
好家伙,AI音乐家火了。。
共 1424字,需浏览 3分钟
·
2021-10-09 16:48
转自:量子位 | 博雯
大家好,我是 Jack。
最近又发现了一个好玩的项目。
写歌填词、改换风格、续写音乐的AI,今天又来做编曲人了!
上传一段《Stay》,一键按下:
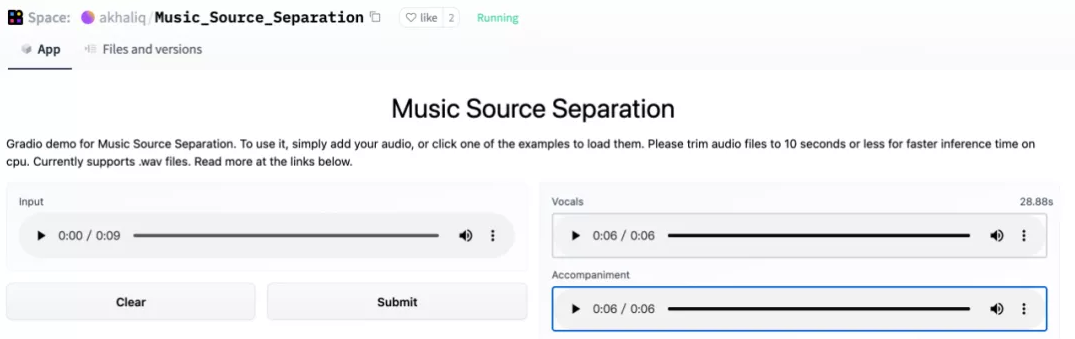
伴奏和人声就轻松分离,大家听听效果:
人声颇有种在空旷地带清唱的清晰感,背景乐都能直接拿去做混剪了!

神器,福音啊!
这样惊人的效果也引发了 Reddit 热议:
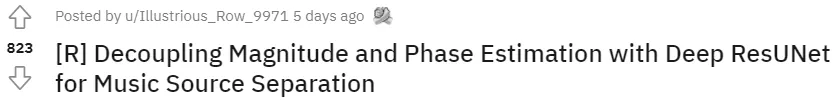
这项研究的主要负责人孔秋强来自字节跳动,全球最大的古典钢琴数据集GiantMIDI-Piano,也是由他在去年牵头发布的。
AI 音乐家实锤,可以看下官方的演示效果。
Music Source Separation
算法已经开源,有编程基础的可以直接跑代码。
项目地址:
https://github.com/bytedance/music_source_separation
没有编程基础也没关系,项目提供了在线可玩的网页。
试玩网页:
https://huggingface.co/spaces/akhaliq/Music_Source_Separation
这里简单说下算法的原理。
原理说明
这是一个包含了相位估计的音乐源分离(MSS)系统。
首先,将幅值(Magnitude)与相位(Phase)解耦,用以估计复数理想比例掩码(cIRM)。
其次,为了实现更灵活的幅值估计,将有界掩码估计和直接幅值预测结合起来。
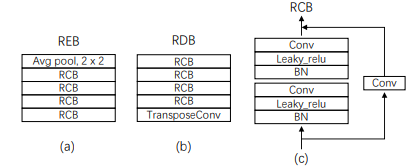
最后,为 MSS 系统引入一个 143 层的深度残差网络(Deep Residual UNets),利用残差编码块(REB)和残差解码块(RDB)来增加其深度:
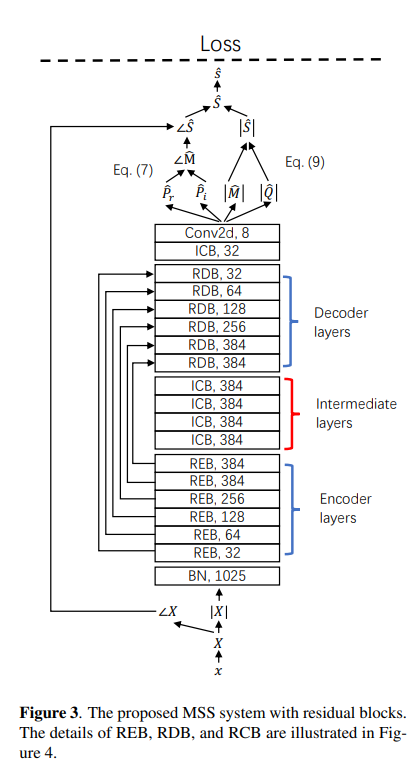
残差编码块和残差卷积块中间还引入了中间卷积块(ICB),以提高残差网络的表达能力。
其中每个残差编码块由 4 个残差卷积块(RCB)组成,残差卷积块又由两个核大小为 3×3 的卷积层组成。
每个残差解码块由 8 个卷积层和 1 个反卷积层组成。
更详细的算法原理,可以直接看论文。
论文地址:
https://arxiv.org/pdf/2109.05418.pdf
实验结果
接下来,将这一系统在 MUSDB18 数据集上进行实验。
MUSDB18 中的训练/验证集分别包含 100/50 个完整的立体声音轨,包括独立的人声、伴奏、低音、鼓和其他乐器。
在训练时,利用上述系统进行并行的混合音频数据增强,随机混合来自同一来源的两个 3 秒片段,然后作为一个新的 3 秒片段进行训练。
以信号失真率(SDR)作为评判标准,可以看到 ResUNetDecouple 系统在分离人声、低音、其他和伴奏方面明显优于以前的方法:
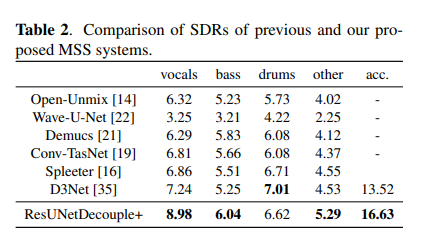
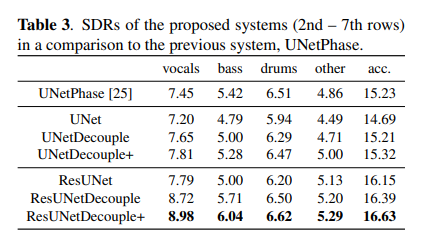
在消融实验中,143 层残差网络的表现也证实了,结合有界掩码估计和直接幅值预测确实能够改善声音源分离系统的性能。
https://www.reddit.com/r/MachineLearning/comments/pqpl7m/r_decoupling_magnitude_and_phase_estimation_with/
