
万字长文:重温机器学习经典算法
点击上方“机器学习算法工程师”
选择“星标”公众号,重磅干货,第一时间送达
一、强化学习的概念和主要用途
1.什么是强化学习?
强化学习(Reinforcement Learning)是机器学习的一个非常重要的分支,其核心思想是实验者构建一个完整的实验环境,在该环境中通过给予被实验者一定的观测值和回报等方法来强化或鼓励被实验者的一些行动,从而以更高的可能性产生实验者所期望的结果或目标。从以上对强化学习的描述中,我们可以看出强化学习一定会涉及到被实验者(也称为智能体,Agent)、实验者构建的环境(也就是系统环境,System Environment)、被实验者的观测值(也称为环境状态,State)、被实验者的行动(Action)和回报(也称为奖励或反馈,Reward)这五个关键要素。
举一个经典的心理学实验来进一步解释强化学习所涉及到的这几个关键要素。这个实验就是巴浦洛夫的狗,在实验中每次实验者都对着狗摇铃铛,并给它一点食物。久而久之,铃铛和食物的组合就潜移默化地影响了狗的行动,此后每次对着狗摇铃铛,狗就会不由自主的流口水,并期待实验者能给它食物,通过这样的方法,实验者就让狗学会了铃铛和食物之间的关系,这算作是强化学习的一个简单的例子。
从这个例子中我们不光能看出强化学习所涉及到的以上描述的五个关键要素,并且还能得到一个包含这五个关键要素的高度抽象的强化学习的框架,那就是: 在经典的强化学习中,智能体是要和实验者构建的系统环境完成一系列的交互,主要包含以下三项内容:
1. 在每一时刻,环境都处于一种状态,智能体能得到环境当前状态的观测值; 2. 智能体根据当前环境状态的观测值,并结合自己历史的行为准则(一般称为策略,Policy)做出行动; 3. 智能体做出的这个行动又继而会使环境状态发生一定的改变,同时智能体又会获取到新的环境状态的观测值和这个行动所带来的回报,当然这个回报既可以是正向的也可以是负向的,这样智能体就会根据新的状态观测值和回报来继续做出新的行动,直至达到实验者所期望的目标为止。 因此,高度抽象的强化学习的框架所包含的整个过程如图1所示:
