
超越YOLO v5的最强算法矩阵来啦!PP-YOLOE、PP-PicoDet 云边端一网打尽!
目标检测作为计算机视觉领域的顶梁柱,不仅可以独立完成车辆、商品、缺陷检测等任务,也是人脸识别、视频分析、以图搜图等复合技术的核心模块,在自动驾驶、工业视觉、安防交通等领域的商业价值有目共睹。
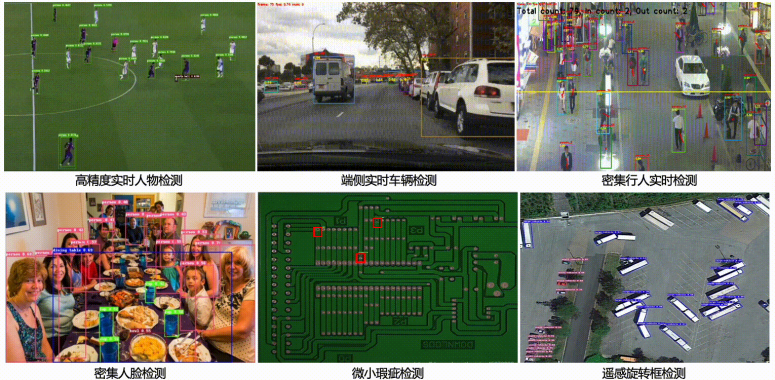
在当前云、边、端多场景协同的产业大趋势下,运行速度、模型计算量、模型格式转化、硬件适配、统一部署方案等实际问题都需要考虑。而今天小编给大家推荐的全新发布的PP-YOLOE和PP-PicoDet增强版,相比YOLOv5、YOLOX等优秀算法,再一次将性能推到极致。
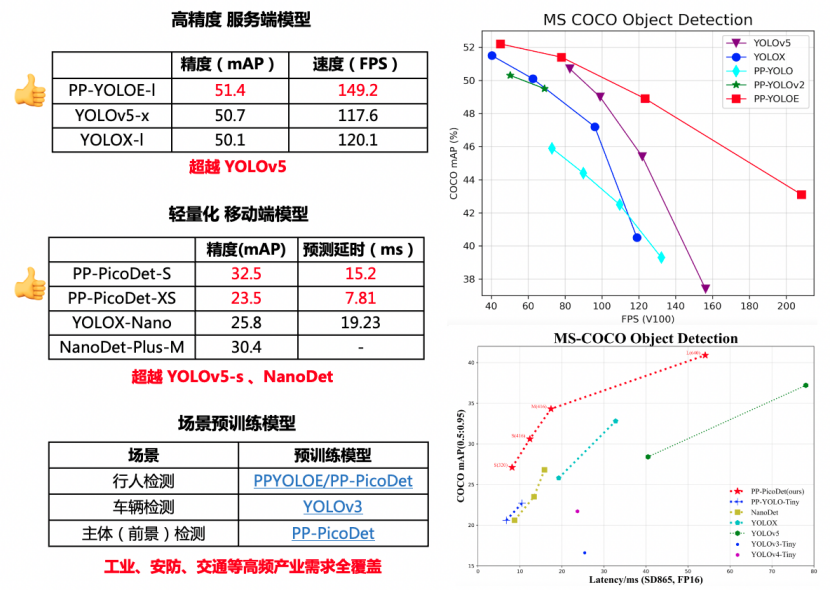
无论你追求的是高精度、轻量化,还是场景预训练模型,PP-YOLOE和PP-PicoDet增强版都能以业界超高标准满足你的需求。同时,统一的使用方式及部署策略,让你不再需要进行模型转化、接口调整,更贴合工业大生产标准化、模块化的需求。
还在等什么!赶紧查看全部开源代码并Star收藏吧!!
传送门:
https://github.com/PaddlePaddle/PaddleDetection

PP-YOLOE根据不同应用场景设计了s/m/l/x,4个尺寸的模型来支持不同算力水平的硬件,无论是哪个尺寸,精度-速度都超越当前所有同等计算量下的YOLO模型!
