
用了 Elasticsearch 后,查询起飞了!


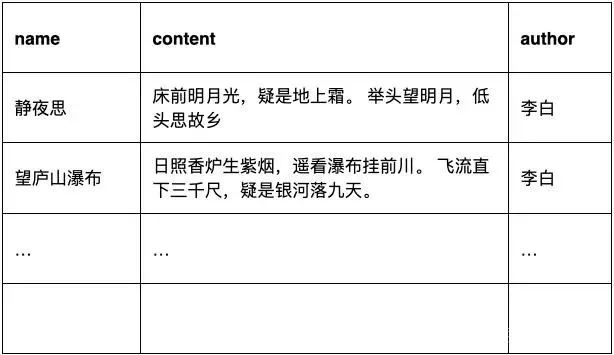
select name from poems where content like "%前%";
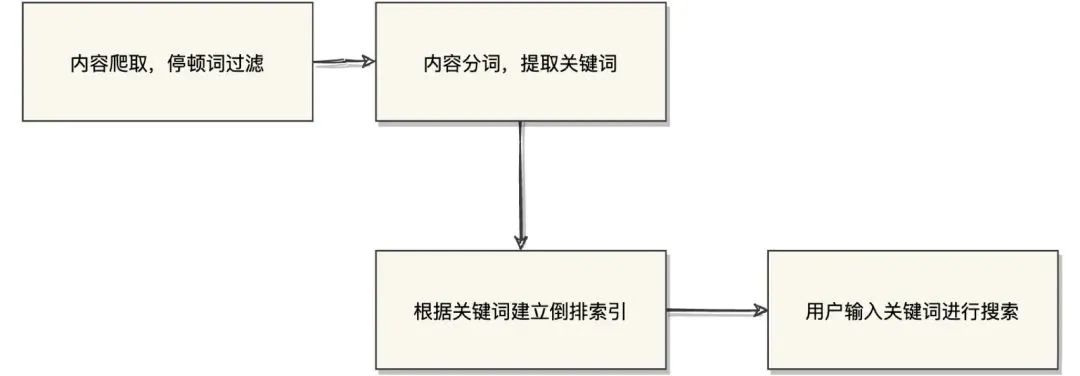
内容爬取,停顿词过滤,比如一些无用的像"的",“了”之类的语气词/连接词
内容分词,提取关键词
根据关键词建立倒排索引
用户输入关键词进行搜索
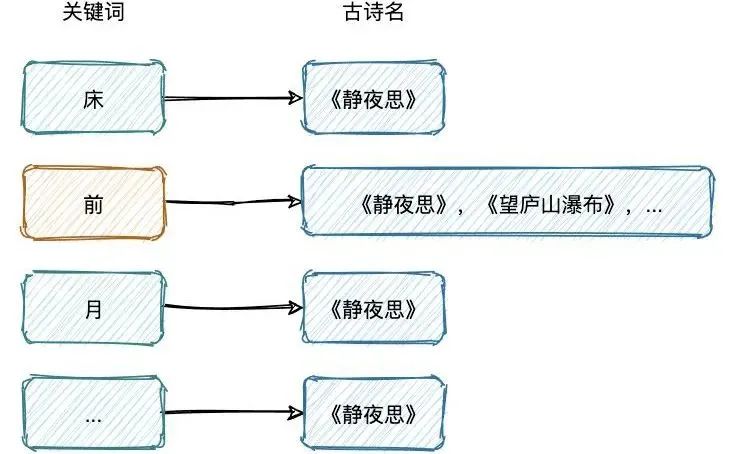
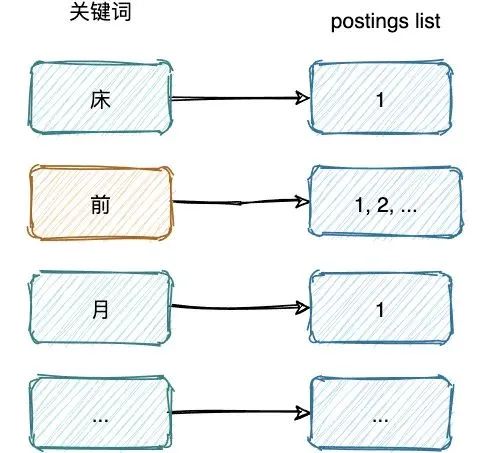
空间占用小,通过对词典中单词前缀和后缀的重复利用,压缩了存储空间
查询速度快,O(len(str)) 的查询时间复杂度。
postings list 如果不进行压缩,会非常占用磁盘空间
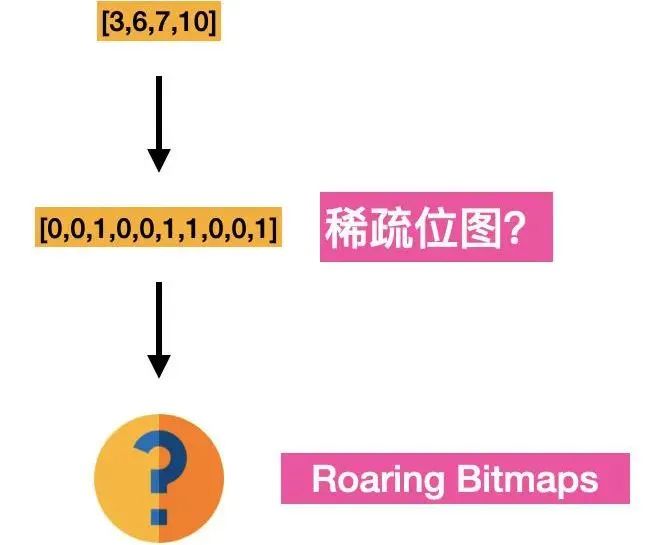