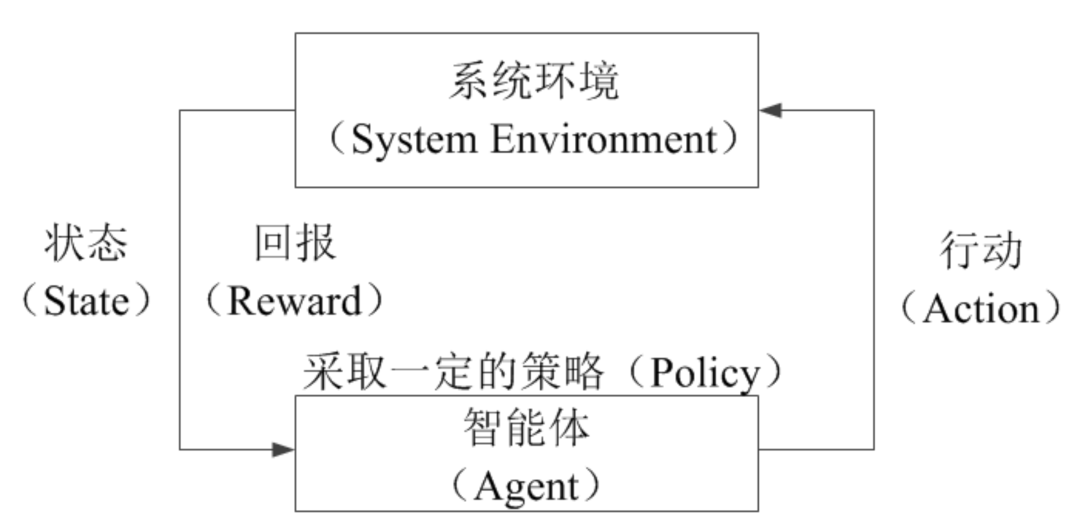
图1 强化学习的过程表示
所以,站在智能体的角度,强化学习的目标就是最大化所获得的回报。但是这个目标有些抽象,因此我们需要把这个目标变得更容易量化。这时不得不讲强化学习的两个显著的特点,一是不断试错,根据环境状态做出行动的智能体有时得到较多回报,有时回报又比较少,甚至还有可能得到负值的回报,因此智能体需要根据回报的多少不断调整自己的策略以获得尽可能多的回报,这个过程中就需要智能体不断尝试应对环境状态的各种可能的行动,并收集对应的回报,只有借助这些反馈信息智能体才能更好地完成学习任务;二是看重长期回报,而不追逐短期的得分(例如,围棋游戏中为了最终战胜对方,游戏中可能会做出一些被对方吃掉棋子的看似不好的行动),这通常就需要智能体和系统环境进行长时间的交互,所以追求长期回报就需要多探索和不断尝试,也有可能遇到更多的失败。
基于强化学习这两个特点,我们在评价强化学习算法的优劣时,除了常规的衡量指标(比如,算法效果、稳定性和泛化性)以外,还需重点关注另一个指标,就是学习时间。由于强化学习与不断试错和看重长期回报相关,所以学习时间一般也可由强化学习算法尝试和探索的次数代替。 因此,根据以上一系列的描述,强化学习可以简洁地归结为:根据环境状态、行动和回报,不断试错学习出最佳的策略来让智能体做出行动,并以最终结果为目标,不只看某个行动当下带来的回报,而更要看到这个行动未来所能带来的潜在回报。
2.强化学习能用来干什么?
强化学习主要是用来解决一系列决策问题的,因为它可以在复杂、不确定的环境中学习如何实现我们所设定的目标。强化学习的应用场景非常广,几乎包含了所有需要做决策的问题,比如控制机器人的电机来执行特定的任务、无人驾驶中在当前道路状态上做出最该执行的行动(如加减速和转换方向等)、商品定价和库存管理以及玩视频游戏或棋牌游戏。其中,掀起强化学习研究热潮的当属大名鼎鼎的AlphaGo,它是由谷歌公司的DeepMind团队结合了策略网络(Policy Network)、估值网络(Value Network)与蒙特卡洛搜索树(Monte Carlo Tree Search),实现的具有超高水平的进行围棋对战的深度强化学习程序,自打问世就一举战胜人类世界围棋冠军李世石,并一战成名。
