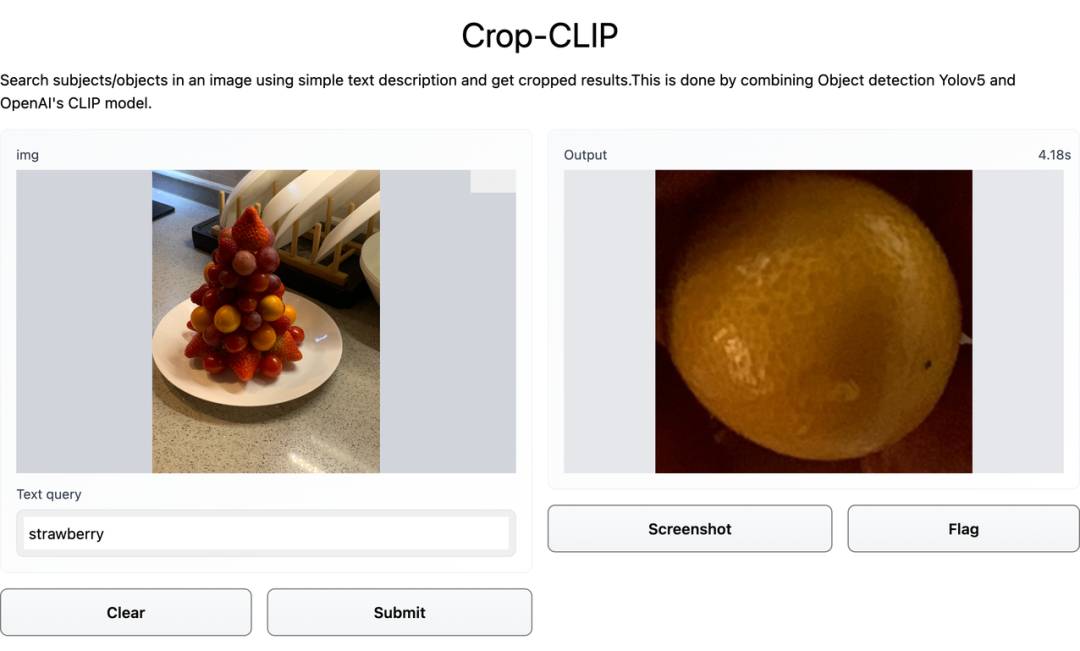
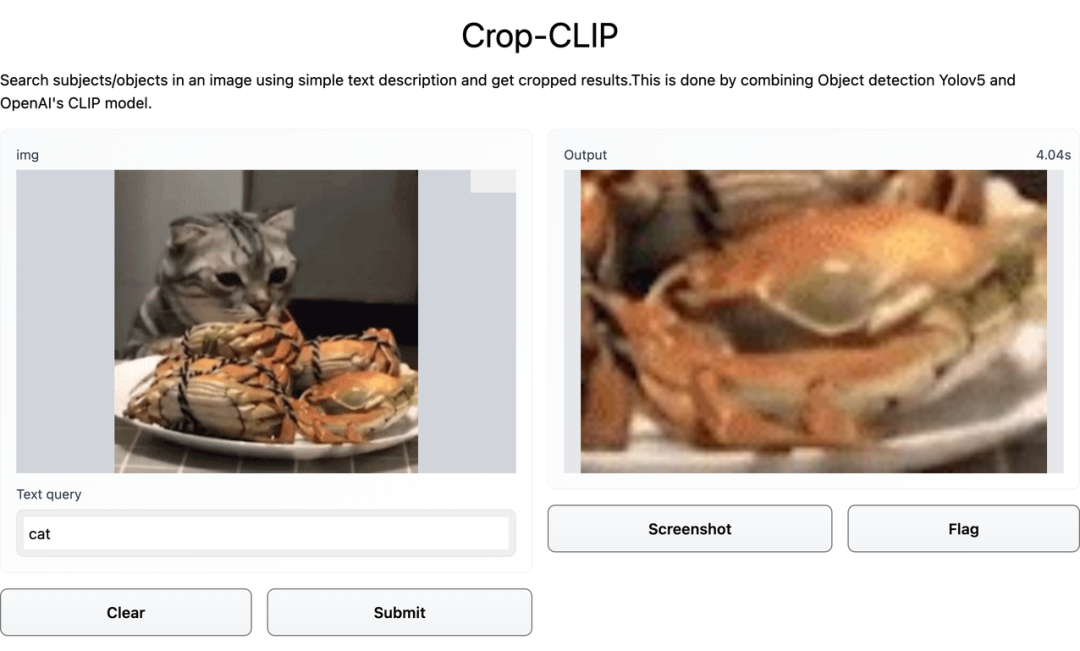
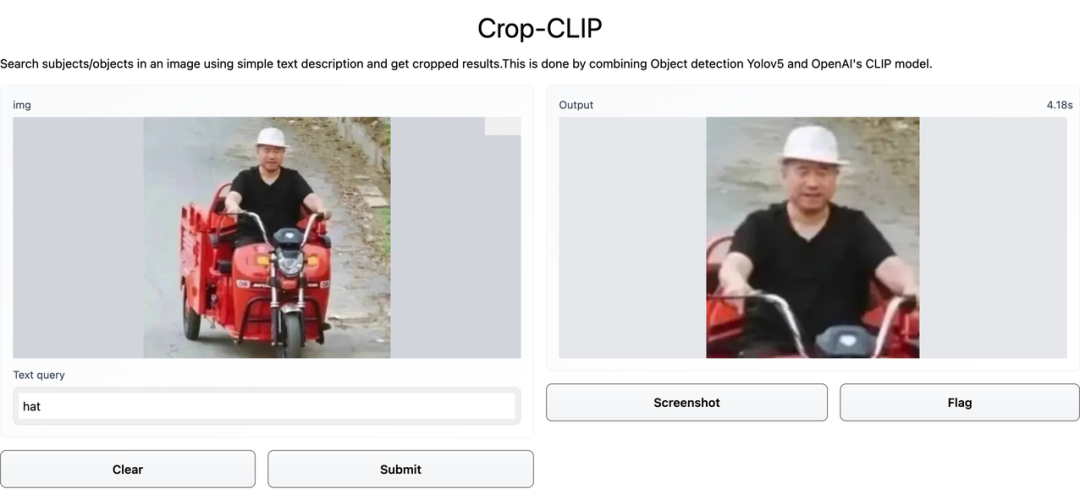
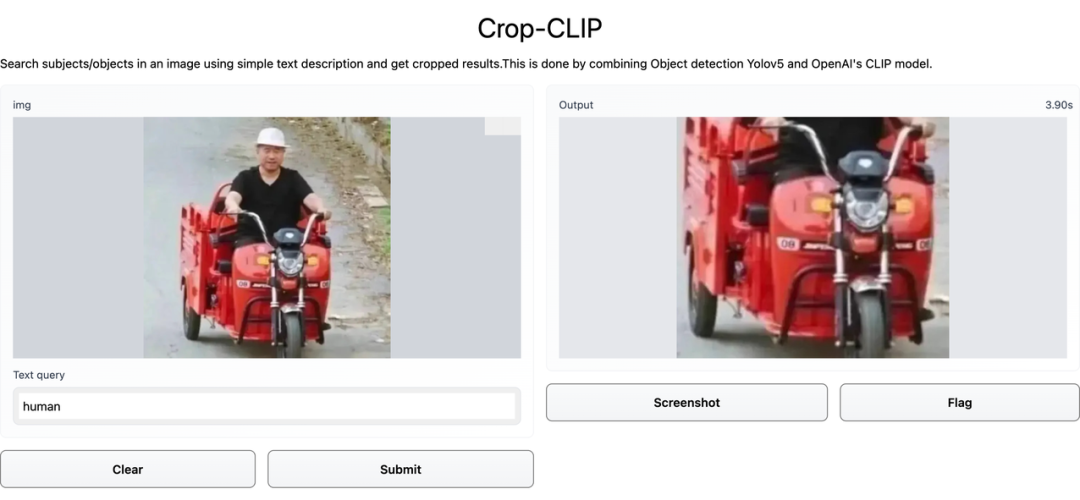
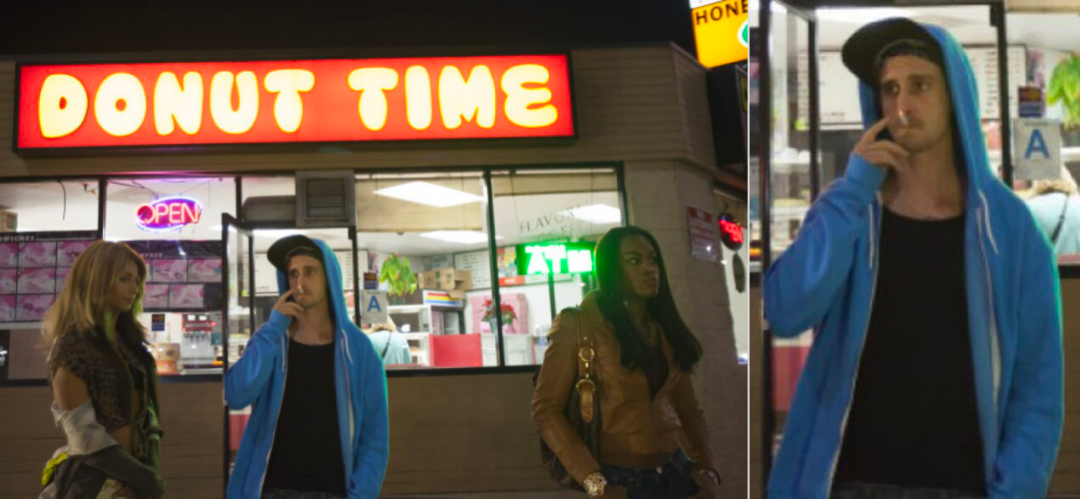给 Crop-CLIP 一个口令,就能自动搜图,还能帮忙裁剪出图片中的关键部分。
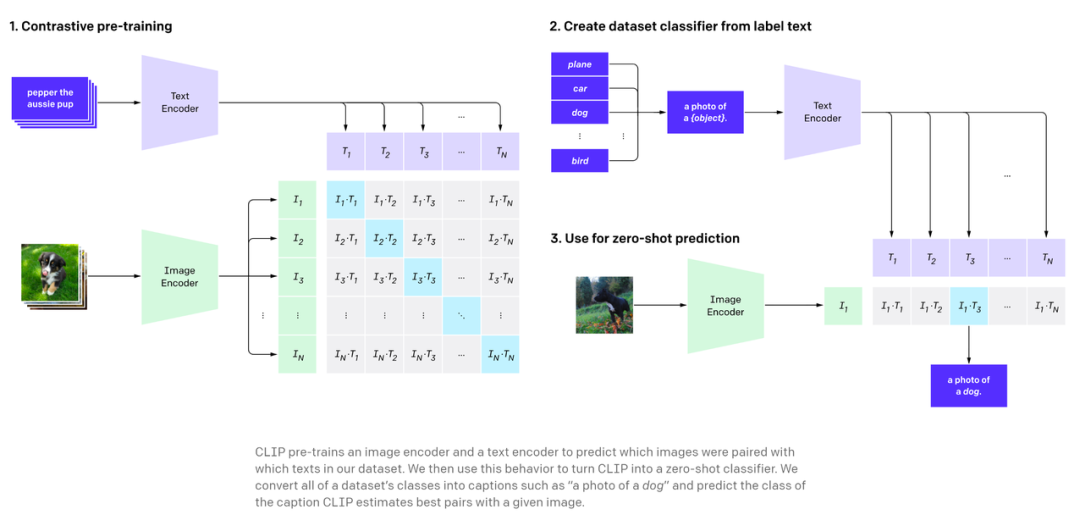
经常找图的人都知道,根据检索关键词组寻找理想中的照片是件很麻烦的事情。