
因为一次宕机,终于搞透了 Kafka 高可用原理!
1
Kafka 宕机引发的高可用思考
问题要从一次Kafka的宕机开始说起。
2
Kafka 的多副本冗余设计
首先简单了解Kafka的几个概念:
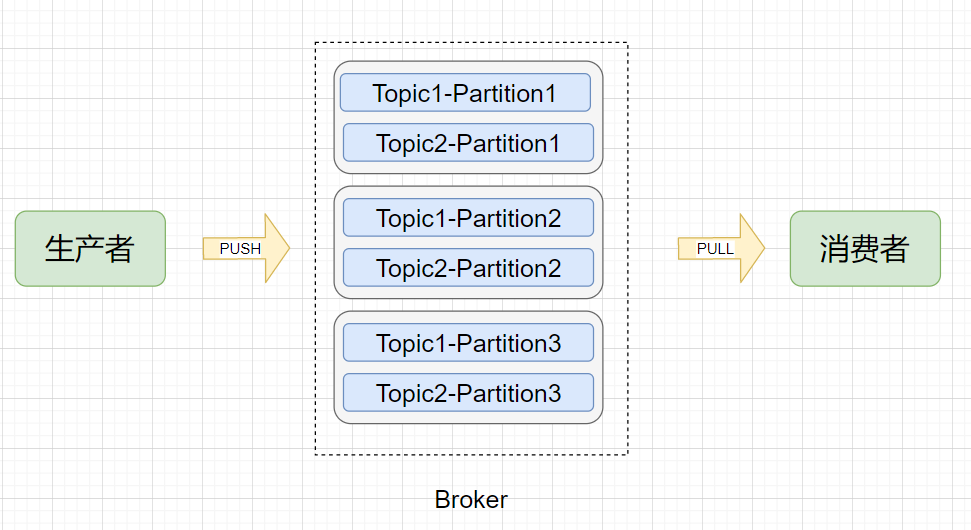
物理模型
逻辑模型
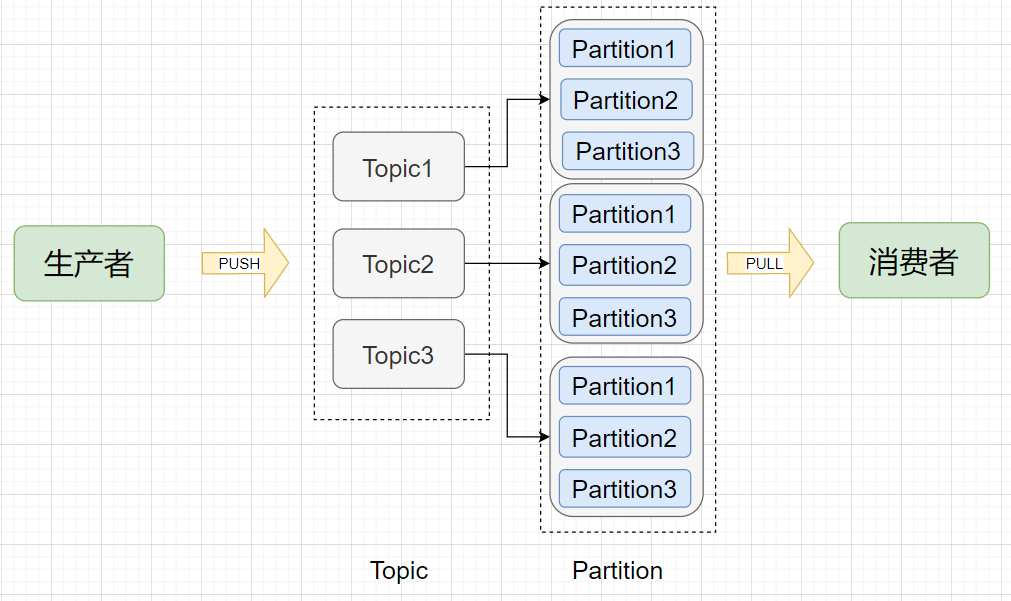
Broker(节点):Kafka服务节点,简单来说一个Broker 就是一台Kafka服务器,一个物理节点。 Topic(主题):在Kafka中消息以主题为单位进行归类,每个主题都有一个 Topic Name ,生产者根据Topic Name将消息发送到特定的Topic,消费者则同样根据Topic Name从对应的Topic进行消费。 Partition(分区):Topic (主题)是消息归类的一个单位,但每一个主题还能再细分为一个或多个Partition (分区),一个分区只能属于一个主题。主题和分区都是逻辑上的概念,举个例子,消息1和消息2都发送到主题1,它们可能进入同一个分区也可能进入不同的分区(所以同一个主题下的不同分区包含的消息是不同的),之后便会发送到分区对应的Broker节点上。 Offset (偏移量):分区可以看作是一个只进不出的队列(Kafka只保证一个分区内的消息是有序的),消息会往这个队列的尾部追加,每个消息进入分区后都会有一个偏移量,标识该消息在该分区中的位置,消费者要消费该消息就是通过偏移量来识别。
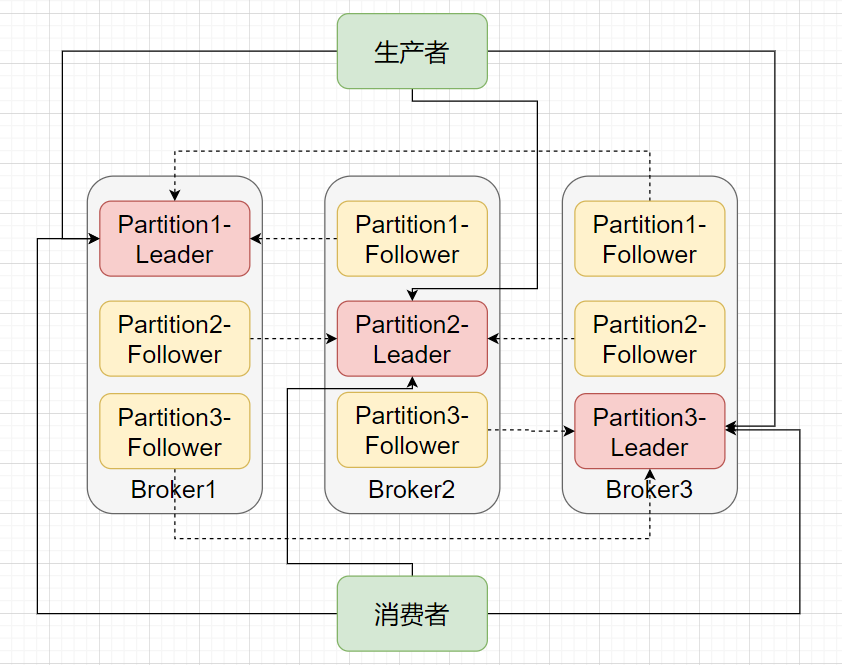
3
Ack 参数决定了可靠程度
Asks这个参数是生产者客户端的重要配置,发送消息的时候就可设置这个参数。该参数有三个值可配置:0、1、All 。
4
解决问题
我在开发测试环境配置的 Broker 节点数是3, Topic 是副本数为3, Partition 数为6, Asks参数为1。
作者:JanusWoo
来源:https://juejin.im/post/6874957625998606344
往期推荐
如果你觉得这篇文章不错,那么,下篇通常会更好。添加微信好友,可备注“加群”(微信号:zhuan2quan)。
和花一辈子都看不清的人,
注定是截然不同的搬砖生涯。

评论