其中,强化学习中两类重要的方法分别是策略迭代法(Policy-Based 或 Policy Gradients)和价值迭代法(Value-Based 或 Q-Learning)。这两种方法的主要区别在Policy-Based方法直接预测在某个环境状态下应该采取的行动,而Value-Based方法预测在某个环境状态下所有行动的期望价值(也就是Q值),之后选择Q值最高的行动来执行。一般来说,Value-Based方法适合仅有少量离散取值的行动的问题,而Policy-Based方法则更加通用,适合可采取行动的种类非常多或有连续取值的行动的问题。
二、机器学习几类常见算法的辨析
有监督学习是一种经典的机器学习方法,其核心思想是通过一定数量的训练样本学习出一个能根据给定的输入得到对应输出的模型,值得一提的是,这些训练样本包含了一对对输入和已知输出的数据,有监督学习就是使用这样一对对输入和输出数据来计算出模型的参数(比如,连接权重和学习率等参数),从而完成模型的学习。因此,从学习的目标来看,有监督学习是希望学习得到的模型能根据给定的输入得到相应的输出,而强化学习是希望智能体根据给定的环境状态得到能使回报最大化的行动。
以上描述中我们知道,有监督学习的效果除了依赖训练样本数据,更依赖于从数据中提取的特征,因为这类算法是需要从训练数据中计算出每个特征和预测结果之间的相关度。可以毫不夸张地说,同样的训练样本数据使用不同的表达方式会极大地影响有监督学习的效果,一旦有效解决了数据表达和特征提取的问题,很多有监督学习问题也就解决了90%。但是对于许多有监督学习问题来说,特征提取并不是一件简单的事情。在一些复杂的问题中,需要通过人工的方式来设计有效的特征集合,这样不光要花费很多的时间和精力,而且有时依赖人工的方式不能很好地提取出本质特征。那么是否能依赖计算机来进行自动提取特征呢?