
GPU搞不定CPU却能破局?看至强+傲腾持久内存突破AI内存墙
大数据文摘
共 5279字,需浏览 11分钟
·
2022-07-04 15:16

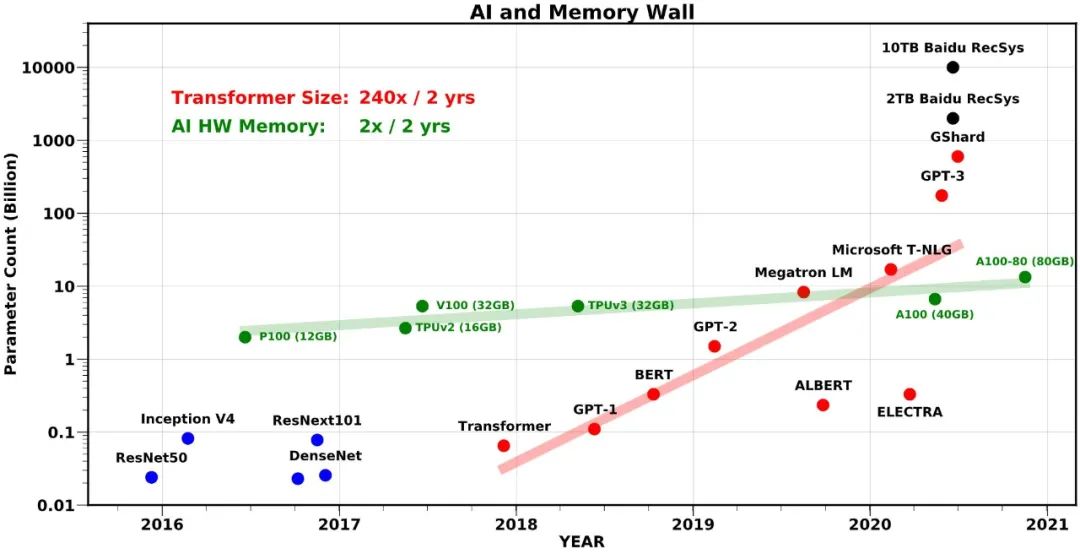
SOTA Transformer 模型参数量(红点)和 AI 硬件内存大小(绿点)增长趋势对比。
图源:
https://github.com/amirgholami/ai_and_memory_wall/blob/main/imgs/pdfs/model_size_scaling.pdf
工业界的推理拦路虎:内存墙
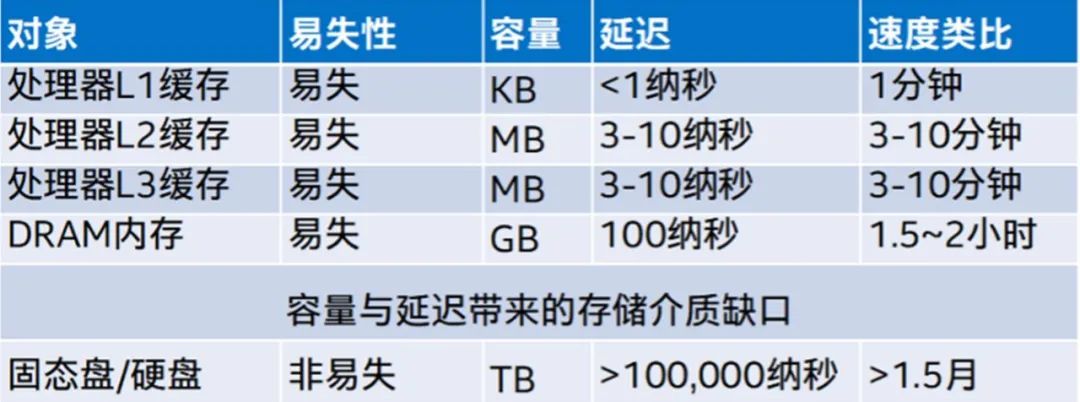
打破推理内存墙,不用 DRAM 用什么?
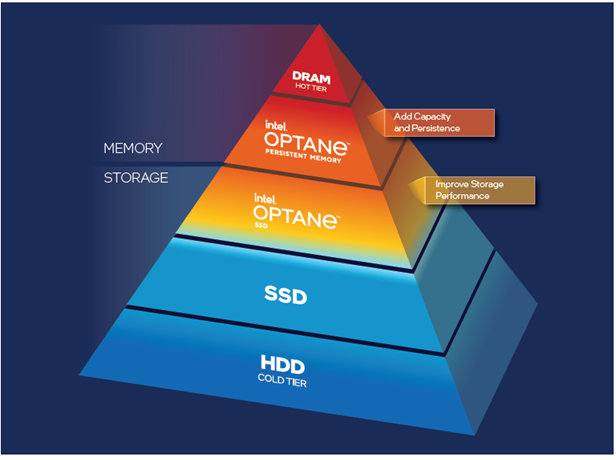
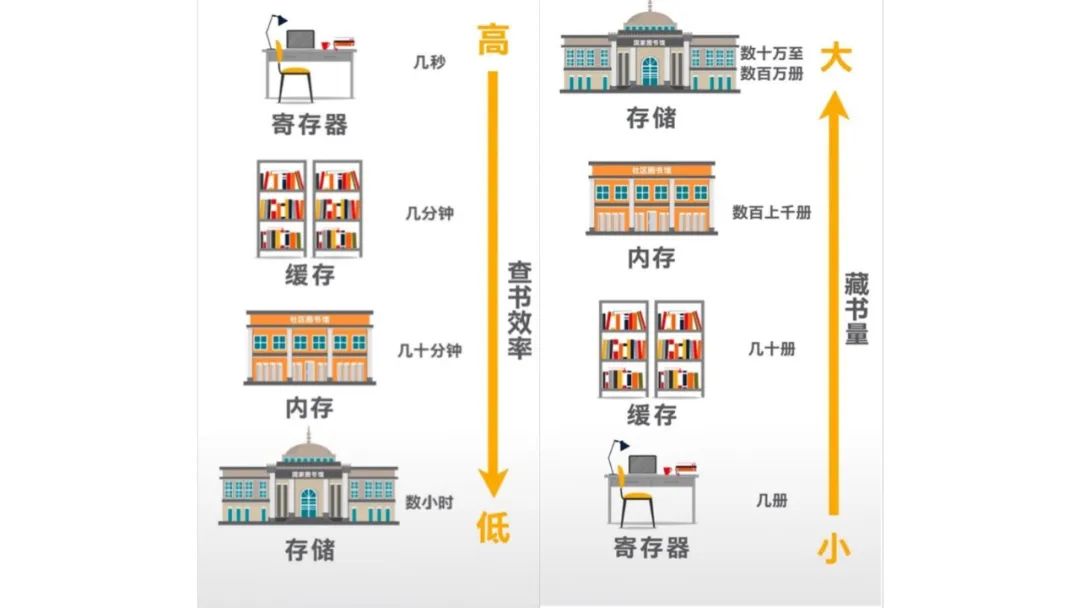
除了傲腾™ 持久内存,还有哪些方案可以打破内存墙?
评论