
点赞功能,用 MySQL 还是 Redis 好 ?
来源:toutiao.com/i6825148720728769028
点赞功能是目前app开发基本的功能
今天我们就来聊聊 点赞、评论、收藏等这些场景的db数据库设计问题,
1. 我们先来看看场景的需求:
显示点赞数量
判断用户是否点过赞,用于去重,必须的判断
显示个人点赞列表,一般在用户中心
显示文章点赞列表
我们先看一下头条和微博的例子

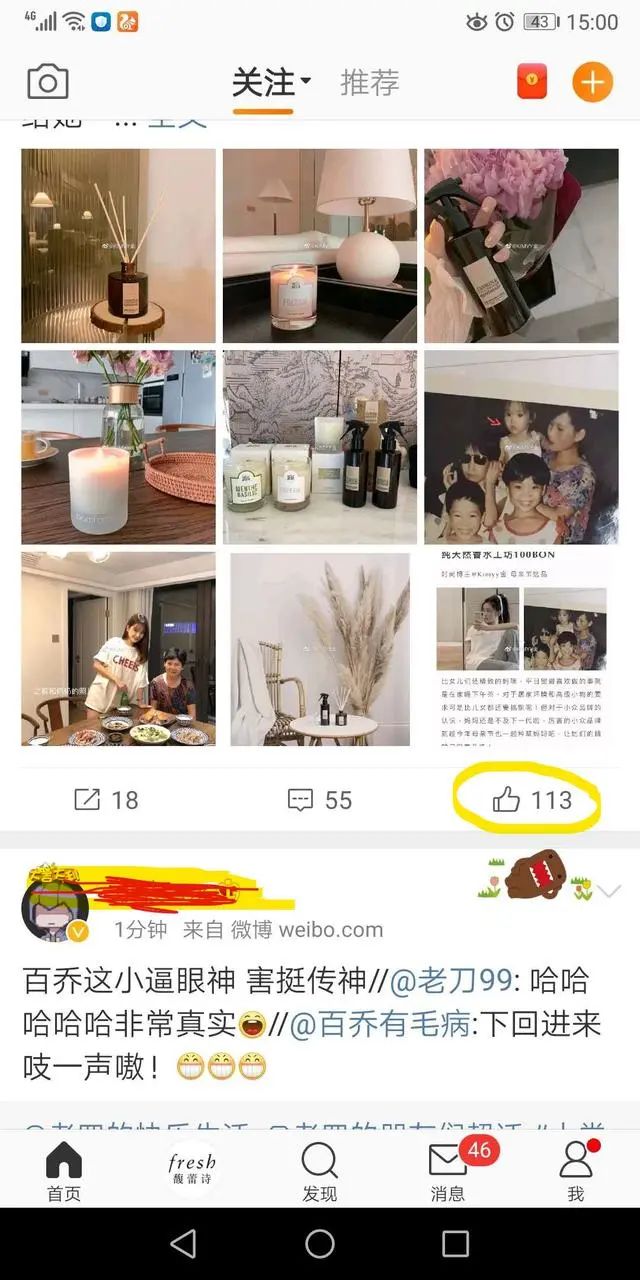
这两个都是具有顶级流量的,后端肯定有复杂的架构,我们今天只谈大众化的方案。
2.1 mysql方案
mysql方案, 随着nosql的流行,大数据的持续热点,但是mysql仍然不可替代,对于大多数的中小项目,低于千万级的数据量,采用mysql分表+cache,是完全可以胜任的,而且稳定性是其他方案无可比拟的:
-- 文章表
create table post {
post_id int(11) NOT NULL AUTO_INCREMENT,
......
star_num int(11) COMMENT '点赞数量'
}
-- 用户表
create table user {
user_id int(11) NOT NULL AUTO_INCREMENT,
......
star_num int(11) COMMENT '点赞数量'
}
-- 点赞表
create table star {
id int(11) NOT NULL AUTO_INCREMENT,
post_id,
user_id,
......
}
常用的查询:
查询用户点赞过的文章 select post_id from star where user_id=?
查询文章的点赞用户 select user_id from star where post_id=?
点赞数量可以通过定时异步统计更新到post和user 表中。
数据量不大的时候,这种设计基本可以满足需求了,
缺点:
数据量大时,一张表在查询时压力巨大,需要分表,而不论用post_id还是user_id来hash分表都与我们的需求有冲突,唯一的办法就是做两个表冗余。这增加了存储空间和维护工作量,还可能有一致性问题。
2.2 redis方案
当数据量达到上亿的量,上cache是必经的阶段,由于点赞这种动作很随意,很多人看到大拇指就想点,所以数据量增长很快,数据规模上来后,对mysql读写都有很大的压力,这时就要考虑memcache、redis进行存储或cache。
为什么一般都选择redis, redis作为流行的nosql,有着丰富的数据类型,可以适应多个场景的需求。
采用redis有两种用途,一种是storage,一种是纯cache,需要+mysql一起。纯cache就是把数据从mysql先写入redis,用户先读cache,miss后再拉取MySQL,同时cache做同步。

多数场景二者是同时使用的,并不冲突。
下面说下redis作为storage的方案:
场景a :显示点赞数量
在点赞的地方,只是显示一个点赞数量,能区分用户是否点赞过,一般用户不关心这个列表,这个场景只要一个数字就可以了,当数量比较大时,一般显示为"7k" ,"10W" 这样。
以文章id为key
//以文章id=888为例
127.0.0.1:6379[2]> set star:tid:888 898 //设置点赞数量
OK
127.0.0.1:6379[2]> incr star:tid:888 //实现数量自增 (integer)
899
场景b:点赞去重,避免重复点赞
要实现这个需求,必须有文章点赞的uid列表,以uid为key场景c:一般在用户中心,可以看到用户自己的点赞列表
这个需求可以使用场景b的数据来实现。