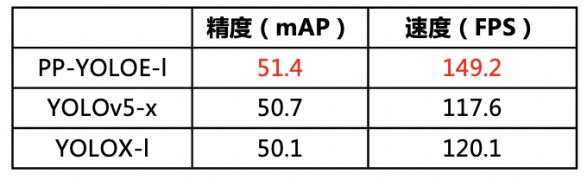
✦性能卓越:具体来说,PP-YOLOE-l在COCO test-dev上以精度51.4%,TRT FP16推理速度149.2FPS的优异数据,相较YOLOX,精度提升1.3%,加速25%;相较YOLOv5,精度提升0.7%,加速26.8%。训练速度较PP-YOLOv2提高33%,大幅降低模型训练成本。
✦部署友好:与此同时,PP-YOLOE在结构设计上避免使用如deformable convolution或者matrix nms之类的特殊算子,使其能轻松适配更多硬件。当前已经完备支持NVIDIA V100、T4这样的云端GPU架构以及如Jetson系列等边缘端GPU和FPGA开发板。
下面,就让我们来一起看看具体是哪些策略给PP-YOLOE带来了如此显著的提升:
✔可扩展的backbone和neck:自研CSPRepResNet和CSPPAN k,在增强模型表征能力的同时提升了模型的推理速度,并且可以灵活地配置模型大小。
✔更高效的标签分配策略TAL(Task Alignment Learning):使匹配结果可以同时获得最优的分类score和定位精度。
✔更简洁有效的ET-Head(Efficient Task-aligned Head): 基于TOOD的Head,使用ESE替换T-Head中的注意力模块,并使用shortcut和DFL分别进行分类和回归的对齐。在损失函数方面,则使用VFL替换BCE,保证了速度精度双高的目的。
PP-YOLOE完整代码实现:
https://github.com/PaddlePaddle/PaddleDetection/tree/release/2.4/configs/ppyoloe
技术报告:
https://arxiv.org/abs/2203.16250
超乎想象的超小体积及超预期的性能,使PP-PicoDet成为边缘、低功耗硬件部署的最佳选择,而此次发布更是在原有基础上再次升级:
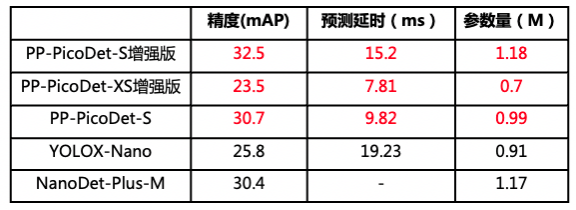
✔更高精度:PP-PicoDet作为业界首个1M内,实现精度mAP(0.5:0.95)超越30+的模型,升级后整体精度提高2%。PP-PicoDet-S参数量仅有1.18M,却有32.5%mAP的精度,相较YOLOX-Nano高6.7%,推理速度提升了26%;相较NanoDet-Plus,相同参数量下,mAP高出2.1%
✔更快速度:在CPU上预测速度再次提升50%,最新增加的PP-PicoDet-XS更是仅有0.7M,在CPU上预测速度达到250FPS以上,与此同时训练速度也大幅提升一倍以上
✔更友好部署:为了部署更加轻松高效, PP-PicoDet在模型导出环节, 将模型的后处理包含在了网络中,支持预测直接输出检测结果,无需额外开发后处理模块,还能端到端加速10%-20%
✔更高效优化支持:考虑到端侧对计算量的优化追求是极致的,PP-PicoDet在模型量化训练和稀疏化压缩方案支持方面做了更深度的打磨, 仅需两步,即可实现在移动端部署加速30%以上的效果。
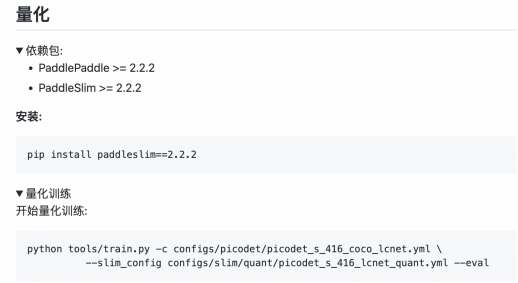
PP-PicoDet代码实现:
https://github.com/PaddlePaddle/PaddleDetection/tree/release/2.4/configs/picodet
技术报告地址:
https://arxiv.org/abs/2111.00902
以上所有模型、代码及使用文档、Demo均在PaddleDetection中开源提供,此外如YOLOv4、YOLOX及SwinTransformer等在内的前沿优秀算法与Faster-RCNN、YOLOv3等经典算法也被收录其中,并且提供了极致简单、统一的使用方式。
部署方面得益于飞桨原生推理库Paddle Inference及飞桨端侧推理框架Paddle Lite的能力,通过支持TensorRT和OpenVino,开发者可以快速完成在服务端和边缘端GPU或ARM CPU、NPU等硬件上的高性能加速部署。
此外,PaddleDetection还支持一键导出为ONNX格式,顺畅对接ONNX生态。

从此无需再内卷,通用目标检测,
这一个项目就够了!
✦赶紧Star收藏订阅最新动态吧!✦
https://github.com/PaddlePaddle/PaddleDetection/tree/release/2.4
为了让开发者们更深入的了解PaddleDetection这次的全新模型,解决落地应用难点,掌握产业实践的核心能力,飞桨团队精心准备了为期三天的直播课程!
4月19日20:30,百度资深高工将为我们详细介绍超强检测矩阵,对各类型SOTA模型的原理及使用方式进行拆解,之后两天还有检测拓展应用梳理及产业案例全流程实操,对各类痛难点解决方案进行手把手教学,加上直播现场互动答疑,还在等什么!抓紧扫码上车吧!