深度学习就应运而生,深度学习基本上是深层人工神经网络的一个代名词,其在图像识别、语音识别、自然语言处理以及人机博弈等领域的工业界和学术界均有非常出色的应用和研究,因此深度学习是有监督学习的一个重要分支。深度学习解决的核心问题有二个,一是可以像其他有监督学习一样学习特征和预测结果之间的关联,二是能自动将简单特征组合成更加复杂的特征。也就是说,深度学习能从数据中学习出更加复杂的特征表达,使得神经网络模型训练中的连接权重学习变得更加简单有效,如图2所示。
在图3中,深度学习展示了解决图像识别问题的样例,可以看出深度学习是从图像像素的基础特征中逐渐组合出线条、边、角、简单形状和复杂形状等复杂特征的。因此,深度学习是能一层一层地将简单特征逐步转化成更加复杂的特征,从而使得不同类别的图像更加可分。
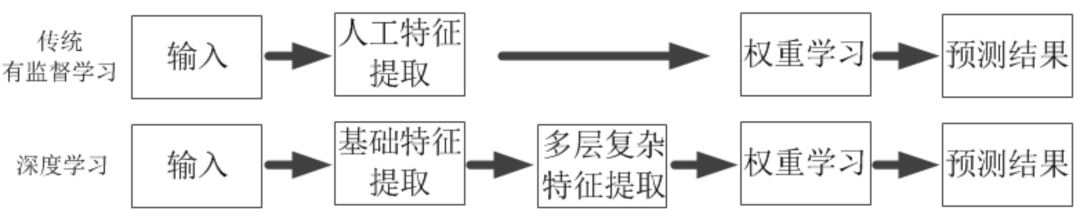
图2 深度学习和传统有监督学习流程比较
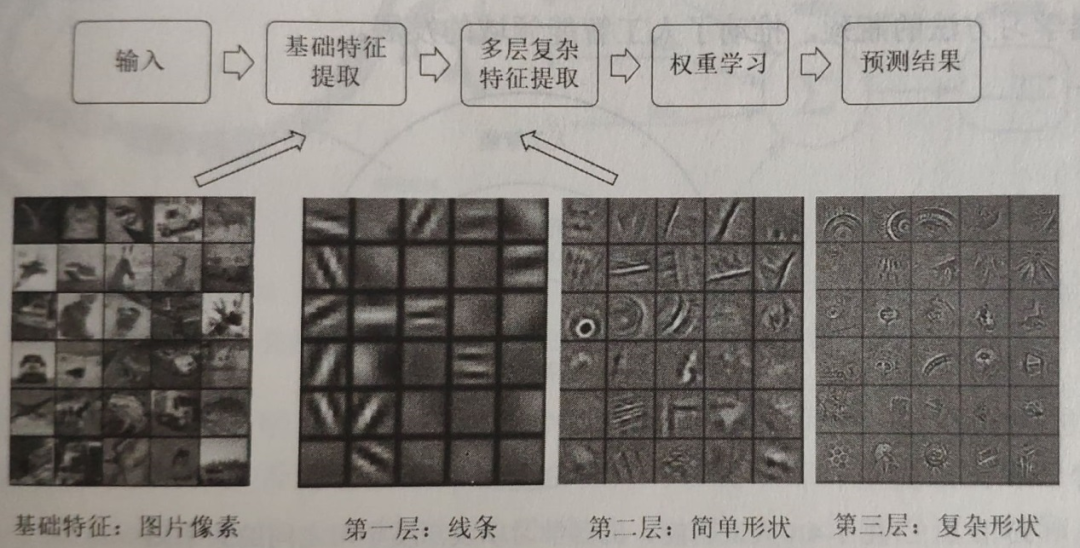
图3 深度学习在图像识别问题上的算法流程样例
此外,将深度学习和强化学习结合起来的深度强化学习更是近年来的研究热点,比如无人驾驶、机器人自主任务执行和人工智能打游戏等。深度强化学习本质上也是神经网络,只不过是在前几层中使用了卷积神经网络等深度学习算法来对摄像头捕获的图像进行识别、处理和分析,相当于能让智能体看得见环境并正确识别周围物体,之后再通过强化学习算法来预测出最该执行的一系列动作来使得回报最大化,从而完成既定的任务。
在人工智能领域还有一种机器学习算法同样很重要,那就是无监督学习,这类算法是在没有训练样本数据的情况下,对没有标定输出标签的数据进行分析并建立合适的模型以给出问题解决方案的,常见的无监督学习算法包括将样本特征变量降维的数据转换和把样本划归到不同分组的聚类分析。
因此,从以上对各类算法的描述中可以看出,强化学习跟有监督学习和无监督学习均有所不同。强化学习既不像有监督学习那样有非常明确的学习目标(一个输入对应的就是一个确定的输出),也不像无监督学习那样完全没有学习目标,而强化学习的目标一般是不明确的,因为在一定的环境状态下能获得最大回报的行动可能有很多。