联合查询下,如何快速求交并集(intersections and unions)

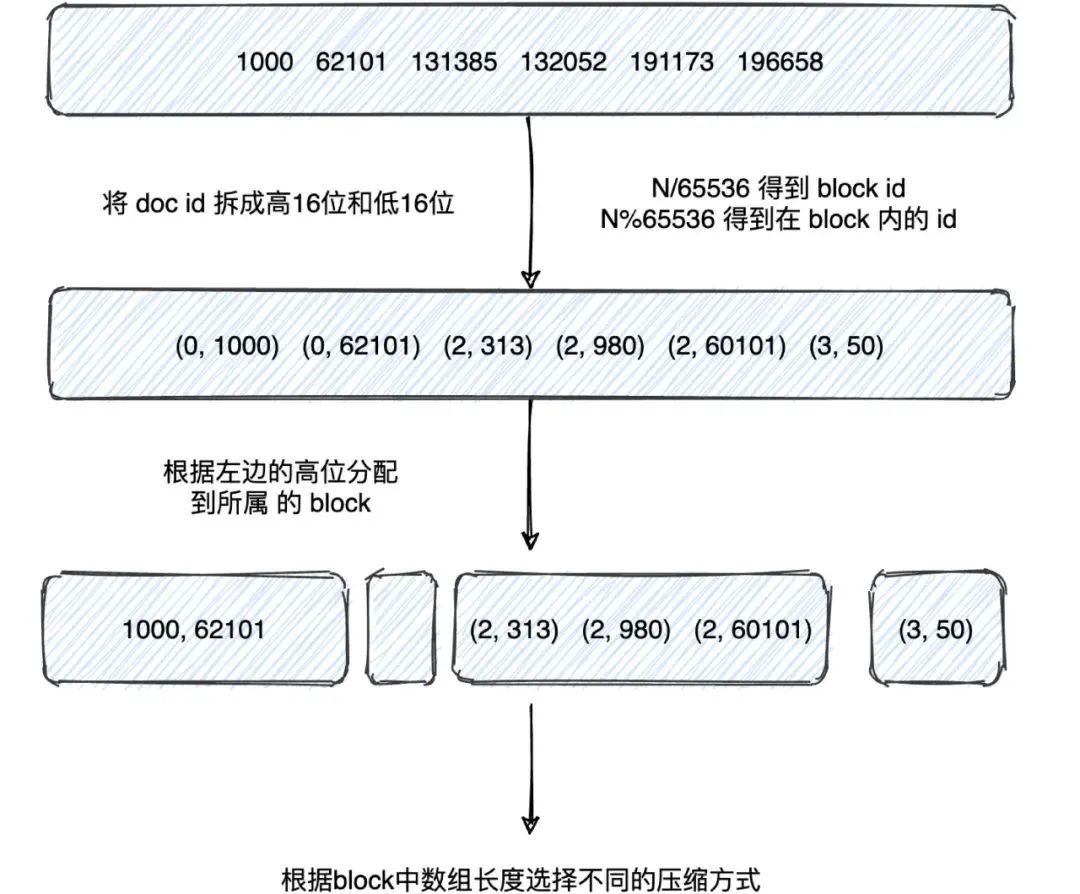
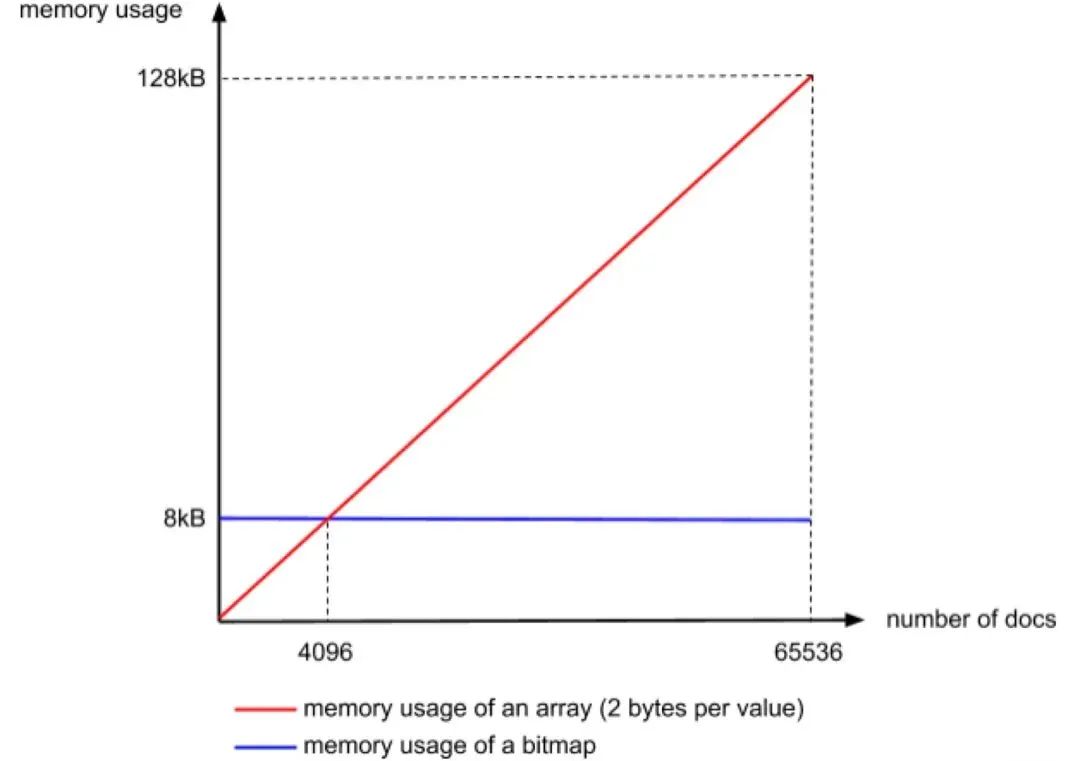
len<4096 ArrayContainer 直接存值
len>=4096 BitmapContainer 使用 bitmap 存储
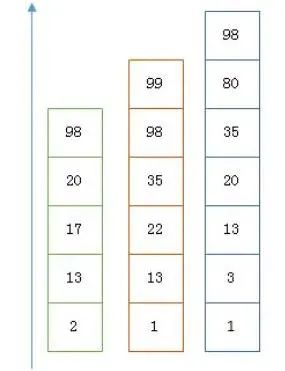
高位聚合(假设数据中有 100w 个高位相同的值,原先需要 100w_2byte,现在只要 1_2byte)
低位压缩
为了能够快速定位到目标文档,ES 使用倒排索引技术来优化搜索速度,虽然空间消耗比较大,但是搜索性能提高十分显著。
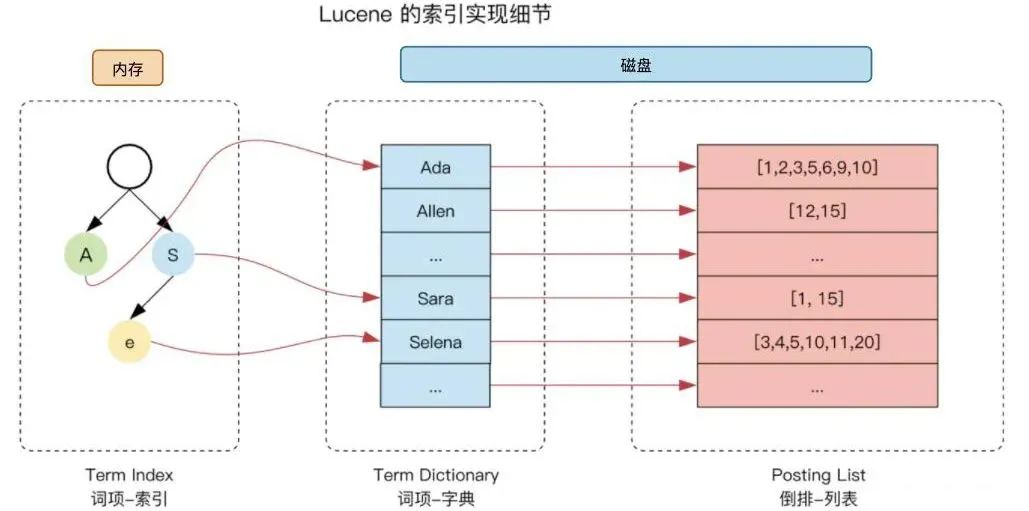
为了能够在数量巨大的 terms 中快速定位到某一个 term,同时节约对内存的使用和减少磁盘 io 的读取,lucene 使用“term index -> term dictionary -> postings list”的倒排索引结构,通过 FST 压缩放入内存,进一步提高搜索效率。
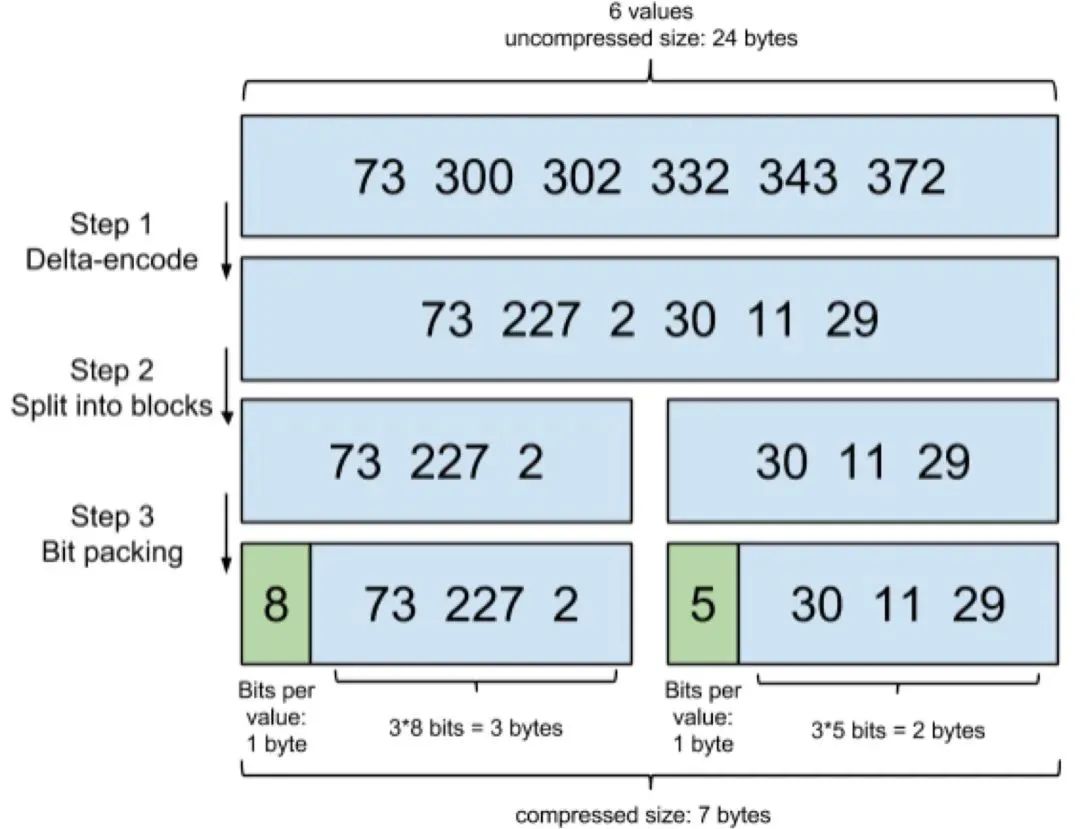
为了减少 postings list 的磁盘消耗,Lucene 使用了 FOR(Frame of Reference)技术压缩,带来的压缩效果十分明显。
ES 的 filter 语句采用了 Roaring Bitmap 技术来缓存搜索结果,保证高频 filter 查询速度的同时降低存储空间消耗。
在联合查询时,在有 filter cache 的情况下,会直接利用位图的原生特性快速求交并集得到联合查询结果,否则使用 skip list 对多个 postings list 求交并集,跳过遍历成本并且节省部分数据的解压缩 CPU 成本。
不需要索引的字段,一定要明确定义出来,因为默认是自动建索引的
同样的道理,对于 String 类型的字段,不需要 analysis 的也需要明确定义出来,因为默认也是会 analysis 的
选择有规律的 ID 很重要,随机性太大的 ID(比如 Java 的 UUID)不利于查询
https://www.elastic.co/cn/blog/frame-of-reference-and-roaring-bitmaps
https://www.elastic.co/cn/blog/found-elasticsearch-from-the-bottom-up
http://blog.mikemccandless.com/2014/05/choosing-fast-unique-identifier-uuid.html
https://www.infoq.cn/article/database-timestamp-02
https://zhuanlan.zhihu.com/p/137574234
最近面试BAT,整理一份面试资料《Java面试BAT通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。 获取方式:关注公众号并回复 java 领取,更多内容陆续奉上。 明天见(。・ω・。)ノ♡