场景d:文章的点赞列表,类似场景b,以文章id为key
//以文章id=888为例
127.0.0.1:6379[2]> sadd star:list:tid:888 123 456 789 //点赞uid列表 (integer)
3
127.0.0.1:6379[2]> sismember star:list:tid:888 456 //判断是否点赞 (integer)
1
点赞的地方,如果点赞过显示红色,没有则显示黑白色,
今日头条是没有地方可以看到点赞列表的,而微博点进去,详情页可以看到点赞列表,但是只会显示最近的几十条,没有分页显示。
如下图,我选了一条热点,拥有众多粉丝的“猪猪”
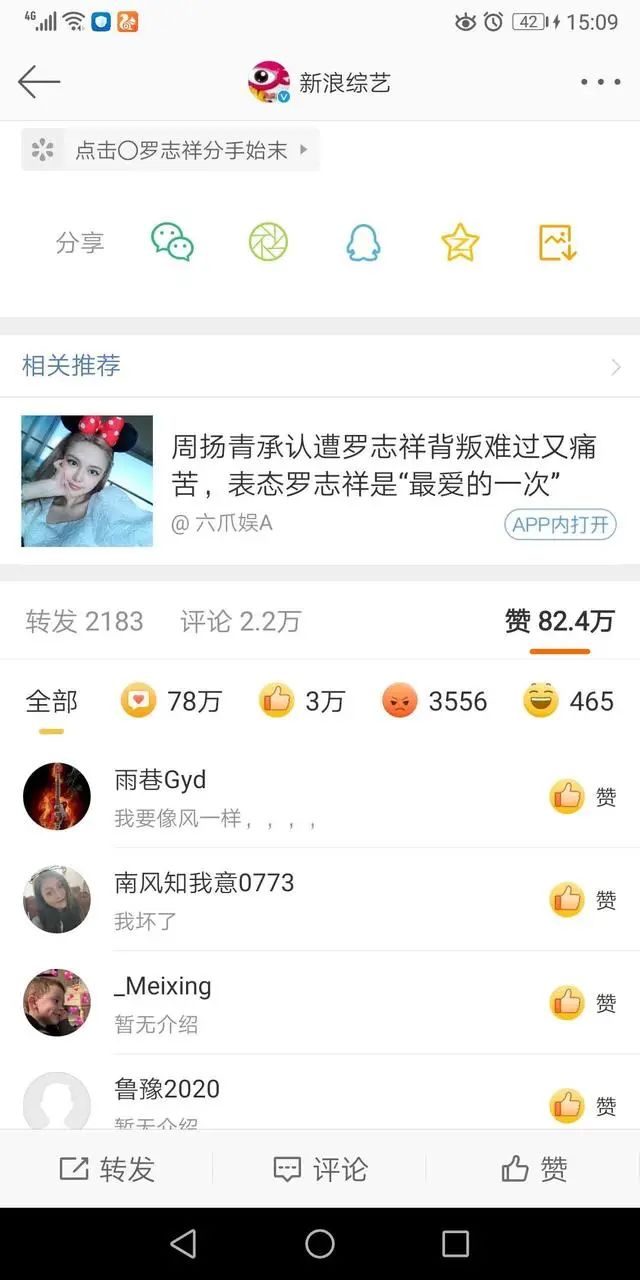
可能有人觉得,点赞列表没人关心,存储又会浪费大量资源,不如不存!但是,这个数据是必须要有的。两点:
去重。点赞数可以不精确,但去重必须是精确的,
另外一个社交产品,用户行为的一点一滴都需要记录,对于后续的用户行为分析和数据挖掘都是有意义的。
上面使用string存储的用户点赞数量,除了string,还可以用hash来存储,对文章id分块,每100个存到一个hash,分别存入hash table,每个文章id为hash的一个key,value存储点赞的用户id,如果点赞用户很多,避免id过多产生性能问题,可以单列出来,用sorted set结构保存,热点的毕竟是少数。
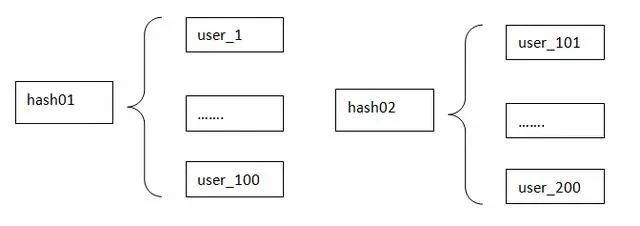
方案优缺点比对
hash:使用了更少的全局key ,节省了内存空间;但是也带来了问题
如何根据文章id路由到对应的hash?
查找一个用户id是在hash还是set?存在不确定性
使用hash虽然节省了空间,但增加了复杂度,如何选择就看个人需求了。
除此之外,你还有其他的方法吗?
3. 数据一致性
redis作为storage使用时,一定要做好数据的持久化,必须开启 rdb 和 aof,这会导致业务只能使用一半的机器内存,所以要做好容量的监控,及时扩容。
另外只要有数据copy,就会有一致性问题,这就是另外一个很重要的话题了。以后有时间再细聊吧!
(完)
长按关注,学习更多
推荐阅读
SQL 已死,但 SQL 将永存!
历史上最简单的一道Java面试题,但无人能通过
为什么 IDEA 比 Eclipse 更好?
值得收藏的 Intellij IDEA 的小技巧
如何写出无法维护的代码2.0版本?
面试 Spring Boot 再也不怕,答案都在这里!
SQL性能优化,太太太太太太太有用了!
面试必问之JVM原理