
偏差和方差的理解
共 946字,需浏览 2分钟
·
2020-12-05 19:36
偏差和方差理解
机器学习中泛化误差可以分解为三个部分,偏差(Variance)、方差(bias)和噪音(noise),在提升算法的性能过程中,我们主要专注偏差和方差,因为噪声属于不可约减的误差。了解导致偏差(bias)和方差(Variance)的不同误差源有助于我们改进数据的拟合过程,从而产生更准确的模型。
1、公式及概念理解:
| 符号 | 定义 |
|---|---|
| x | 测试样本 |
| D | 数据集 |
| yD | X在数据集中的标记 |
| y | x的真实标记 |
| f | 训练集D学的的模型 |
| f(x;D) | 训练集学得的模型对x的预测 |
模型f对x的期望预测为:
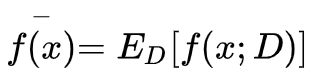 偏差:度量了学习算法的期望预测与真实结果的偏离程度,刻画了学习算法本身的拟合能力,偏差越大,越偏离真实数据。
偏差:度量了学习算法的期望预测与真实结果的偏离程度,刻画了学习算法本身的拟合能力,偏差越大,越偏离真实数据。
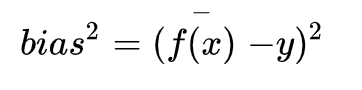
方差:方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响,简单来讲就是预测值的变化范围,和真实值无关,也就是他们的离散程度。方差越大,离散程度越大,数据的分布越分散。
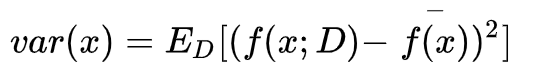 噪声:噪声则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。
噪声:噪声则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。
 2、图形理解
2、图形理解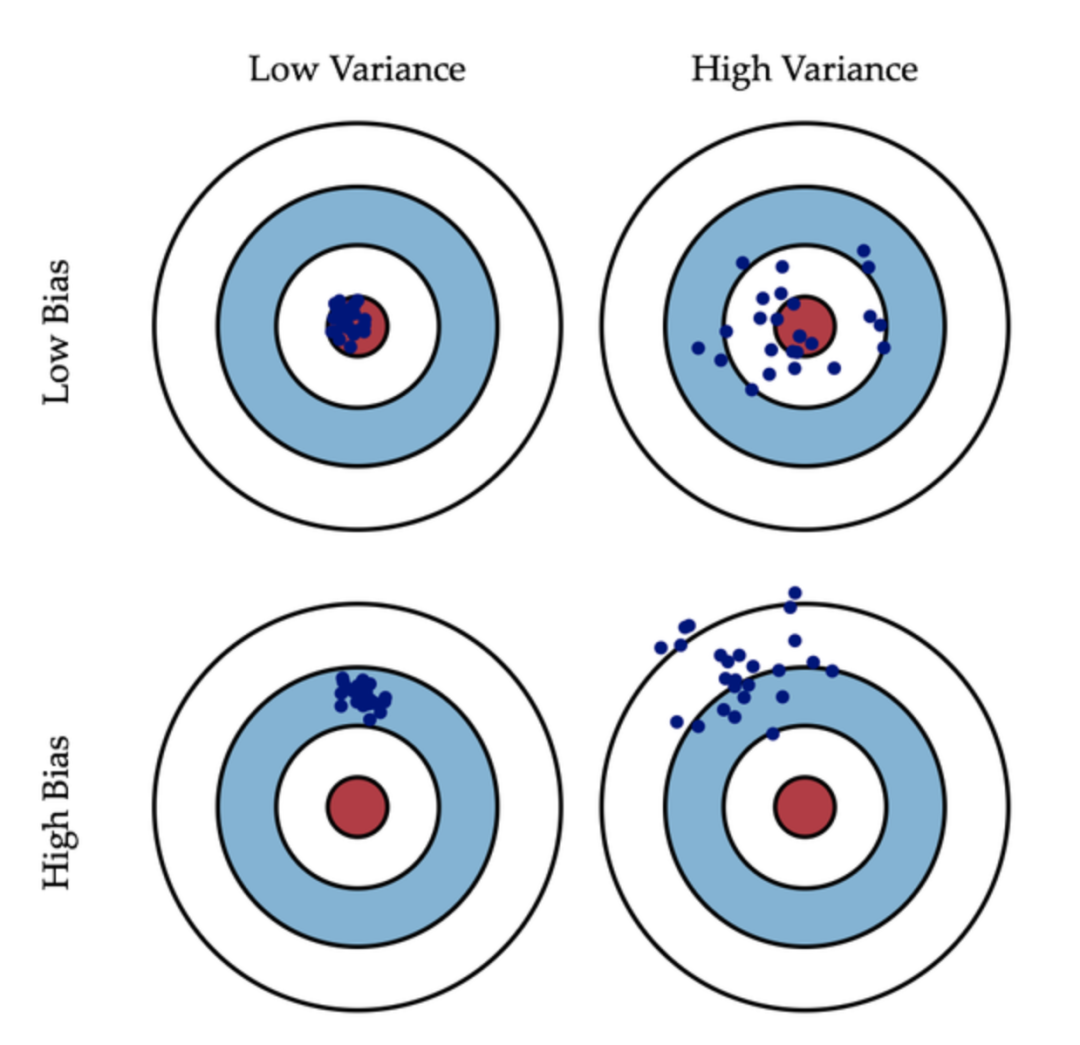
假设靶心分布的红色区域是正确值,蓝色点是训练集训练出来的模型对样本的预测值:
左一图片蓝色点分布集中且均在红色区域内,代表的是低方差、低偏差类型;
右一图片蓝色点比较分散,方差大,靠近靶心,偏差小,代表的是高方差、低偏差类型,方差大的模型,往往是从训练集里学了太多东西,所以导致在测试集的表现时好时坏,预测值的数据分布就离散了,方差也就大了,属于过拟合;
左一图片蓝色点分布集中,偏离红色靶心区域,代表的是低方差、高偏差类型,偏差大的模型,它通常不怎么从训练集里学习到东西,导致模型过于简单,自然在预测测试集的时候,效果不好,属于欠拟合;
右一图片蓝色点分布分散,偏离红色靶心区域,代表的是高方差、高偏差类型。
如何解决高偏差和高方差?
高偏差:增加更多的特征,提升模型复杂度;减少正则化程度;
高方差:增加训练样本数据;减少特征数量;增加正则化程度。