所以,这几类机器学习算法在学习目标的明确性上有本质的区别。此外,从时间维度上看,强化学习和有监督学习输出的意义不同。有监督学习主要看重的是输入和输出的匹配程度,如果输入和输出匹配,那么学习的效果就是比较好的,即便存在输入序列到输出序列的映射,有监督学习也希望每一时刻的输出都能和其输入对应上,比如,以俄罗斯方块游戏为例,如果采用有监督学习进行训练,那么有监督学习模型就会以每一帧游戏画面或状态作为输入,对应的输出当然也是确定的,要么移动方块,要么翻转方块;但是这种学习方式实际上有些死板,因为要想最终获得更多分数,其操作序列当然不止一种。
然而,强化学习主要看重的却是回报最大化,在智能体与环境交互过程中,并不是每一个行动都会获得回报,当智能体与环境完成了一次完整的交互后,会得到一个行动序列,但在序列中哪些行动为最终的回报产生了正向的贡献,哪些行动产生了负向的贡献,有时确实很难界定,比如,以围棋游戏为例,为了最终战胜对方,智能体在游戏中的某些行动可能会走一些不好的招法,让对方吃掉棋子,这是为达成最终目标而做出的牺牲,很难判定行动序列中的这些行动是优是劣。因此,强化学习的优势就在于学习过程中被强制施加的约束更少,影响行动的反馈虽然不如有监督学习直接了当,但是却能降低问题抽象的难度,而且还更看重行动序列所带来的的整体回报,而不是单步行动的即时收益。
实际上,有一种学习方法的目标和强化学习一致,都是最大化长期回报值,但其学习过程和有监督学习类似,收集大量的单步决策的样本数据,并让模型学习这些单步决策的逻辑,这类机器学习算法被称为“模仿学习”。如图4所示,模仿学习的执行流程为: (1)寻找一些“专家系统”代替智能体和环境的交互过程,得到一系列的交互序列; (2)假设这些交互序列为对应环境状态下的“标准答案”,就可以使用有监督学习让模型去学习这些数据,从而完成将环境状态和专家采取的行动相对应的工作。
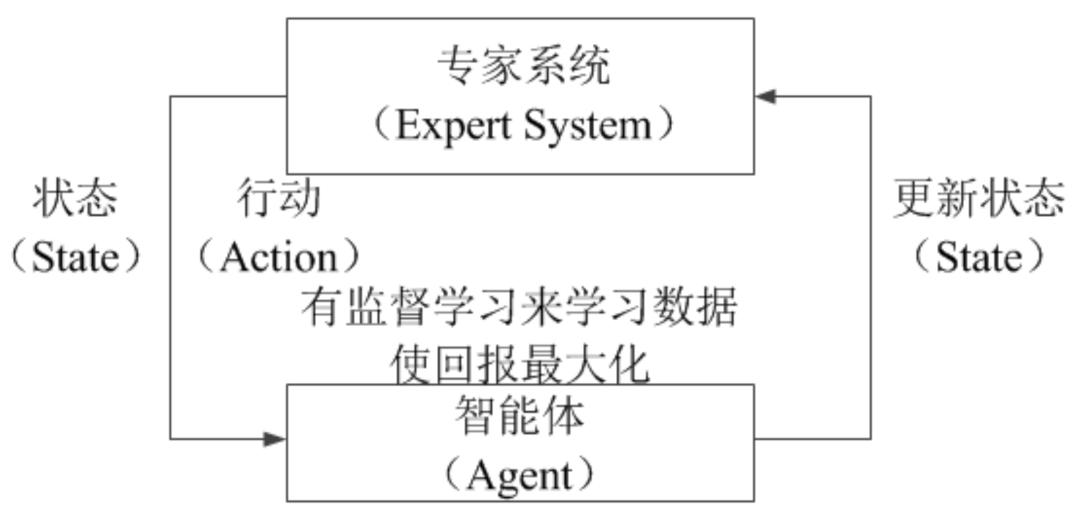
图4 模仿学习的执行流程图
模仿学习在一些问题上可以获得比较好的效果,但也有其弊端,那就是: (1)必须要在问题领域中存在一个专家,所有的训练样本数据都通过专家系统和环境交互产生; (2)必须要有足够多数量的训练样本数据,否则很难学习出一个效果好的行动策略模型; (3)必须确保学习得到的模型拥有足够的泛化性,否则在实际使用中遇到一些训练样本中没有出现的观测值,导致泛化能力不够的智能体出现重大决策失误; 为了解决以上存在的问题,模仿学习需要从训练样本和模型两方面入手。但实际上这三个问题在现实中都不太容易解决,因此模仿学习的难度并不小,这才使得研究潮流大部分都集中在强化学习上,就是希望强化学习能够解决模仿学习无法解决的问题。综上所述,人工智能领域中几类常见算法之间的关系如下图5所示:
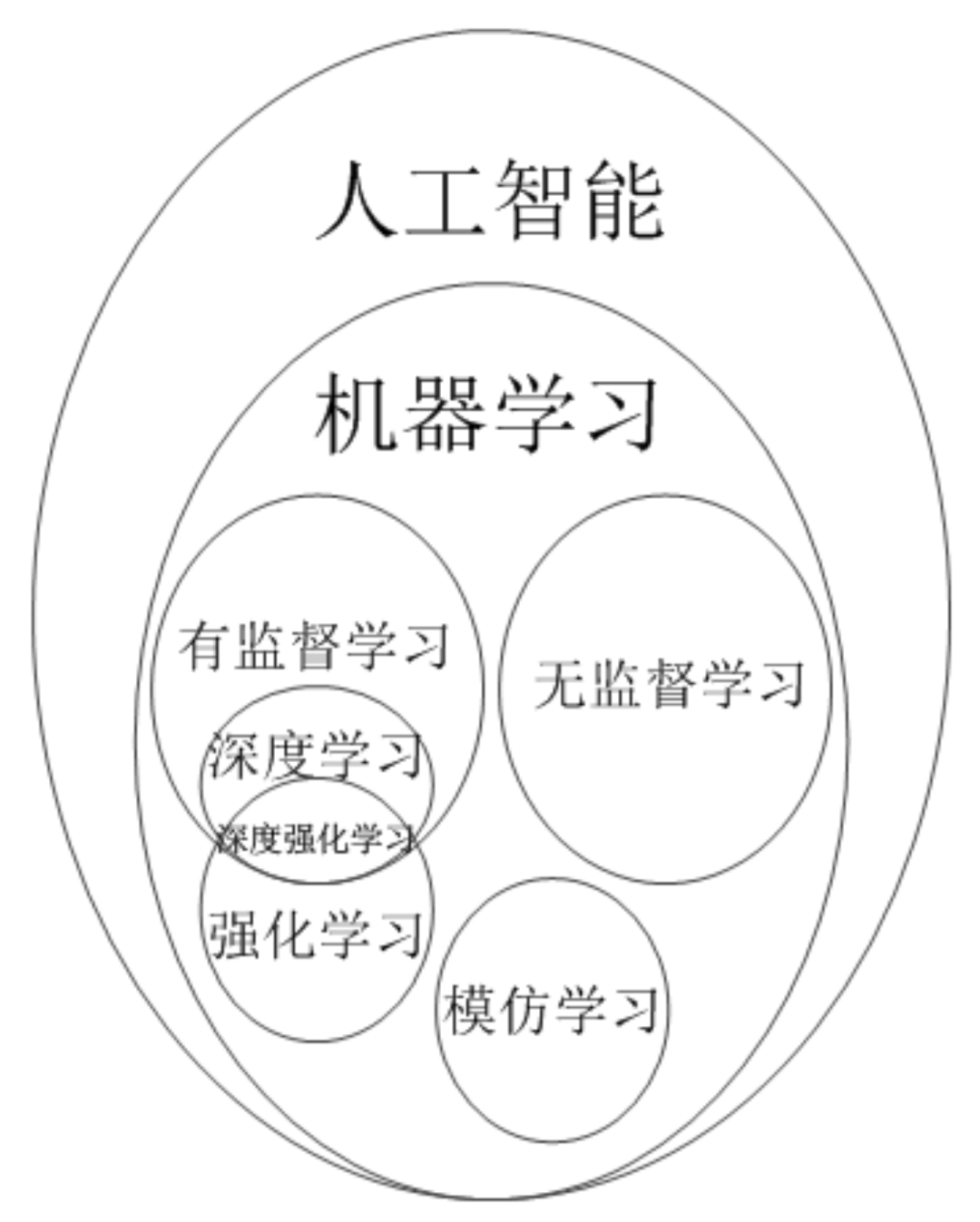
图5 人工智能中几类算法之间的关系图
现如今在工业界和学术界,受到人们广泛关注的机器学习计算框架就是谷歌公司在2015年11月9日正式开源的TensorFlow。相比其他的机器学习开源计算工具而言,TensorFlow计算框架能够很好地支持深度学习和强化学习等多种机器学习算法的实现。TensorFlow既是实现机器学习算法的接口,也是执行机器学习算法的框架,其在很多方面都有优异的表现,比如开发人员设计神经网络结构的代码简洁性和分布式机器学习算法的执行效率以及将训练好的模型部署的便利性。
此外,在强化学习中还要用到的另一个重要框架就是Gym以及在此框架上实现的算法集合Baselines。Gym是一个集成了众多强化学习实验环境的平台,在该平台上研究人员可以很方便地搭建起强化学习所需要的仿真环境,从而集中精力完成行动策略学习的主要工作。Baselines则基于TensorFlow和Gym实现了一些经典的强化学习算法。总而言之,Gym实现了强化学习中和系统环境这个关键要素相关的功能,而Baselines实现了与智能体这个关键要素相关的功能。 以上内容就是对强化学习的定义、高度抽象的框架、特点、主要用途、强化学习与其他几类主要机器学习算法的本质区别以及机器学习常用的搭建环境等内容的精要概述。
觉得不错,多多「留言」,点击「在看」吧↓↓↓
