
RabbitMQ和Kafka到底怎么选?
AI全套:Python3+TensorFlow打造人脸识别智能小程序
最新人工智能资料-Google工程师亲授 Tensorflow-入门到进阶
黑马头条项目 - Java Springboot2.0(视频、资料、代码和讲义)14天完整版
来源:cnblogs.com/haolujun/p/9632835.html
前言
开源社区有好多优秀的队列中间件,比如RabbitMQ和Kafka,每个队列都貌似有其特性,在进行工程选择时,往往眼花缭乱,不知所措。对于RabbitMQ和Kafka,到底应该选哪个?
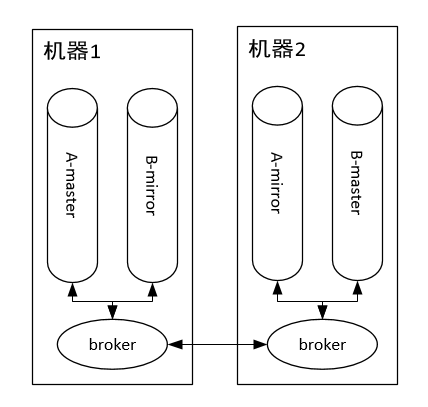
RabbitMQ架构
队列消费
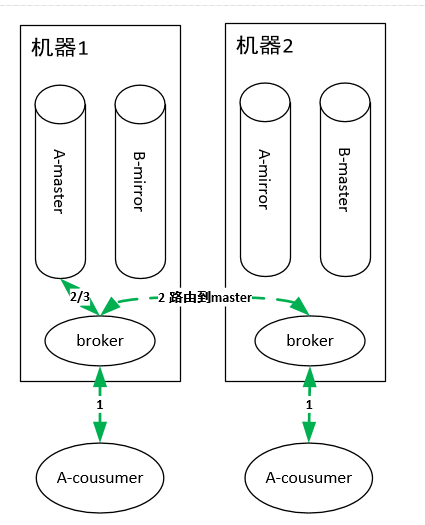
队列生产

所以,到这里小伙伴们就可以看到 RabbitMQ的不足:由于master queue单节点,导致性能瓶颈,吞吐量受限。虽然为了提高性能,内部使用了Erlang这个语言实现,但是终究摆脱不了架构设计上的致命缺陷。
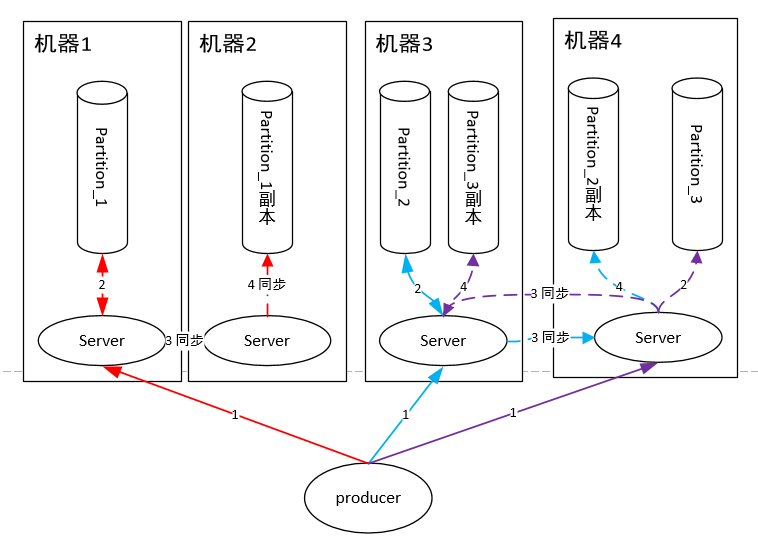
Kafka
另外,关注互联网架构师公众号,回复“面试”,送你一份面试题宝典!
这里面的每个master queue 在Kafka中叫做Partition,即一个分片。一个队列有多个主分片,每个主分片又有若干副分片做备份,同步机制类似于RabbitMQ。
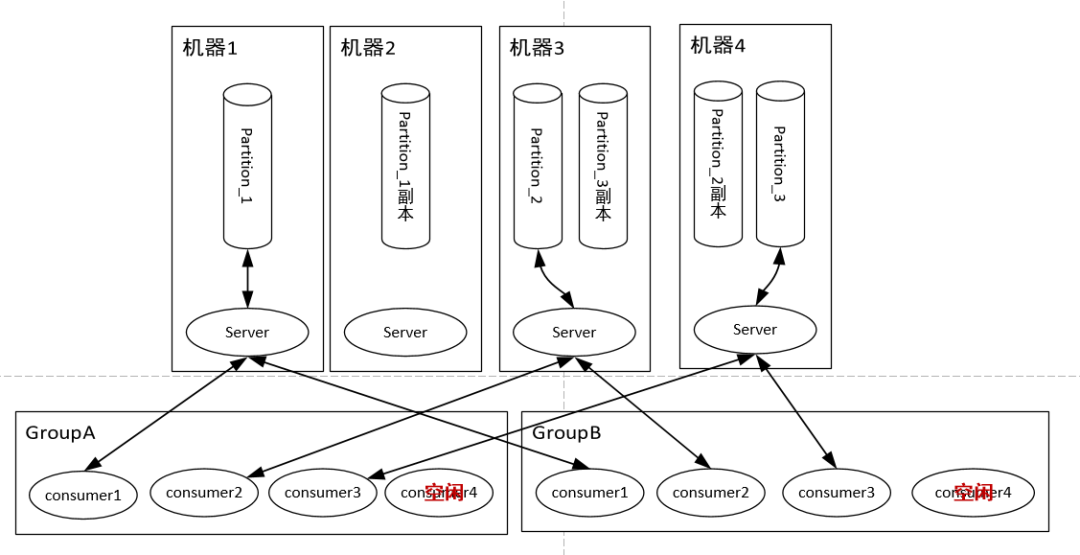
队列读同样是读主分片,并且为了优化性能,消费者与主分片有一一的对应关系,如果消费者数目大于分片数,则存在某些消费者得不到消息。
由此可见,Kafka绝对是为了高吞吐量设计的,比如设置分片数为100,那么就有100台机器去扛一个Topic的流量,当然比RabbitMQ的单机性能好。
总结
本文只做了Kafka和RabbitMQ的对比,但是开源队列岂止这两个,ZeroMQ,RocketMQ,JMQ等等,时间有限也就没有细看,故不在本文比较范围之内。
所以,别再被这些五花八门的队列迷惑了,从架构上找出关键差别,并结合自己的实际需求(比如本文就只单单从吞吐量一个需求来考察)轻轻松松搞定选型。最后总结如下:
吞吐量较低:Kafka和RabbitMQ都可以。 吞吐量高:Kafka。
本文内容参考自RabbitMQ和KafKa官方文档,所以真要搞懂一个中间件的原理最好去看官方文档,文档里面有详细的设计方案,我们可以自己进行设计方案的对比,从而找出符合自己实际情况的中间件。
全栈架构社区交流群
「全栈架构社区」建立了读者架构师交流群,大家可以添加小编微信进行加群。欢迎有想法、乐于分享的朋友们一起交流学习。
看完本文有收获?请转发分享给更多人
往期资源: