
【机器学习】使用集成学习回归器改善预测模型的得分
共 11790字,需浏览 24分钟
·
2021-04-28 19:50
编译 | Flin
来源 | analyticsvidhya
介绍
集成的一般原则是将各种模型的预测与给定的学习算法相结合,以提高单个模型的鲁棒性。
“整体大于部分的总和。” –亚里斯多德
换句话说,将各个部分连接在一起以形成一个实体时,它们的价值要大于将各个部分分开的价值。
上面的说法更适合堆叠,因为我们结合了不同的模型以获得更好的性能。在本文中,我们将讨论堆叠以及如何创建自己的堆栈回归器。
堆叠是什么意思?
集成学习是机器学习从业人员广泛使用的一种技术,它结合了不同模型的技能,可以根据给定的数据进行预测。我们正在使用它来结合多种算法的最佳性能,这些算法可以提供比单个回归器更稳定的预测,并且方差很小。
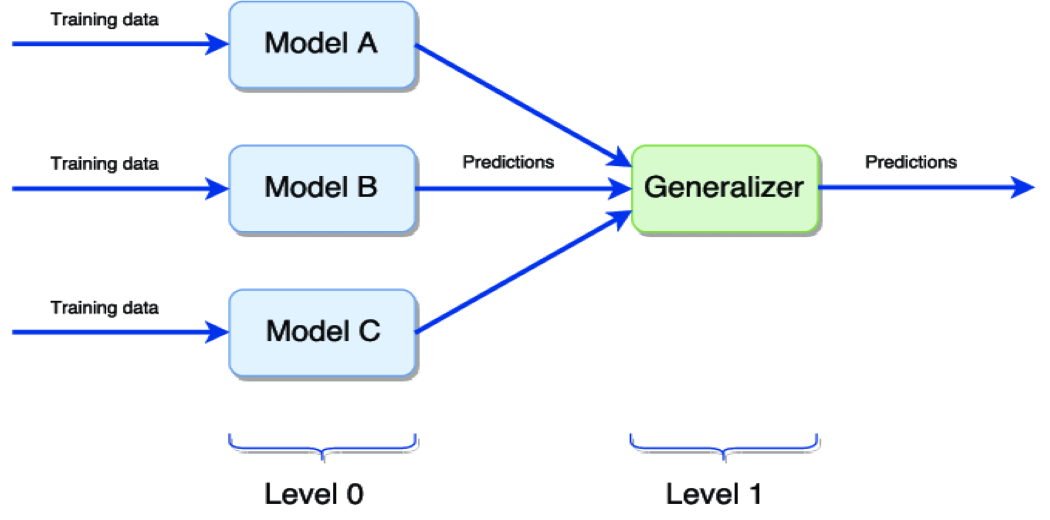
上图表示模型的简单堆叠:
Level 0 在同一数据集上训练不同的模型,然后进行预测。
Level 1 概括由不同模型做出的预测以获得最终输出。
泛化器最常用的方法是取所有0级模型预测的平均值,以获得最终输出。
创建自己的堆栈回归器
我们将采用 Kaggle著名的房价预测数据集。目的是根据数据集中存在的几种特征来预测房价。
房价预测数据集:https://www.kaggle.com/c/house-prices-advanced-regression-techniques
基础模型
我们将使用k-fold交叉验证来训练不同的基础模型,并查看给定数据集中所有模型的性能(RMSE)。
下面的函数 rmse_cv 用于在创建数据的5倍中训练所有单个模型,并根据与实际预测相比的非折叠预测返回该模型的RMSE分数。
#Validation function
n_folds = 5
def rmse_cv(model):
kf = KFold(n_folds, shuffle=True, random_state=42).get_n_splits(train.values)
rmse= np.sqrt(-cross_val_score(model, train.values, y_train, scoring="neg_mean_squared_error", cv = kf))
return(rmse)
注意:在训练基础模型之前,已完成所有数据预处理技术。
Lasso
lasso = Lasso(alpha =0.0005)
rmse_cv(lasso)
Lasso score: 0.1115
ElasticNet
ENet = ElasticNet(alpha=0.0005, l1_ratio=.9)
rmse_cv(ENet)
ElasticNet Score: 0.1116
Kernel Ridge Regression
KRR = KernelRidge(alpha=0.6, kernel='polynomial', degree=2, coef0=2.5)
rmse_cv(KRR)
Kernel Ridge Score: 0.1153
Gradient Boosting
GBoost = GradientBoostingRegressor(n_estimators=3000, learning_rate=0.05,max_depth=4,max_features='sqrt',min_samples_leaf=15, min_samples_split=10,loss='huber')
rmse_cv(GBoost)
Gradient Boosting Score: 0.1177
XGB Regressor
model_xgb = xgb.XGBRegressor(colsample_bytree=0.4603, gamma=0.0468,
learning_rate=0.05, max_depth=3,
min_child_weight=1.7817, n_estimators=2200,
reg_alpha=0.4640, reg_lambda=0.8571,
subsample=0.5213, silent=1,
random_state =7, nthread = -1)
rmse_cv(model_xgb)
XGBoost Score: 0.1161
LightGBM
model_lgb = lgb.LGBMRegressor(objective='regression',num_leaves=5,
learning_rate=0.05, n_estimators=720,
max_bin = 55, bagging_fraction = 0.8,
bagging_freq = 5, feature_fraction = 0.2319,
feature_fraction_seed=9, bagging_seed=9,
min_data_in_leaf =6, min_sum_hessian_in_leaf = 11)
rmse_cv(model_lgb)
LGBM Score: 0.1157
类型1:最简单的堆栈回归方法:平均基础模型
我们从平均基础模型的简单方法开始。建立一个新类,以通过我们的模型扩展scikit-learn,并利用封装和代码重用。
平均基础模型类别
from sklearn.base import BaseEstimator, TransformerMixin, RegressorMixin, clone
class AveragingModels(BaseEstimator, RegressorMixin, TransformerMixin):
def __init__(self, models):
self.models = models
# we define clones of the original models to fit the data in
def fit(self, X, y):
self.models_ = [clone(x) for x in self.models]
# Train cloned base models
for model in self.models_:
model.fit(X, y)
return self
#Now we do the predictions for cloned models and average them
def predict(self, X):
predictions = np.column_stack([
model.predict(X) for model in self.models_
])
return np.mean(predictions, axis=1)
fit() :此方法将克隆作为参数传递的所有基础模型,然后在整个数据集中训练克隆的模型。
predict() :所有克隆的模型将进行预测,并使用“np.column_stack”对预测进行列堆叠,然后将计算并返回该预测的平均值。
np.column_stack:https://numpy.org/doc/stable/reference/generated/numpy.column_stack.html
averaged_models = AveragingModels(models = (ENet, GBoost, KRR, lasso))
score = rmsle_cv(averaged_models)
print(" Averaged base models score: {:.4f}n".format(score.mean()))
Averaged base models score: 0.1091
哇!即使简单地取所有基础模型的平均预测值,也能获得不错的RMSE分数。
类型2:添加元模型
在这种方法中,我们将训练所有基础模型,并将基础模型的预测(失叠预测)用作元模型的训练特征。
元模型用于在作为特征的基础模型预测与作为目标变量的实际预测之间找到模式。
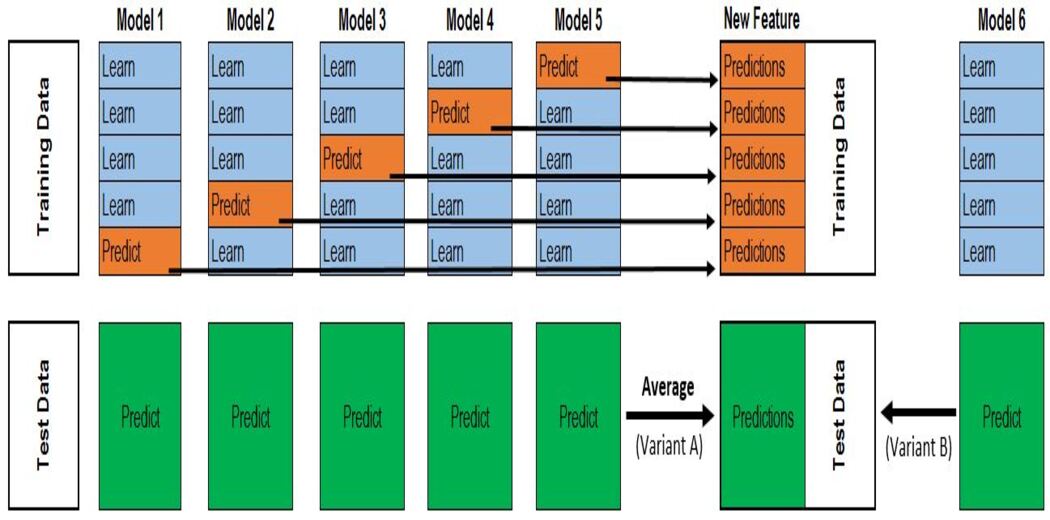
步骤:
1.将数据分为2组训练和验证集。
2.在训练数据中训练所有基础模型。
3.在验证数据集上测试基础模型,并存储预测(失叠预测)。
4.使用基础模型做出的失叠预测作为输入特征,并使用正确的输出作为目标变量来训练元模型。
前三个步骤将根据k的值针对k折进行迭代。如果k = 5,那么我们将在4折上训练模型,并在验证集(第5折)上进行预测。重复此步骤k次(此处,k = 5)可得出整个数据集的失叠预测。这将对所有的基础模型进行。
然后,将使用所有模型的超预期作为X并将原始目标变量作为y来训练元模型。该元模型的预测将被视为最终预测。
class StackingAveragedModels(BaseEstimator, RegressorMixin, TransformerMixin):
def __init__(self, base_models, meta_model, n_folds=5):
self.base_models = base_models
self.meta_model = meta_model
self.n_folds = n_folds
# We again fit the data on clones of the original models
def fit(self, X, y):
self.base_models_ = [list() for x in self.base_models]
self.meta_model_ = clone(self.meta_model)
kfold = KFold(n_splits=self.n_folds, shuffle=True, random_state=156)
# Train cloned base models then create out-of-fold predictions
# that are needed to train the cloned meta-model
out_of_fold_predictions = np.zeros((X.shape[0], len(self.base_models)))
for i, model in enumerate(self.base_models):
for train_index, holdout_index in kfold.split(X, y):
instance = clone(model)
self.base_models_[i].append(instance)
instance.fit(X[train_index], y[train_index])
y_pred = instance.predict(X[holdout_index])
out_of_fold_predictions[holdout_index, i] = y_pred
# Now train the cloned meta-model using the out-of-fold predictions as new feature
self.meta_model_.fit(out_of_fold_predictions, y)
return self
#Do the predictions of all base models on the test data and use the averaged predictions as
#meta-features for the final prediction which is done by the meta-model
def predict(self, X):
meta_features = np.column_stack([
np.column_stack([model.predict(X) for model in base_models]).mean(axis=1)
for base_models in self.base_models_ ])
return self.meta_model_.predict(meta_features)
fit() :克隆基础模型和元模型,以5倍交叉验证对基础模型进行训练,并存储非折叠预测。然后使用超出范围的预测来训练元模型。
Forecast() :X的基础模型预测将按列堆叠,然后用作元模型进行预测的输入。
stacked_averaged_models = StackingAveragedModels(base_models = (ENet, GBoost, KRR),
meta_model = lasso)
score = rmsle_cv(stacked_averaged_models)
print("Stacking Averaged models score: {:.4f}".format(score.mean()))
Stacking Averaged models score: 0.1085
哇… !!! 通过使用元学习器,我们再次获得了更好的分数。
结论
上面的堆叠方法也可以在稍作更改的情况下用于分类任务。除了对基础模型预测进行平均以外,我们还可以对所有模型预测进行投票,并且可以将投票最高的类别作为输出。
下述链接显示了使用上述方法从数据预处理到模型构建的示例。
https://www.kaggle.com/shyam21/stacked-regression-public-leaderboard-23-09
往期精彩回顾
本站qq群851320808,加入微信群请扫码: