * pHead = CreateHead();
InsertElement(pHead,13);
InsertElement(pHead,8);
InsertElement(pHead,0);
InsertElement(pHead,4);
InsertElement(pHead,485);
InsertElement(pHead,94);
TraverseLink(pHead);
DeleteLink(pHead);
return 0;
}
▌程序输出
ubuntu1804:~/c$ gcc shuanglianbiao.c && ./a.out
[LINK]: InsertElement() line: 40 Element:13
[LINK]: InsertElement() line: 40 Element:8
[LINK]: InsertElement() line: 40 Element:0
[LINK]: InsertElement() line: 40 Element:4
[LINK]: InsertElement() line: 40 Element:485
[LINK]: InsertElement() line: 40 Element:94
[LINK]: TraverseLink() line: 56 Element:13
[LINK]: TraverseLink() line: 56 Element:8
[LINK]: TraverseLink() line: 56 Element:0
[LINK]: TraverseLink() line: 56 Element:4
[LINK]: TraverseLink() line: 56 Element:485
[LINK]: TraverseLink() line: 56 Element:94
▌总结
我上面的代码只设计了链表头,如果设计链表尾部指针,应用会更加灵活。
相比于单链表,双链表的操作会更加灵活,当然,每一个节点都需要新增一个指向于上一个位置的指针。
双链表还可以把头尾连接起来变成一个环形队列。
链表相对于数组来说,插入和删除数据非常快,因为不需要移动数据,只需要改变指针的指向。
双链表内存利用率高,如果是内存紧张的硬件设备,使用链表操作可以节省内存。相对于数组,链表可以做到按需分配内存。
链表是一种基础的数据结构,建议做到自己能写出一个链表,不要求十全十美,我曾经面试遇到让我手撸一个栈。相对于那些C语言基础,写代码更能彰显程序员的技术。