打开搜索引擎或无版权图片网站,输入关键词,如果幸运的话,可能会在第一页或前 N 个检索结果中找到想要的图像。这种搜索方式仍然是基于图片标签进行的。自从 2021 年 1 月,OpenAI 推出了名为 CLIP 的神经网络,找图就进入了语义搜索时代。CLIP 建立在零样本迁移、自然语言监督、多模态学习的大量工作基础之上,因此它可以从自然语言监督中有效地学习视觉概念。语义搜索不会试图为输入短语中的单词找到精确匹配,而是捕获上下文和单词之间的更广泛的关系,然后检索与搜索查询的上下文密切相关的结果。近日,一位开发者将 YOLOv5 和 CLIP 结合起来,在使用关键词检索图片内容的同时,直接精确裁剪出包含检索主题的那一部分。
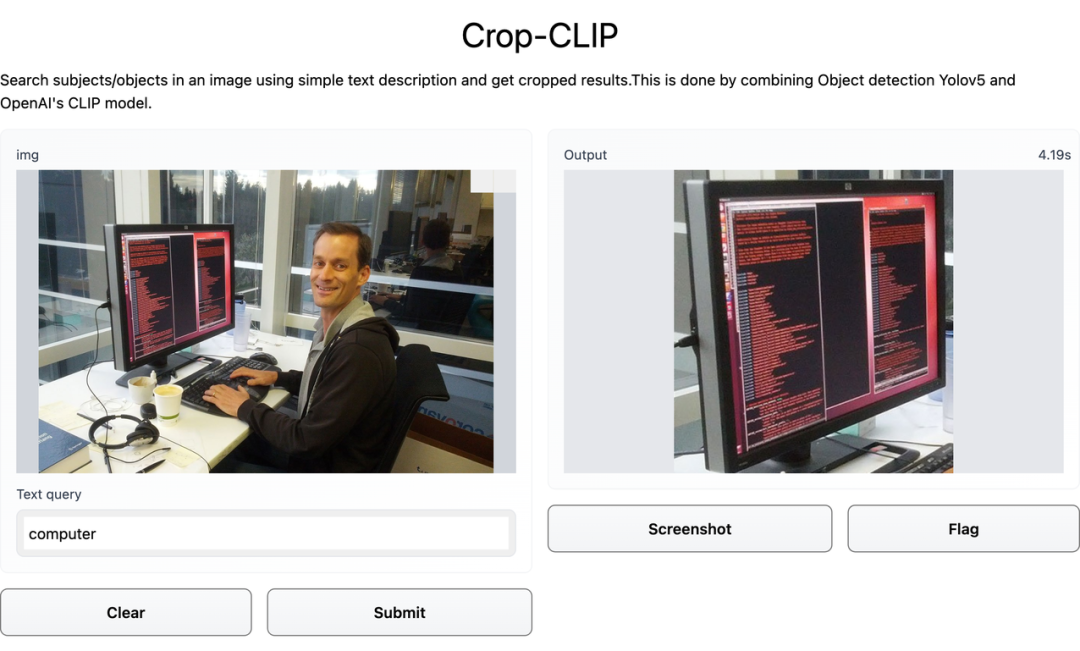
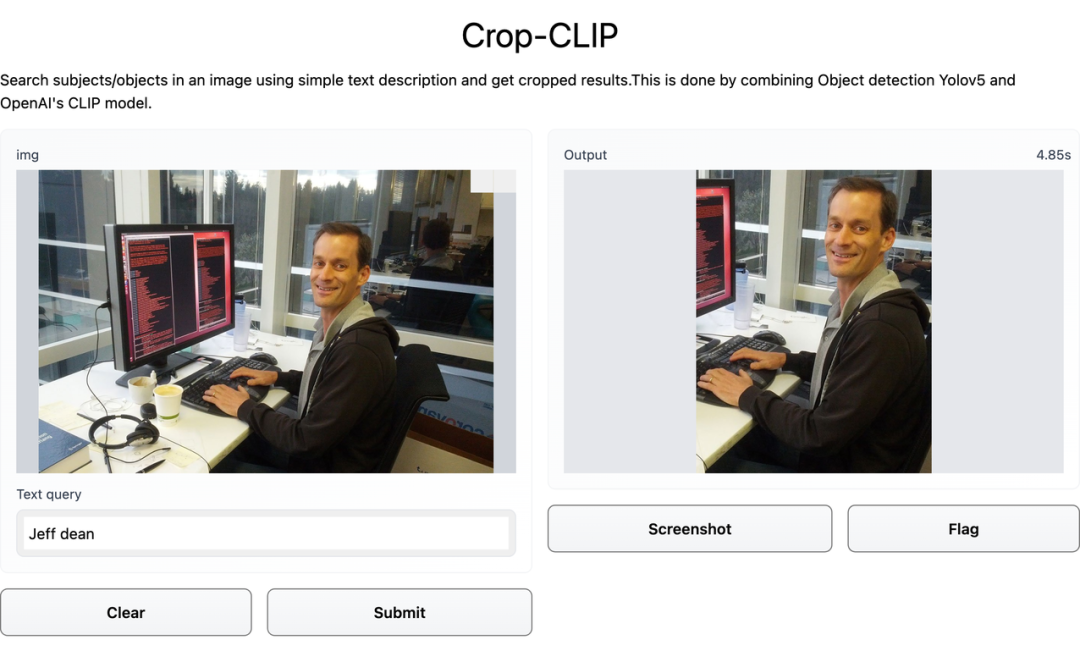
在这张图中,检索的关键词是「Whats the time」。先看几个示例,比如你输入关键词「卫衣男」,效果如下图:CLIP 是用大量带有对应标题的图像进行训练的,因此它学会了理解哪个标题与哪个图片相匹配。用户可以给出一个随机图像,并在向量空间中找到该图像的余弦相似度,其中包含两个短语向量:「这是狗的照片吗?」、「这是猫的照片吗?」。模型会查看哪一个具有最高的相似度,然后找到图像的类别。某种程度上说,CLIP 具有像 GPT-2 和 GPT-3 一样的零样本分类能力。和目标检测器 YOLOv5 相结合之后,CLIP 在语义搜索图像的基础上增加了裁剪能力,变身 Crop-CLIP。检测和裁剪对象 (yolov5s)
使用 CLIP 对裁剪后的图像进行编码
使用 CLIP 编码搜索查询
找到最佳匹配部分
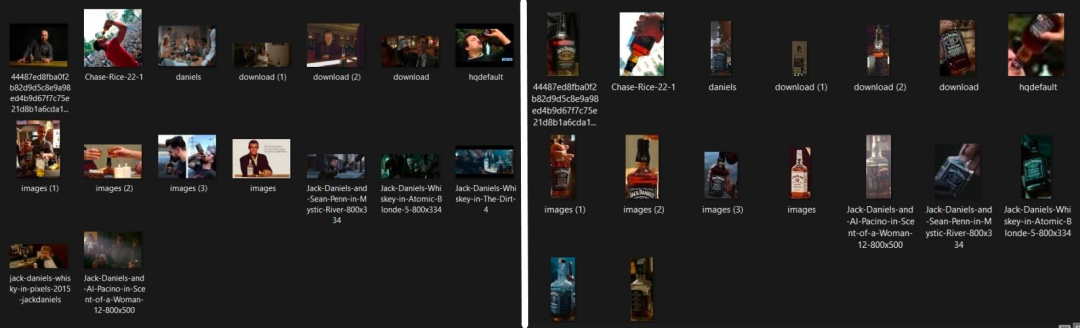
Crop-CLIP 也可用于创建数据集,需要在代码中进行一些更改,进行批量搜索查询。如下图所示,Jack Daniels 威士忌酒瓶的图像已被裁剪并保存。项目作者 Vijish Madhavan 是一位自由开发者,现居英国,是利物浦约翰摩尔斯大学的硕士生。但作者也提到了一点「限制」,Crop-CLIP 严重依赖目标检测器 YOLOv5,鉴于 YOLOv5 是在 COCO 数据集上进行预训练的目标检测架构和模型,因此 Crop-CLIP 检测过程中的类别会依赖于 COCO 中的类别。所以在机器之心编辑部的试用过程中,也会出现不同程度的翻车事故。至少,这个项目是一种有趣的创新,在后续的优化中,相信作者也会对数据集等方面进行改进,实现更好的搜图效果。© THE END
转载请联系机器之心获得授权
猜您喜欢:
超110篇!CVPR 2021最全GAN论文汇总梳理!
超100篇!CVPR 2020最全GAN论文梳理汇总!
拆解组新的GAN:解耦表征MixNMatch
StarGAN第2版:多域多样性图像生成
附下载 | 《可解释的机器学习》中文版
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 |《计算机视觉中的数学方法》分享
《基于深度学习的表面缺陷检测方法综述》
《零样本图像分类综述: 十年进展》
《基于深度神经网络的少样本学习综述》